


名词解释
在数据库中,merge into用于将源表的数据合并到目标表中,它支持条件更新、插入以及删除操作,使得数据同步变得更加高效和简洁。
CN(Coordinator Node): 协调者节点负责处理客户端请求,并且协调数据的分布、事务管理和查询执行。当客户端发送一个查询或事务请求时,CN会解析这个请求。
DN(Database Node):数据节点是实际存储数据的地方。每个DN负责维护一部分数据,并且执行CN分配的任务,比如读取数据、更新数据、执行计算等。
技术背景
在数据库中,merge into用于将源表中的数据合并到目标表中,一般情况下是根据连接条件,如果目标表的行和源表中的某行进行连接,则用源表的改行对目标表进行更新操作;如果目标表中的行和源表中的所有行均不能连接,则将源表中的行插入到目标中。目前数据库的内部实现方案是:由于源表中每条数据或者用来更新目标表,或者用来插入到目标表中,因此在执行计划中底层源表和目标表进行左连接,上层dml算子的根据左连接的结构进行判断,如果左连接结果的右侧不是NULL,说明右侧的目标表行可以满足连接条件,则根据源表数据进行更新操作;如果左连接结果的右侧为NULL,说明源表的这条数据不能和目标表进行连接,则将这条源表数据进行插入操作。
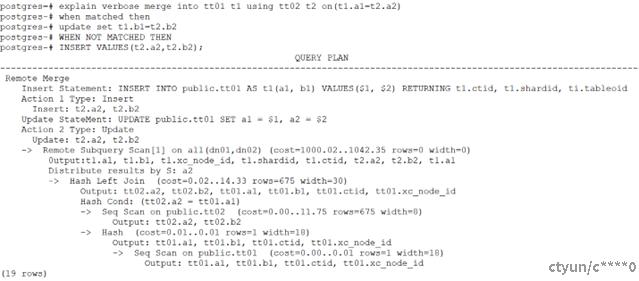
对于分布式数据库,由于数据分布在不同的DN上,源表和目标表在进行左连接前,数据要根据连接条件进行重分布,做完左连接后,左连接的结果中源表的数据是全部输出,和源表不能关联的右侧目标表是补NULL的,因此不能以目标表的分布列作为分布键对数据进行重分布(左连接的结果中目标表存在空行),因此数据不能根据目标表重分布到对应的DN上,因此不能在DN上做merge into操作。对于分布式数据库,目前常用的技术是将连接后的数据发送到CN上,然后CN在将数据发送的对应的DN上做merge into操作,而这种执行计划的效率是非常的低的,大大降低了merge into的性能。
Merge into查询计划
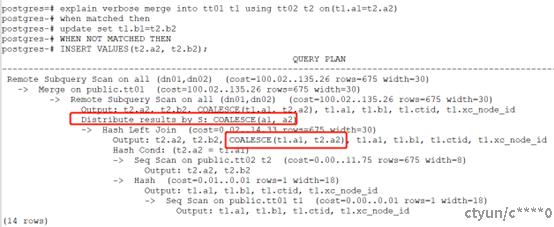
上述问题中不能直接在DN上做merge into关键是底层算子左连接结果中目标表部分存在NULL,因此在DN上不能通过目标表的分布列将数据发送到正确的DN节点上,导致不能直接在DN做merge into。对于merge into,源表中的数据能与目标表关联做更新操作,源表中的数据不能与目标表关联做插入操作,因此在底层算子左连接结果中目标表为NULL的行,对应的源数据行(或将要插入的源数据)要插入到目标表中;底层算子左连接结果中目标表不为NULL的行,对应的源数据行用来更新目标表。基于此,对于左连接的结果中目标表部分不为NULL时,根据目标表的分布列对数据进行重分布,在对应的DN上做数据更新操作;对于左连接的结果中目标表为NULL时,根据merge into中要插入的数据(一般是源表的数据)进行重分布,然后在对应的DN上做数据插入操作。可以在底层的左连接算子中增加一列COALESCE(tt01.a1, expr1),其中tt01为merge into的目标表,a1是其分布列,expr1是merge into中插入操作中目标表分布列中将要插入的数据。COALESCE(tt01.a1, expr1)函数的功能是如果tt01.a1不为空,则结果为tt01.a1,tt01.a1为空,则结果为expr1。然后将COALESCE(tt01.a1, expr1)函数结果作为分布列对左连接的结果做重分布,这样不论merge into做更新还是插入动作,数据都可以发送到正确的DN上,可以直接在DN上做merge into操作。
merge into的常用写法如下:

原始的执行计划中,数据要先到CN上,然后CN在发送到对应的DN上做merge into性能比较很差,执行计划如下:
新的执行计划中,数据不用发送到CN上,merge into直接在DN上进行,性能会好很多。执行计划如下:
总结
新的Merge into查询方法主要在merge into底层的左连接的输出中添加一个表达式COALESCE(目标表.分布列, 目标表分布列将要插入的表达式),得到左连接的结果后可以以COALESCE的结果作为数据分布列,可以将数据分布到正确的DN上,可以直接在DN上做merge into操作。相比之前的方案,所有的数据不用先发送到CN上重新下发到DN上做merge into操作,性能有很大的提升。
