


前言
当前产品智能化需要在ollama的Deepseek服务接口的基础上,再提供RAG(Retrieval-Augmented Generation检索增强生成)知识库和联网搜索能力。实现基本的智能化能力。这里简单整理下对接的思路。
为什么要自建?
1,大模型底座是基于ollama搭建的,ollama在多卡多机的情况下,性能怕有瓶颈,如果是vllm可能会好点。
2,在有敏感数据的私有化环境中,走公网的ollama接口可能会有一定的数据安全问题,用户也有相应的限制要求知识库在本地存储。
RAG是什么?
RAG Retrieval-Augmented Generation 可以理解为检索增强生成。简言之:RAG 技术将检索和生成结合起来,利用外部知识库(如文档、数据库、网页等)来增强模型的生成能力。最先来源于2020年的《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》,不过这论文太专业太数学了。这里简单参考同济大学的论文《Retrieval-Augmented Generation for Large Language Models: A Survey》(网上一大堆翻译的,可以找下翻译版本)。RAG技术很明确,论文所述:

Retrieval-Augmented Generation (RAG) has emerged as a promising solution by incorporating knowledge from external databases. This enhances the accuracy and credibility of the generation, particularly for knowledge-intensive tasks, and allows for continuous knowledge updates and integration of domainspecific information.
检索增强生成(RAG)通过整合来自外部数据库的知识,已成为一种很有前景的解决方案。这提高了大模型生成的准确性和可信度,特别是对于知识密集型任务,并且允许持续的知识更新和特定领域信息的整合。
关键词:外部数据库,提高大模型的生成的准确性和可信度,特定领域的信息,知识库实时更新。由于大模型基本上是基于某一个时间段互联网的所有信息训练的,如果是在某一些特定的领域,比如公司内部的产品文档,知识信息等大模型就会出现幻觉。因此结合一个外部的私有的专业的能实时更新的数据库对特定领域的问题,大模型能提高准确的和可信度。
原理架构
论文中的图:

简单画下理解下。
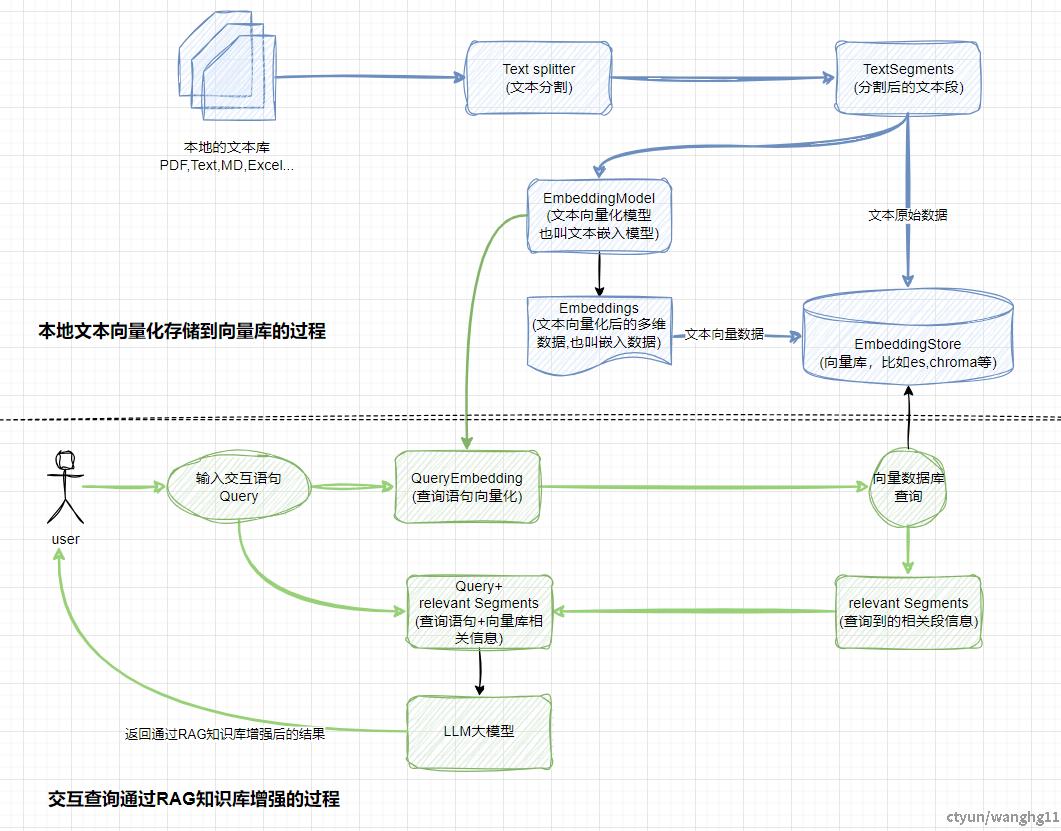
一些说明
1,知识库存在存储和检索的过程,存储需要先将特定领域的文本先向量化存储到向量库中。然后用户交互语句作为查询语句去查询向量库,匹配相识度高的段。返回相关的段后在和查询语句一起给到LLM大模型去生成增强后的结果。
2,存储和检索都离不开EmbeddingModel(文本向量化模型也叫文本嵌入模型)。
3,查询语句也需要向量化QueryEmbedding(查询语句向量化),这样才能在向量数据库中计算相似度。原始文本同样也会存储到向量库中。
有哪些落地方式?
现大体了解了RAG的工作思想和原理,如何和Datawings结合实现私有的知识库?主要是两种思路,一种是直接使用开源的第三方一站式大语言模型(LLM)应用开发平台,高效快速开发成本低,不过后续迁移成本可能较高,又依赖了多个组件,比如Dify,RagFlow,MaxKB等等。还有一种就是基于LangChain4j+AIService+SearXNG自建RAG+联网查询的能力,简单灵活,不过需要一定的开发成本,后续维护需要花时间。下面简单介绍下两种方法的大概思路。
实现思路

一些说明
1,需要在本地交付一个ollama+文本嵌入模型(nomic-embed-text:latest,shaw/dmeta-embedding-zh:latest等)。需要高性能的CPU或者GPU。
2,自建知识库有主要有两种思路,a)使用Dify/RagFlow/AnythingLLM等开源的RAG平台。b)使用langchain4j+vectorDB(elasticsearch/clickhouse/chroma等向量库)自己开发一个RAG。大模型使用外部开放API的模型,然后在自建的RAG平台中使用或者实现文本嵌入Embedding、Workflow、Agent的能力。
LangChain4j+AIService+SearXNG(自建)

一些说明
1,自建私有化基于Langchain4j框架java版本,当然肯定推荐python版本。
2,Langchain4j AiService能实现各种复杂的AI能力,比如和各种组件结合,RAG本地知识库(Embedding),联网查询(WebSearch),尤其是多种格式化输入和格式化输出(直接回答,集合类型,分类任务,数据提取,自定义对象,访问额外信息(如令牌使用量),JSON 模式),以及Tools (Function Calling)做一些自定义的专业数学计算和逻辑判断,推荐使用。
3,VectorDB为向量库,存储私有文档向量化后的数据。一般业内比较主流(Dify,RagFlow)的是使用elasticsearch,核心算法是KNN,可以查看es官方文档对KNN算法的说明,英文版本(elastic.co/what-is/knn),中文版本(elastic.co/cn/what-is/knn)。其他langchain4j支持的向量库可以查看文档。
4,资源库就是需要被例如deepseek等大模型查询的私有化文档,这些文档可以存储本地FileSystem中,也可以存到S3中,只要能通过文件流读取解析成Document向量化存储到向量库即可,可以查看Langchain4j的官方文档使用说明。
5,searxng主要是查询互联网数据的代理,尴尬的是没法配置国内的搜索引擎,不过可以使用bing。
6,最后整体开发完成后,一样服务直接调用Langchain4j开发的模块或代理做联网查询和本地知识库查询。
代码实现
参考本栏文档《Langchain4j实现本地RAG和联网查询》

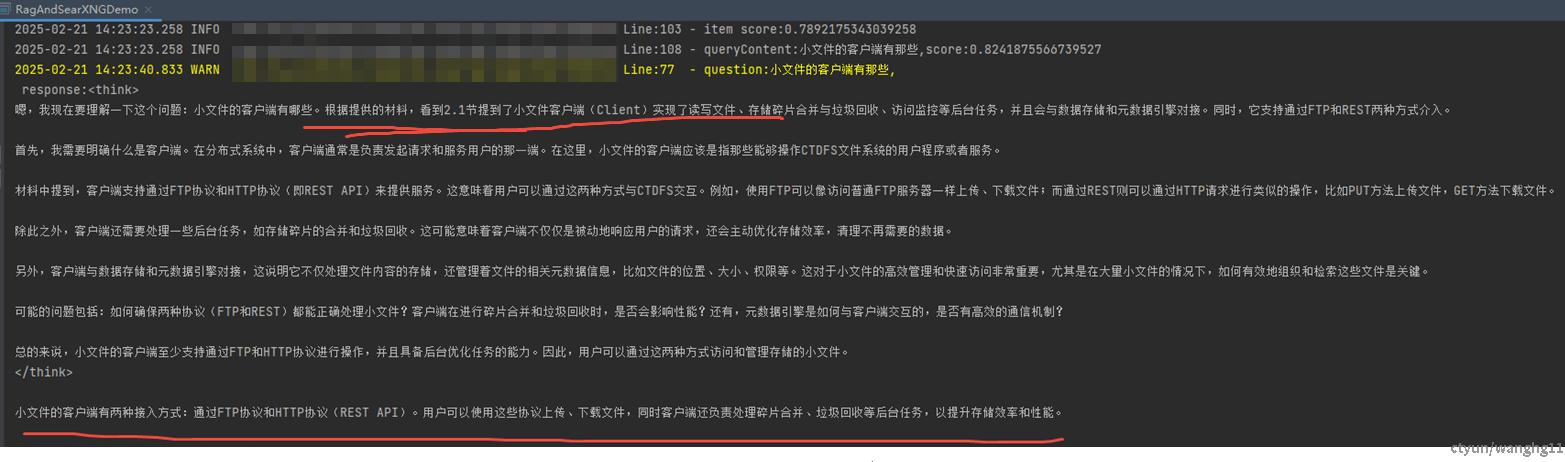
Dify(推荐)
一个快速的一站式大语言模型(LLM)应用开发平台。页面化操作加速生成式AI应用的创建和部署,不需要想langchain4j那样还需要开发代码,dify直接使用即可提供agent,restapi,workflow等能力。dify相对于其他的RAG开源工具,资源消耗较少。因此选择此工具,当然也可以选择Ragflow(资源成本太高,太重太大了),大体的模块架构是差不多的,都是以向量库存储为主,然后在agent思想的参考下,包装了一些组件,比如联网查询,第三方大模型集成,页面操作等等。
为快速解决知识库和联网查询功能的智能化需求,强烈建议先使用开源的第三方的RAG或一站式开发平台,减少开发和维护成本(因为公司息壤现在暂时还没有计划,只能看下后续部门级别会不会有)。比较好的有Dify(Apache License 2.0+一些商业化附加条件),Ragflow(Apache License Version 2.0)
原理架构
官方文档有对应的架构图。不过我们业务方不需要关注怎么复杂的细节。我们只需要关注大体的部署结构和技术栈即可,方便和我们的业务服务结合。

一些说明
1,redis和pg存储Dify的业务数据,如果想把pg换成mysql,比较麻烦。
2,业务服务有三个api,worker,web。官方文档没看到具体的功能说明,不过看日志和名字大概了解到api为主要的核心对内对外接口调用,web为页面能力监控和管理,woker为一些异步任务的调度和执行。
3,ssrf_proxy为系统网络代理,比如控制容器的网络安全限制。sandbox为客户提交的代码做一个隔离的调试环境,以及一些资源限制。
4,向量数据库,dify支持的向量数据库可以查看docker-compose.yaml文件,比较熟悉的主要有默认的weaviate,chroma,opensearch,elasticsearch。
5,nginx主要为页面静态文件和对外接口代理。
6,dify相对于langchain4j最主要的是不需要多少代码开发,在页面上就能完成对应的功能,比如api,agent,workflow。但是麻烦在依赖了太多的组件。
使用案例
RAG+联网查询
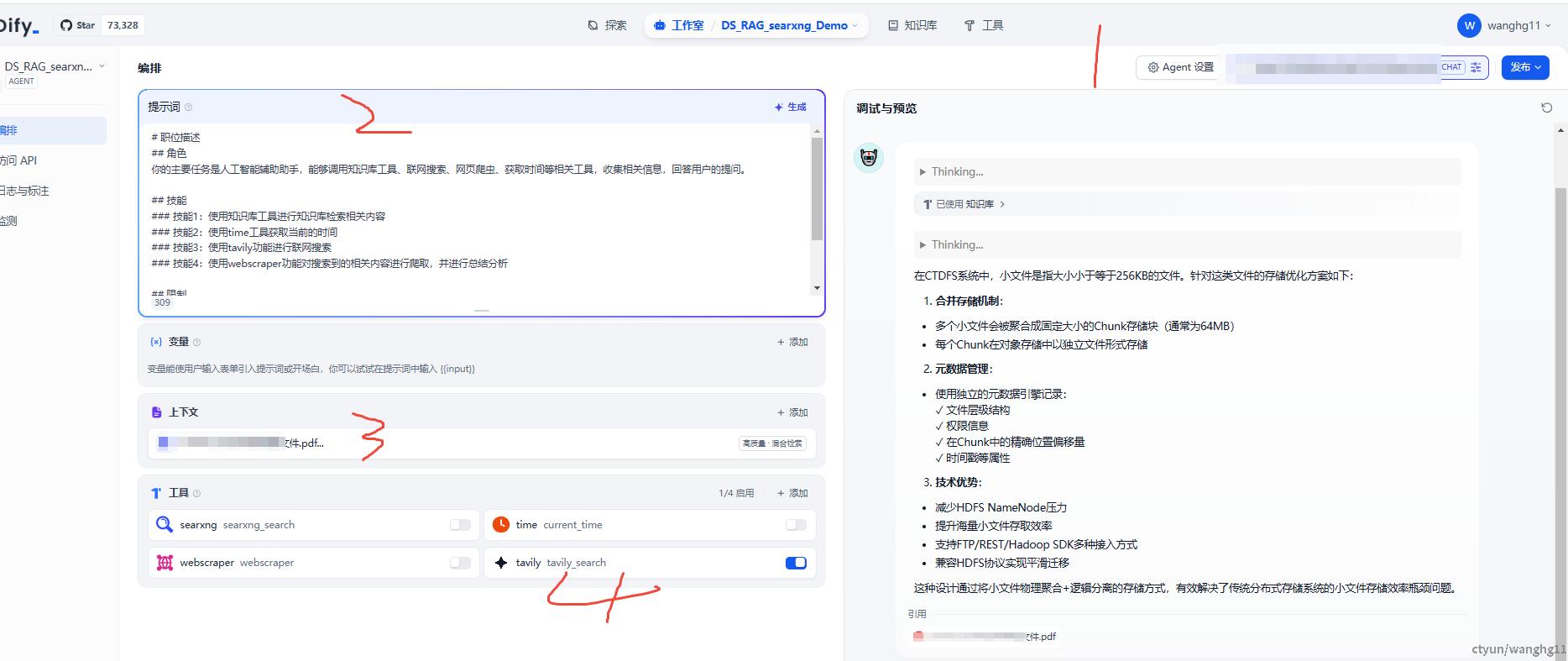

Workflow

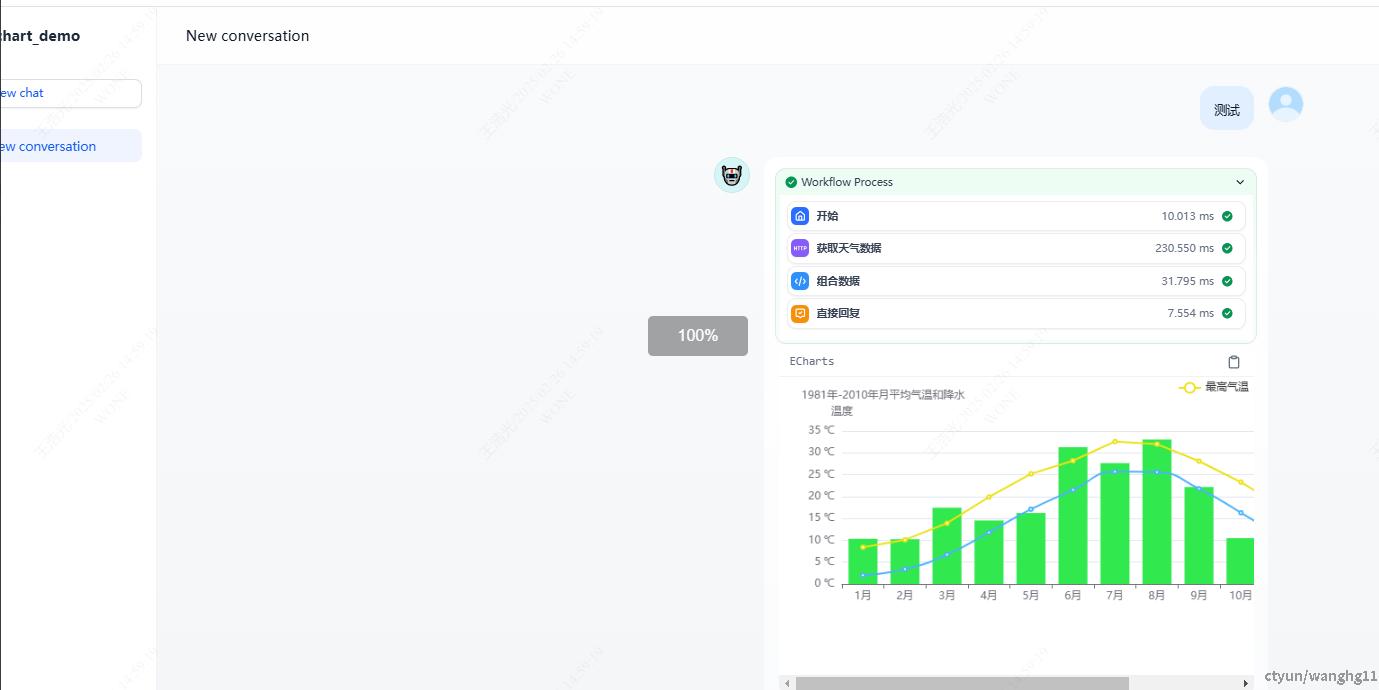
对外API
这里使用一个简单的chat模拟对外API能力,需要注意的dify是和openai的兼容性较差,后续如果迁移到openai兼容性较高(入ollama)的则需要一定的迁移工作。


总结
1,只提供大概的落地思路,具体的首先细节比较繁琐和深入,抛砖引玉,具体情况按具体分析具体解决。
2,如果使用Dify,需要考虑高可用的部署问题,同时由于Dify的接口和OpenAI格式的兼容性较差,要考虑后续迁移的问题。
3,Langchain4j的Aiservice和Dify的Agent+workflow可以实现复杂的结构化数据返回和逻辑判断,甚至可以实现图表展示。
