原文标题:PLB: Congestion Signals are Simple and Effective for Network Load Balancing
这篇论文由谷歌公司发布于2022年SIGCOMM会议,主要介绍了一种host侧的链路负载均衡设计——PLB(Protective Load Balancing),并报道了Data Center中,链路负责不均衡的首次实践解决方案及相关数据。
所提出的PLB设计主要基于TCP/Pony Express传输协议,并结合了ECMP(Equal-Cost Multi-Path)/WCMP(Weighted ECMP)技术,旨在减少网络热点(hotspots)。发生拥塞时,PLB优先在设备产生空闲期后重新规划链接路径,从而改变发生拥塞的路径,使得数据包乱序最小化。该方法主要通过改变数据包的IPv6 Flow Label来重新规划连接,该改动会被交换机作为ECMP/WCMP的一部分处理,因此与ECMP/WCMP算法有很强的兼容性。
PLB的工作原理是通过跨主机的路径调整,减少网络中的热点,并降低远程过程调用(Remote Procedure Call—RPC)的延迟。该设计在Google的TCP和Pony Express流量中广泛应用。由于PLB仅需要小幅度的传输协议修改和交换机配置更改,且向后兼容,因此可以与其他网络拥塞算法并行部署。
一.ECMP存在的问题:
传统的ECMP(Equal-Cost Multi-Path)存在的一些问题可以通过以下几个关键点进行分析:
1. 流量不均衡(Load Imbalance)
ECMP和它的加权版本WCMP(Weighted ECMP)是数据中心网络中负载均衡的关键技术,它们通过将每个TCP连接(即4元组)随机映射到不同的交换机输出端口来分配流量。这种方式假设网络中有足够多的流量,以致每个链路上负载大致均衡。然而,实际情况往往并非如此,特别是在重尾(heavy-tailed)工作负载的情况下。
- 重尾流量:大部分网络流量是由少数几个较大流(例如大于64KB的RPC)承担的,而绝大多数小的RPC虽然数量很多,但它们传输的数据量相对较少。例如,在谷歌的数据中心中,尽管大部分RPC(超过90%)小于64KB,但这些RPC所占的流量不到四分之一,而大于64KB的少数RPC却承担了超过三分之二的流量。
- ECMP的不足:ECMP通过简单的随机算法将流量分配到不同链路,但它忽视了流量大小的差异。由于大部分流量由少数大流量承载,而这些流量的分配仍然是随机的,结果导致了网络中的一些链路(例如交换机的某些上行链路)过载,而其他链路则未被充分利用。这种情况产生了严重的负载不均衡(Load Imbalance),降低了网络的整体效能。
2. Binomial 分布和流量分配
ECMP假设流量在多个链路之间是均匀分布的,但在实际使用中,尤其是在有重尾流量的场景下,流量分配往往遵循二项分布(Binomial distribution)。即使流量的数量很多,少数大流量的存在会导致链路间的负载分布非常不均匀,造成严重的“热点”(hotspots)。
- 在Google数据中心的实验中,当ToR交换机的上行链路利用率超过70%时,负载不均衡度(LI)达到显著值。即使在这些链路上,负载的分布也极为不均匀,有些链路的负载要明显高于其他链路,这会导致网络的拥塞和性能波动。
3. 高负载下的拥塞和丢包
负载不均衡的一个直接后果是,在网络负载高的情况下,某些交换机的上行链路(尤其是ToR交换机)会出现过度拥塞。这种不均匀的流量分配会导致:
- 队列延迟(Queuing delay):链路过载会导致队列长度增加,从而增加延迟。
- 数据包丢失(Packet drops):超载链路上丢包现象更为严重,因为当链路无法处理更多的流量时,会丢弃一些数据包,这影响了整体网络的性能和可靠性。
4. ECMP的局限性分析
ECMP本身并不能有效地应对重尾工作负载带来的不均衡问题。由于这些工作负载通常存在极不平衡的流量大小分布,传统的ECMP算法会导致流量在不同链路之间分配不均,某些链路承载了过多的大流量,形成了“热点”,这导致了网络的资源没有得到充分利用,甚至可能出现部分链路的过度负载。
为了解决网络中由于热点引起的拥塞和性能问题,要求解决方案具有以下几个特点:
(1). 待解决的问题:
- 热点:指的是交换机输出端口发生拥塞,导致显著的排队和丢包。在数据中心网络中,热点往往导致网络流量的集中,从而影响性能。
- 目标:问题的核心是如何分配流量到可用的路径,以最小化网络中热点的流量。这意味着不需要在所有位置保持链路利用率平衡,只需要在拥塞点进行优化,最终目标是改善应用性能。
(2). 多样性和异构性:
- 设备和协议的多样性:Google的网络架构由不同厂商和多个版本的交换机组成,因此,网络的设计和配置在高层次上可能相似,但细节上差异较大。这种异构性要求解决方案能够适应不同设备、协议和传输方式。
- 传输协议的多样性:不同的主机可能使用不同的传输协议和拥塞控制方式,数据中心中的流量来源也各不相同,这使得解决方案必须能够处理各种不同的流量模式。
- 应用程序的多样性:数据中心内运行的应用程序生成各种不同类型的工作负载,这些负载会快速变化,这就要求解决方案能够应对这些变化。
(3). 渐进部署(Incremental Deployability):
- 现有硬件的适应性:解决方案需要考虑到现有硬件的兼容性,尤其是交换机。由于交换机更换周期较长,完全依赖新硬件的解决方案不可行。换句话说,解决方案不应要求完全替换现有交换机,而应通过软件配置或其他方式在现有硬件上实现。
- 主机软件的灵活性:主机的软件升级相比硬件更为灵活,因此,解决方案可以专注于主机软件的改进,以便能在较短时间内实现增量的收益。
- 协议兼容性:新的协议迁移可能需要很多年才能完成,因此,解决方案应与现有的传输协议兼容,而不必依赖于协议的重大改变。
(4). 渐进式收益:
- 逐步部署:由于数据中心的规模庞大,无法一次性升级整个数据中心,解决方案需要支持渐进式的部署。每次部署都应该能带来一定的收益,而不必等到完全部署后才看到效果。这意味着解决方案必须能够在分阶段部署时逐步改善网络性能。
(5). 广泛的适用性:
- 大规模提供商的普遍需求:这些要求并不仅仅是Google面临的问题,其他大规模云服务提供商也面临类似的挑战。所有大型服务提供商需要解决网络拥塞和流量分配不均的问题。
- 简单而通用的解决方案:一种简单且通用的解决方案具有强大的价值,因为它能够减少成本,同时具有广泛的适用性。简化的解决方案不仅能解决当前问题,而且能适应各种不同的网络环境。
5. PLB解决方案
PLB(Protective Load Balancing)设计通过与ECMP协同工作,利用IPv6 Flow Label重新分配流量来减少热点现象。它通过在检测到拥塞时改变连接的路径,避免了ECMP中由于随机流量分配造成的热点问题。
- PLB将拥塞检测和路径重寻分配相结合,利用流量的空闲期进行路径调整,从而减少了负载不均衡,降低了拥塞和丢包的风险。
- 通过这种方式,PLB显著减少了Google数据中心中高负载ToR交换机的负载不均衡度,从而降低了队列延迟和丢包率,提升了整体网络的性能。
传统的ECMP存在流量分配不均的问题,特别是在重尾分布的工作负载下,ECMP会忽视流量的大小差异,导致网络中的一些链路负载过重,形成热点,进而影响性能。而PLB通过结合拥塞检测与路径重选,可以更智能地平衡流量,解决这一问题,从而提高网络的可靠性和效率。
实施方法:
PLB-TCP(Protective Load Balancing for TCP)是一种结合了负载均衡和拥塞控制的技术,旨在提高数据中心中基于TCP协议的流量管理效率,尤其是在高负载的情况下。以下是PLB-TCP的主要技术要点:
1. 设计思路
PLB-TCP的设计是在主机端(即数据发送方)进行的,与传统的ECMP(Equal-Cost Multi-Path)路由技术互补。PLB技术通过在IPv6流量中引入Flow Label,除了使用传统的四元组(源IP、目标IP、源端口、目标端口)进行哈希之外,增加了Flow Label来进一步细化流量分配,减少网络热点问题。PLB的核心目标是通过路径重寻(re-pathing)来减少网络拥塞,从而提高网络的稳定性和性能。
2. 算法构成:拥塞检测与路径重寻(re-pathing)
- 拥塞检测:PLB通过利用传输层(TCP)的拥塞信号来检测连接是否发生了拥塞。这是通过ECN(Explicit Congestion Notification)标记来实现的。当交换机检测到队列超过阈值时,会在数据包上设置CE(Congestion Experienced)标记,接收方会将该标记返回给发送方。发送方根据ACK包中的CE标记,判断连接是否发生了拥塞,并在经过连续的M轮拥塞后将流量标记为拥塞。
- 路径重寻:一旦检测到拥塞,PLB会通过给数据包分配新的流量标签(Flow Label)来将流量从当前拥塞的路径重新分配到其他可用路径。通过这种方法,PLB将会把那些导致网络热点的流量分散到多个路径上,从而减少冲突,提高网络的带宽利用率。
3. PLB具体实现
以TCP条件下的PLB部署为例,PLB-TCP与谷歌的BBRv2(Bottleneck Bandwidth and RTT)拥塞控制协议兼容,且没有对BBRv2做任何特别修改。整个PLB-TCP的实现代码非常简洁,约50行代码,在Linux内核的TCP堆栈中完成。
PLB算法伪代码表示如下:

(1).拥塞检测(Congestion Detection):
- PLB-TCP通过类似DCTCP(Data Center TCP)的启发式算法来判断连接是否处于拥塞状态。发送方每次接收到ACK时,都会计算CE标记的数据包占比,如果大于某个阈值(K),则认为当前轮次出现了拥塞。在连续的M轮拥塞后,流量被标记为拥塞。
(2).延迟和包乱序的处理:
- 减少包乱序:为了避免由于路径重寻而导致包的乱序,PLB采用了延迟路径重寻的策略,尤其是在流量恢复(如空闲后重新开始时)。大多数RPC请求的大小较小,且通常会在空闲时发送,因此PLB可以在流量恢复时选择适当的路径,而不会导致乱序。
- 对于大流量RPC(大型请求)则在连续拥塞轮次后强制进行路径切换,这样可以避免长期积压导致的网络拥塞。
(3).小型RPC的流量调度:
- 数据中心的流量通常呈现重尾分布(heavy-tailed),大多数RPC请求较小(通常小于64KB),但它们构成了少数流量,大部分的流量由较大的RPC请求(如超过64KB的)占据。
- PLB会通过利用空闲连接,尽量将小型RPC流量从繁忙的路径中迁移出去,从而避免受到大流量RPC的影响,减少尾部延迟。
(4).连接失效时的处理:
- PLB的流量路径重寻是基于Markov过程的,即新的路径选择与当前路径的拥塞情况相关。新的路径是否会发生拥塞,取决于路径的带宽和当前网络负载的状态。
4. PLB-TCP的关键优势
- 增量部署:PLB是向后兼容的,可以在两端支持ECN的情况下逐步启用,而不需要大规模的网络或传输协议修改。这使得PLB非常适合在现有的TCP协议栈上进行增量部署。
- 网络可靠性和低延迟:通过减少流量集中在少数路径上,PLB显著降低了网络拥塞,提高了网络的可靠性。同时,它通过降低网络延迟,优化了小型RPC的传输,减少了尾部延迟(Tail Latency)。
- 与现有TCP协议兼容:PLB与现有的TCP协议栈兼容,且可以与不同的拥塞控制算法(如BBRv2)一起使用,而无需对这些协议进行重大修改。
5. 处理异常情况
- 链路故障:PLB还会在重传超时(RTO)发生时触发路径重寻。RTO通常发生在TCP反馈回路中断时,比如链路故障或小型数据包在拥塞严重时丢失。通过PLB的路径重寻机制,可以在这种情况下恢复数据传输。
PLB-TCP是一种高效的拥塞控制和流量管理方案,结合了流量负载均衡、拥塞检测和路径重选技术,能够在不大幅度修改现有协议栈的情况下显著提高TCP流量的网络性能。PLB通过优化流量的路径分配,减少热点,优化小型RPC的延迟,并在网络发生拥塞时快速调整路径,确保网络在高负载情况下的稳定性和低延迟。
PLB与拥塞控制算法的交互
PLB(Protective Load Balancing)与其他拥塞控制算法的交互方式可以通过以下几个关键技术点来理解:
1. 时序分离:PLB与拥塞控制的并行工作
PLB与传统的拥塞控制模块(如TCP的BBRv2等)可以并行工作,而不会产生不利的交互。为了避免二者之间的冲突,PLB采取了时序分离的策略:
- 拥塞检测的延迟:当一个流量发生拥塞时,PLB不会立即进行路径重选,而是会等待几个往返时延(Round Trip Time,RTT)。这段等待时间允许拥塞控制机制(如BBRv2)有足够的时间来响应暂时的拥塞问题。
- 空闲时才路径重寻:PLB通常在流量恢复时才进行路径重选,特别是当连接空闲后重新开始时,这时拥塞状态往往是过时的,重新探测可以获取新的状态。通过这种策略,PLB避免了频繁地干扰现有的拥塞控制机制,确保了二者的协同工作。
2. 避免过度拥塞的干扰
PLB并不希望长时间忍受重度拥塞。若PLB过于频繁地进行路径重选,可能导致拥塞控制机制放慢流速,从而降低性能。因此,PLB引入了适当的参数(如算法中的K, M, N),并通过实验找到了一个平衡点(例如,K=0.5, M=3, N=12),确保在不同工作负载下,既能加速小RPC的路径重选,又不会过快影响大RPC的性能。
3. 链路故障处理
在链路故障的情况下,TCP连接可能会发生重传超时(RTO),这时PLB会进行路径重选,将流量从失败的链路转移到其他链路。然而,如果网络的总容量减少,可能会导致更多的流量出现拥塞,这时需要防止路径过于频繁地进行重选,避免再次将流量导向失败的链路。
- 抑制重选:当发生RTO时,PLB会暂停PLBDetection模块,延迟路径重寻的操作。延迟时间会根据预期的链路恢复时间来设定,以避免在链路恢复过程中再次进行路径切换。这个延迟时间是随机的,通常为预期恢复时间的1到2倍,以避免同步问题。
4. PLB作为热扩散过程(Thermal Diffusion)
PLB的负载均衡行为可以通过热扩散过程来类比。当网络中的流量集中在少数路径上时,PLB会通过路径重选,将流量分散到更多的路径上,从而减少不均衡的负载。这种行为类似于热扩散中的“温度”通过扩散来平衡各处的温度。
- 高不均衡时的路径重选:当流量在某些路径上集中(即热点过重),PLB会通过路径重选将流量分散,减少热点。这样,整个网络的负载会更均匀,从而达到全网的负载平衡。
- 低不均衡时的稳定状态:当负载已经相对均衡时,PLB会减少路径重选,系统会在偶然的情况下保持较低的不均衡状态。这与热扩散中的“平衡”状态类似,即流量的分布趋向于稳定,不再频繁变动。
5. PLB与拥塞控制的联合优化
- 拥塞控制与PLB的协同工作:通过利用拥塞控制机制的反馈信息(如ECN标记),PLB能够有效地将流量分散到多个路径上,从而减少拥塞的影响。同时,PLB的路径重选并不会频繁干扰现有的拥塞控制机制,而是基于网络的实时状态进行合理的调整。
- 局部控制与全局负载平衡:PLB的局部路径选择与每个主机的拥塞控制行为联合起来,最终能够实现全局的负载平衡。与传统的网络负载均衡算法不同,PLB通过分散热点流量,逐步将网络负载从过度集中的状态向全网均衡的状态迁移。
6. PLB的性能和效果
- 反应速度:由于PLB能够在接近实时的时间尺度上反应,利用传输层的信号快速探测拥塞并调整路径,因此它能在高速变化的网络负载中迅速恢复网络平衡。
- 适应不同负载模式:PLB在面对高连接变化率和重尾分布的工作负载时,能够有效地减少热点现象并提高性能,尤其是在小型RPC请求的延迟优化方面,具有显著优势。
PLB通过与拥塞控制机制的协作,避免了过度干扰现有的拥塞控制策略,确保了数据中心网络在拥塞条件下的平稳运行。PLB通过时序分离、路径重选、避免过度路径切换等策略,不仅提高了网络的负载均衡,还有效降低了尾部延迟,特别是在小型RPC的传输中,能够显著提升性能。通过这种方式,PLB实现了全网负载的优化,同时与现有拥塞控制机制共同作用,确保了稳定且高效的网络性能。
结果分析:
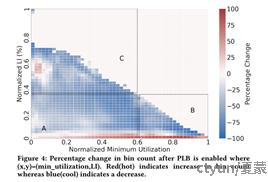
PLB的部署带来了显著的优化:在Google数据中心,高负载ToR(Top-of-Rack)上行链路的中位负载不平衡降低了60%,
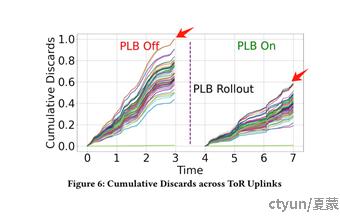
数据包丢失减少了33%,
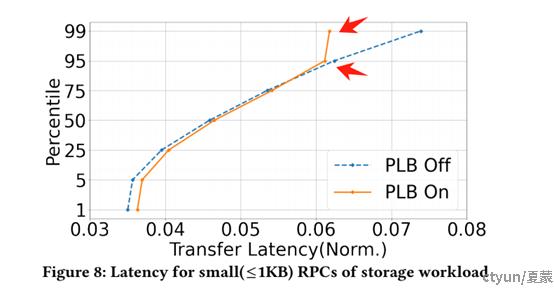
小型RPC的尾延迟(99百分位)下降了20%。