


Bridge 是一个虚拟网桥,工作在二层,功能类似于传统的物理交换机。然后也通过 Bridge 完成了容器间网络打通和容器访问外部网络的实验,但是由于篇幅有限,对于 Bridge 内具体的数据包是如何流转的并没有一个直观的认识,所以本文我们再对 Bridge 进行一点扩展实验,观察其工作方式。
实验环境概览
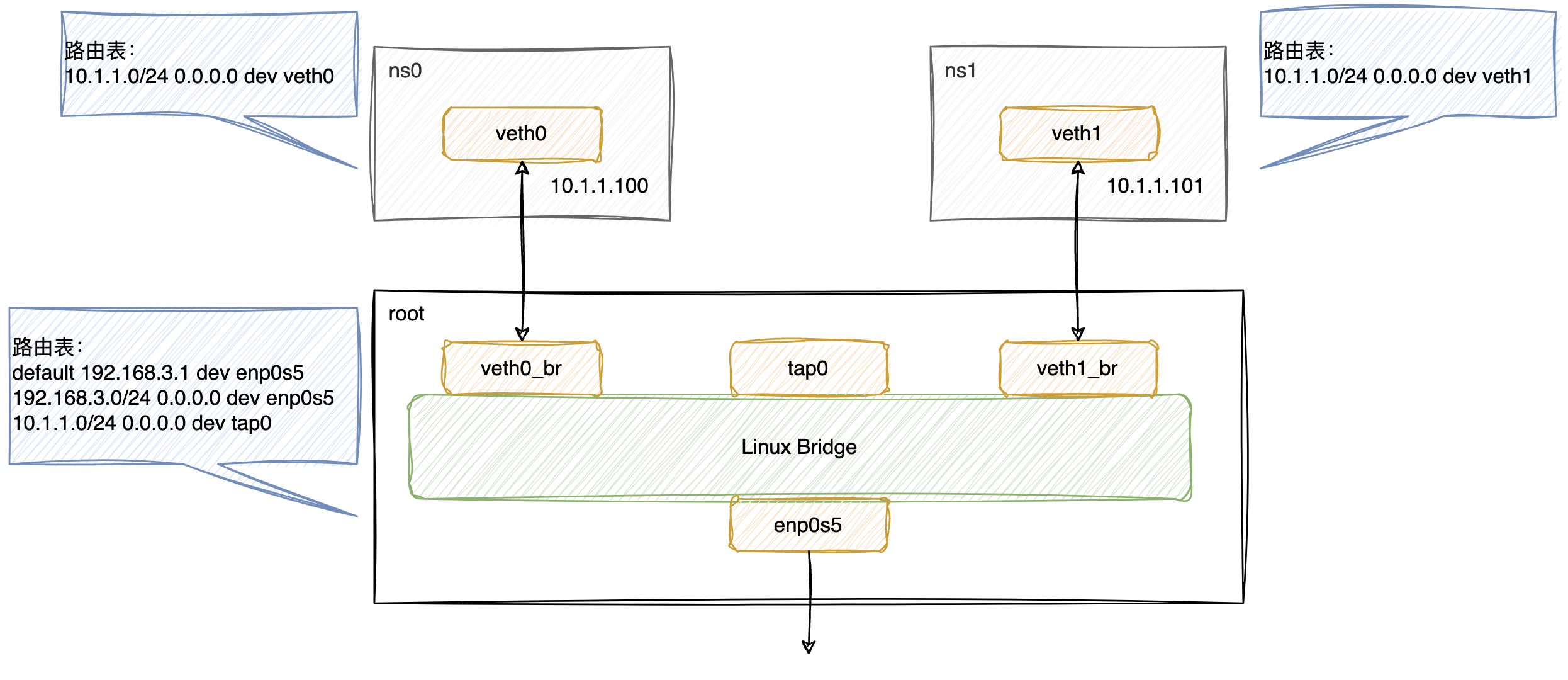
首先介绍一下实验环境,中间主要有三个 namespace 组成:
root:系统默认 namespace,里面包含物理网卡enp0s5,和 Linux Bridgebr0;ns0:用于模拟容器网络,通过 veth pairveth0和veth0_br与root的网络打通;ns1:用于模拟容器网络,通过 veth pairveth1和veth1_br与root的网络打通;
在本实验中,br0上会陆续接入veth0_br、veth1_br、tap0以及enp0s5设备,用于在二层打通各 namespace 间的网络以及物理网络。
我们在之前介绍 TUN/TAP 设备的文章中有讲到,TAP 工作在二层,可以接收到以太网帧,所以我们创建了
tap0设备,在它绑定的用户程序进程中仅打印接收到的数据包,不做任何回包。这里仅仅是使用tap0的特性来观察br0的运作是否符合预期。
观察容器间网络
最基础的设备是网桥,这里我们先创建网桥:
$ brctl addbr br0
$ ip link set br0 up
先来创建namespace ns0,新增 veth pair 设备veth0和veth0_br,其中veth0这端放入ns0:
$ ip netns add ns0
$ ip link add veth0 type veth peer name veth0_br
$ ip link set dev veth0 netns ns0
$ ip netns exec ns0 ip addr add 10.1.1.100/24 dev veth0
$ ip netns exec ns0 ip link set veth0 up
$ ip link set veth0_br up
veth pair 设置好后,我们将veth0_br插入网桥br0:
$ brctl addif br0 veth0_br
我们知道网桥是有 mac table 的,它会学习并记录 mac 与 port 的关联关系,所以这里我们也查看一下br0的 mac table。
可以看到veth0_br的 mac 已经记录在表中:
# `veth0_br`的 mac 地址是:ce:85:09:8a:b1:7b
$ ip a
...
5: veth0_br@if6: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master br0 state UP group default qlen 1000
link/ether ce:85:09:8a:b1:7b brd ff:ff:ff:ff:ff:ff link-netns ns0
inet6 fe80::cc85:9ff:fe8a:b17b/64 scope link
valid_lft forever preferred_lft forever
$ brctl showmacs br0
port no mac addr is local? ageing timer
1 ce:85:09:8a:b1:7b yes 0.00
1 ce:85:09:8a:b1:7b yes 0.00
veth0_br的 mac 对应 port 1,这是符合预期的。但同时我们也知道,在 port 1 除了veth0_br外,还应该有逻辑上与它直接连接的veth0设备,只是此时veth0还没有任何请求发起,所以br0`不知道它的存在。
我们在ns0发起一个 ping 请求,虽然我们知道不会通,但是内核仍然会发起 arp 广播,这个 arp 请求在ns0中会发送到veth0网卡,同时立刻被投递到插入了br0的veth0_br,br0就会知道 port 1 还有另外一个设备:
# shell-0
$ ip netns exec ns0 ping 10.1.1.200
# shell-1
# `veth0`的 mac 地址是:da:ff:de:36:22:8e
$ ip netns exec ns0 ip a
...
9: veth0@if8: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether da:ff:de:36:22:8e brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.1.1.100/24 scope global veth0
valid_lft forever preferred_lft forever
inet6 fe80::d8ff:deff:fe36:228e/64 scope link
valid_lft forever preferred_lft forever
$ brctl showmacs br0
port no mac addr is local? ageing timer
1 ce:85:09:8a:b1:7b yes 0.00
1 ce:85:09:8a:b1:7b yes 0.00
1 da:ff:de:36:22:8e no 3.64
此时 port 1 就能看到 veth pair 的两个设备的 mac 地址,其中 is local 为 no 的那个 mac,就是veth0设备的地址,代表这个设备并未与br0直接相连。
对于ns1的 veth pair,也用同样的方法创建:
$ ip netns add ns1
$ ip link add veth1 type veth peer name veth1_br
$ ip link set dev veth1 netns ns1
$ ip netns exec ns1 ip addr add 10.1.1.101/24 dev veth1
$ ip netns exec ns1 ip link set veth1 up
$ ip link set veth1_br up
$ brctl addif br0 veth1_br
此时查看 mac 表,可知 port 2 已经插入 veth pair 的设备:
$ brctl showmacs br0
port no mac addr is local? ageing timer
2 82:c4:73:f0:75:df yes 0.00
2 82:c4:73:f0:75:df yes 0.00
2 a2:60:3b:b0:83:44 no 26.80
1 ce:85:09:8a:b1:7b yes 0.00
1 ce:85:09:8a:b1:7b yes 0.00
1 da:ff:de:36:22:8e no 72.11
最后,我们再启动一个 TAP 设备tap0,并加入br0,用于观察二层的表现:
# shell-0
$ ./tap
# shell-1
$ ip a
...
13: tap0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel master br0 state UNKNOWN group default qlen 1000
link/ether 56:64:86:8b:a6:0b brd ff:ff:ff:ff:ff:ff
inet 10.1.1.200/24 scope global tap0
valid_lft forever preferred_lft forever
inet6 fe80::c0e4:58ff:fe76:3c7f/64 scope link
valid_lft forever preferred_lft forever
$ brctl addif br0 tap0
$ brctl showmacs br0
port no mac addr is local? ageing timer
3 56:64:86:8b:a6:0b yes 0.00
3 56:64:86:8b:a6:0b yes 0.00
2 82:c4:73:f0:75:df yes 0.00
2 82:c4:73:f0:75:df yes 0.00
2 a2:60:3b:b0:83:44 no 26.80
1 ce:85:09:8a:b1:7b yes 0.00
1 ce:85:09:8a:b1:7b yes 0.00
1 da:ff:de:36:22:8e no 72.11
好,现在环境搭建完成,我们尝试在ns0 ping ns1的设备。首先,目前ns0中 arp 表项并没有任何数据:
$ ip netns exec ns0 arp -a
empty
然后执行 ping 的动作:
root@ubuntu-linux-22-04-02-desktop:~# ip netns exec ns0 ping -c1 10.1.1.101
PING 10.1.1.101 (10.1.1.101) 56(84) bytes of data.
64 bytes from 10.1.1.101: icmp_seq=1 ttl=64 time=0.148 ms
--- 10.1.1.101 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
$ ip netns exec ns0 arp -a
? (10.1.1.101) at a2:60:3b:b0:83:44 [ether] on veth0
可以看到容器间是能正常通信的,我们在ns1的veth1设备抓包,可以看到完整的 arp 的请求响应以及 icmp 的请求响应:
ip netns exec ns1 tcpdump -n -i veth1 -e
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on veth1, link-type EN10MB (Ethernet), snapshot length 262144 bytes
20:12:30.821815 da:ff:de:36:22:8e > ff:ff:ff:ff:ff:ff, ethertype ARP (0x0806), length 42: Request who-has 10.1.1.101 tell 10.1.1.100, length 28
20:12:30.821838 a2:60:3b:b0:83:44 > da:ff:de:36:22:8e, ethertype ARP (0x0806), length 42: Reply 10.1.1.101 is-at a2:60:3b:b0:83:44, length 28
20:12:30.821855 da:ff:de:36:22:8e > a2:60:3b:b0:83:44, ethertype IPv4 (0x0800), length 98: 10.1.1.100 > 10.1.1.101: ICMP echo request, id 61333, seq 1, length 64
20:12:30.821873 a2:60:3b:b0:83:44 > da:ff:de:36:22:8e, ethertype IPv4 (0x0800), length 98: 10.1.1.101 > 10.1.1.100: ICMP echo reply, id 61333, seq 1, length 64
而在tap0打印出的数据,我们只看到一个 arp 的请求包:
2023-10-15 20:12:30: ARP REQUEST: ff ff ff ff ff ff da ff de 36 22 8e 08 06 00 01 08 00 06 04 00 01 da ff de 36 22 8e 0a 01 01 64 00 00 00 00 00 00 0a 01 01 65
好的,大致分析一下:
- ARP Request:此时
ns0中并没有veth110.1.1.101的 arp 表项,所以会发起 arp 广播,对应是da:ff:de:36:22:8e > ff:ff:ff:ff:ff:ff, ethertype ARP (0x0806), length 42: Request who-has 10.1.1.101 tell 10.1.1.100, length 28,其中da:ff:de:36:22:8e是veth0的网卡,ff:ff:ff:ff:ff:ff代表广播地址。由于 arp 是广播,所以在同一个二层的设备都会受到这个广播请求,在我们当前的场景里,通过brctl showmacs br0查到的 mac table 表项都处在同一个二层,所以我们看到我们抓包的veth1网卡,以及tap0设备,都会收到 ARP Request; - ARP Reply:在 arp 请求中问询的是
10.1.1.101的 IP,仅veth1满足,所以veth1会发起 arp 响应,对应是a2:60:3b:b0:83:44 > da:ff:de:36:22:8e, ethertype ARP (0x0806), length 42: Reply 10.1.1.101 is-at a2:60:3b:b0:83:44, length 28,其中 src maca2:60:3b:b0:83:44是veth1的 mac,而 dst macda:ff:de:36:22:8e此时在br0的 mac table 中已经存在,知道它在 port 1,所以对于该以太网帧,br0会直接转发到 port 1,这也就是tap0无法接收到该以太网帧的原因; - 由于上述 arp 已经正常响应,所以
ns0中会正常记录10.1.1.101的 arp 表项。之后发起的 icmp 请求的 dst mac 都能在br0的 mac table 中查到,所以会直接转发到对应 port,tap0也就无法接收到相关数据包;
所以,整体表现符合预期,虽然 Linux Bridge 是虚拟设备,但其行为与物理交换机基本一致,我们可以按物理交换机的逻辑来推导 Linux Bridge 的表现即可。
观察宿主机和容器出网
就目前而言,我们的实验环境就差最后一步,就是将物理网卡插入br0,使得容器也可以通过物理网卡接入外部网络。
可以看到物理网卡enp0s5绑定了外部网段的 IP 192.168.3.242,同时路由表local中也有相关记录:
$ ip a
2: enp0s5: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 00:1c:42:55:fa:79 brd ff:ff:ff:ff:ff:ff
inet 192.168.3.242/24 scope global dynamic enp0s5
valid_lft 84563sec preferred_lft 84563sec
inet6 fe80::77b5:59d4:15ac:16fb/64 scope link noprefixroute
valid_lft forever preferred_lft forever
$ ip route show table local
local 127.0.0.0/8 dev lo proto kernel scope host src 127.0.0.1
local 127.0.0.1 dev lo proto kernel scope host src 127.0.0.1
broadcast 127.255.255.255 dev lo proto kernel scope link src 127.0.0.1
local 192.168.3.242 dev enp0s5 proto kernel scope host src 192.168.3.242
broadcast 192.168.3.255 dev enp0s5 proto kernel scope link src 192.168.3.242
现在我们将物理网卡插入br0,也就是将容器网络与物理网络都放到同一个虚拟的二层:
$ brctl addif br0 enp0s5
# `00:1c:42:55:fa:79`是`enp0s5`的 mac
# `2c:a0:42:f7:a1:7d`是物理网关的 mac
$ brctl showmacs br0
port no mac addr is local? ageing timer
4 00:1c:42:55:fa:79 yes 0.00
4 00:1c:42:55:fa:79 yes 0.00
4 2c:a0:42:f7:a1:7d no 0.38
3 56:64:86:8b:a6:0b yes 0.00
3 56:64:86:8b:a6:0b yes 0.00
2 82:c4:73:f0:75:df yes 0.00
2 82:c4:73:f0:75:df yes 0.00
2 a2:60:3b:b0:83:44 no 26.80
1 ce:85:09:8a:b1:7b yes 0.00
1 ce:85:09:8a:b1:7b yes 0.00
1 da:ff:de:36:22:8e no 72.11
此时虽然容器网络和物理网络在同一虚拟的二层,但是可以看到路由表中与192.168.3.0/24相关的项均已被内核删除,说明当物理网卡插入网桥时,其三层的功能已经失效,这时候物理机其实也无法连通外网。
$ ip route show table local
local 127.0.0.0/8 dev lo proto kernel scope host src 127.0.0.1
local 127.0.0.1 dev lo proto kernel scope host src 127.0.0.1
broadcast 127.255.255.255 dev lo proto kernel scope link src 127.0.0.1
$ route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
此时我们将源物理网卡的 IP 绑定到br0,并添加相关路由策略,使物理机可以正常访问外部网络:
$ ip addr del 192.168.3.242/24 dev enp0s5
$ ip addr add 192.168.3.242/24 dev br0
$ ip route show table local
local 127.0.0.0/8 dev lo proto kernel scope host src 127.0.0.1
local 127.0.0.1 dev lo proto kernel scope host src 127.0.0.1
broadcast 127.255.255.255 dev lo proto kernel scope link src 127.0.0.1
local 192.168.3.242 dev br0 proto kernel scope host src 192.168.3.242
broadcast 192.168.3.255 dev br0 proto kernel scope link src 192.168.3.242
$ route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
169.254.0.0 0.0.0.0 255.255.0.0 U 1000 0 0 br0
192.168.3.0 0.0.0.0 255.255.255.0 U 0 0 0 br0
$ ip route add default via 192.168.3.1 dev br0
$ ping -c1 8.8.8.8
PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data.
64 bytes from 8.8.8.8: icmp_seq=2 ttl=53 time=240 ms
--- 8.8.8.8 ping statistics ---
1 packets transmitted, 1 received, 100% packet loss, time 3029ms
好的,现在我们物理机已经可以正常通过br0访问外部网络,且容器与物理网卡处在同一虚拟的二层,我们还需要将容器网络与物理网络放到同一个三层,也就是让容器也加入192.168.3.0/24的网段:
$ ip netns exec ns0 ip a
...
9: veth0@if8: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether da:ff:de:36:22:8e brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.1.1.100/24 scope global veth0
valid_lft forever preferred_lft forever
inet6 fe80::d8ff:deff:fe36:228e/64 scope link
valid_lft forever preferred_lft forever
# 配置容器的`veth0`网卡也在`192.168.3.0/24`的物理网段,并添加默认路由
$ ip netns exec ns0 ip addr add 192.168.3.150/24 dev veth0
$ ip netns exec ns0 ip route add default via 192.168.3.1 dev veth0
$ ip netns exec ns0 route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.3.1 0.0.0.0 UG 0 0 0 veth0
10.1.1.0 0.0.0.0 255.255.255.0 U 0 0 0 veth0
192.168.3.0 0.0.0.0 255.255.255.0 U 0 0 0 veth0
此时验证容器网络与外部网络的连通性:
ip netns exec ns0 ping -c1 8.8.8.8
PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data.
64 bytes from 8.8.8.8: icmp_seq=1 ttl=53 time=173 ms
--- 8.8.8.8 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
在容器网卡veth0中抓包,此时我们可以看到流程其实相当简单了:
$ ip netns exec ns0 tcpdump -n -i veth0 -e icmp
20:34:37.457254 da:ff:de:36:22:8e > 2c:a0:42:f7:a1:7d, ethertype IPv4 (0x0800), length 98: 192.168.3.150 > 8.8.8.8: ICMP echo request, id 58008, seq 1, length 64
20:34:37.657440 2c:a0:42:f7:a1:7d > da:ff:de:36:22:8e, ethertype IPv4 (0x0800), length 98: 8.8.8.8 > 192.168.3.150: ICMP echo reply, id 58008, seq 1, length 64
- 当在
ns0中执行ping 8.8.8.8命令时,根据默认路由表,8.8.8.8需要走网关转发,也就是192.168.3.1,在ns0的 arp 表中已经记录了该网关地址的 mac 信息,所以不需要发起 arp 广播,可以直接构造 icmp 请求; - icmp 请求的 src mac 是
veth0设备,dst mac 是物理网关,二者处在同一二层,veth0在br0的 port 1,物理网关在 port 4(在前面的 brctl showmacs br0 中可以查到),所以直接可达; - icmp 的响应也是一样,直接在二层转发;
