1. 环境准备
1.1. 环境配置
| 宿主机 | 操作系统 | 5.19.0-45-generic #46~22.04.1-Ubuntu / win10 双系统 |
|---|---|---|
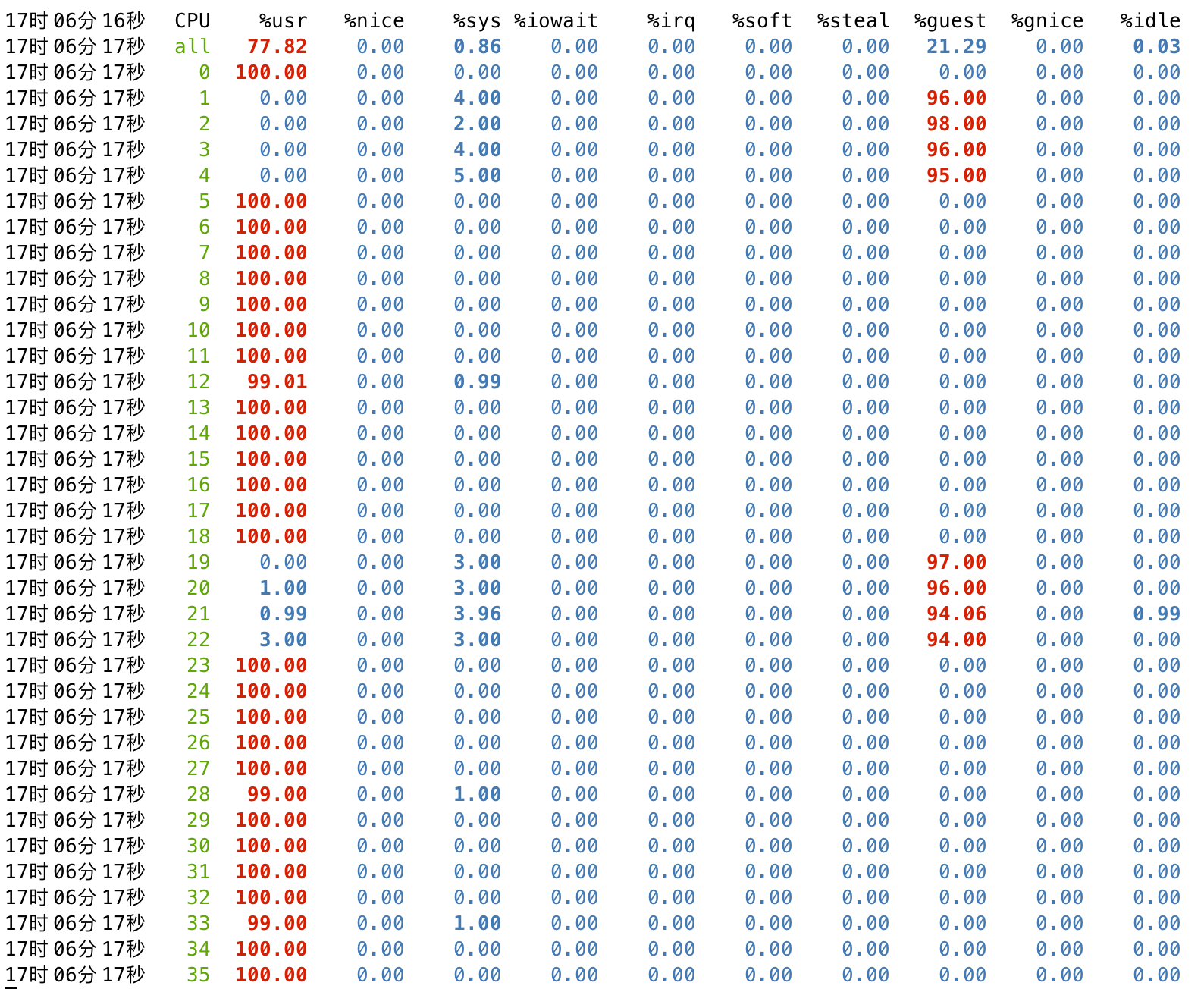
| 规格 | 18 核 36 线程 64G 内存,主频 2.3Ghz,睿频已关 | |
| 拓扑 |
|
|
| 客户机 | 操作系统 | win10 1909 |
| 规格 | 8 核 8G 内存 |
1.2. 测试&观测工具
| 宿主机 | mpstat |
|---|---|
| 客户机 | cpuz |
1.3. 客户机配置文件
libvirt 的主要配置如下,省略 devices 部分:
<domain type='kvm'>
<name>win10-2</name>
<uuid>a5884a23-73f0-44d2-8ca9-45872223f844</uuid>
<metadata>
<libosinfo:libosinfo xmlns:libosinfo="http://libosinfo.org/xmlns/libvirt/domain/1.0">
<libosinfo:os id="http://microsoft.com/win/10"/>
</libosinfo:libosinfo>
</metadata>
<memory unit='KiB'>8388608</memory>
<currentMemory unit='KiB'>8388608</currentMemory>
<vcpu placement='static'>8</vcpu>
<os>
<type arch='x86_64' machine='pc-q35-6.2'>hvm</type>
<loader readonly='yes' type='pflash'>/usr/share/OVMF/OVMF_CODE_4M.ms.fd</loader>
<nvram>/var/lib/libvirt/qemu/nvram/win10-2_VARS.fd</nvram>
</os>
<features>
<acpi/>
<apic/>
</features>
<cpu mode='host-passthrough' check='none' migratable='on'>
<topology sockets='1' dies='1' cores='4' threads='2'/>
</cpu>
<clock offset='localtime'>
<timer name='rtc' tickpolicy='catchup'/>
<timer name='pit' tickpolicy='delay'/>
<timer name='hpet' present='yes'/>
</clock>
<on_poweroff>destroy</on_poweroff>
<on_reboot>restart</on_reboot>
<on_crash>destroy</on_crash>
<pm>
<suspend-to-mem enabled='no'/>
<suspend-to-disk enabled='no'/>
</pm>
<devices>...</devices>
</domain>
|
2. 性能调优
2.1. 问题描述
在宿主机 win10 系统下使用 cpuz 跑分,在睿频关闭的情况下(睿频本身不稳定,会影响观测结果),可以看到单核的分数稳定在 255~260 之间。
在客户机上使用 cpuz 跑分,看到单核跑分仅 200 分左右。
cpuz 的任务都是计算型任务,不会触发 vmexit,理论上客户机跑分应该直逼宿主机分数,但案例中存在较大差异,需要优化。
2.2. 问题排查
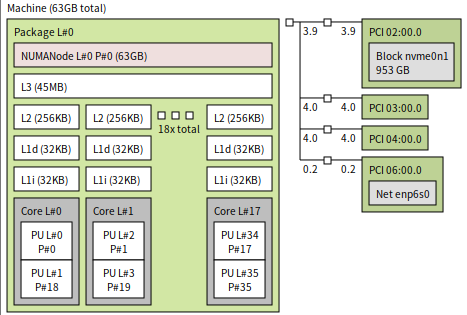
通过mpstat在宿主机观察客户机vcpu的调度,在压测单核性能时,可以看到 vcpu 会被调度到不同的宿主机 pcpu 上,这样会导致线程切换的系统开销以及 cache miss。
$ mpstat -P ALL 1 |
2.3. 解决思路
2.3.1. vcpupin
首先在 libvirt 中进行 vcpu 绑核操作,使得 qemu 的 vcpu 线程可以稳定的调度到确定的 pcpu 上,减少 sys 的开销并增加缓存命中率。案例环境的宿主机是 18 核超线程的拓扑,所以在这里绑核的时候也是按实际的物理结构来绑定。
<cputune> <vcpupin vcpu='0' cpuset='1'/> <vcpupin vcpu='1' cpuset='19'/> <vcpupin vcpu='2' cpuset='2'/> <vcpupin vcpu='3' cpuset='20'/> <vcpupin vcpu='4' cpuset='3'/> <vcpupin vcpu='5' cpuset='21'/> <vcpupin vcpu='6' cpuset='4'/> <vcpupin vcpu='7' cpuset='22'/> </cputune> ... <cpu mode='host-passthrough' check='none' migratable='on'> <topology sockets='1' dies='1' cores='4' threads='2'/> </cpu> |
调整之后再使用 cpuz 跑分,单核分数已经稳定在 245~250 之间,非常接近宿主机分数。
2.3.2. isolcpus
在云计算的环境下,宿主机还会运行一些网络、存储相关的基础组件,这些基础组件本身也会有对 cpu 有一定开销,如果这些基础组件被调度到客户机的 pcpu 上,会挤占客户机的资源,导致客户机内部出现未知的性能抖动。本案例里通过在宿主机上使用 sysbench 来模拟极端情况下宿主机抢占客户机资源的情况。
首先在宿主机通过 sysbench 来压榨 cpu 资源,宿主机包含 18 核 36 线程,所以 sysbench 也指定 36 线程来消耗完宿主机的资源:
$ sysbench cpu run --time=1000000 --threads=36 |
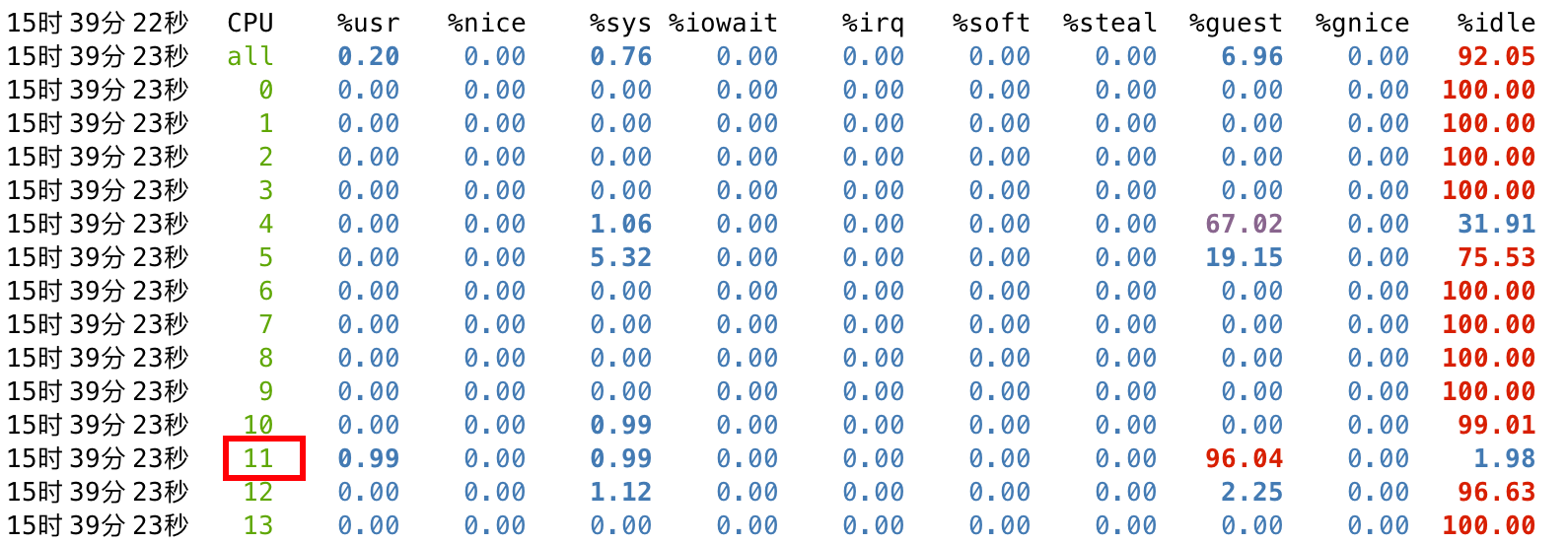
之后通过 mpstat 查看资源占用状态,可以看到宿主机各个核的资源占用率都逼近 100%:
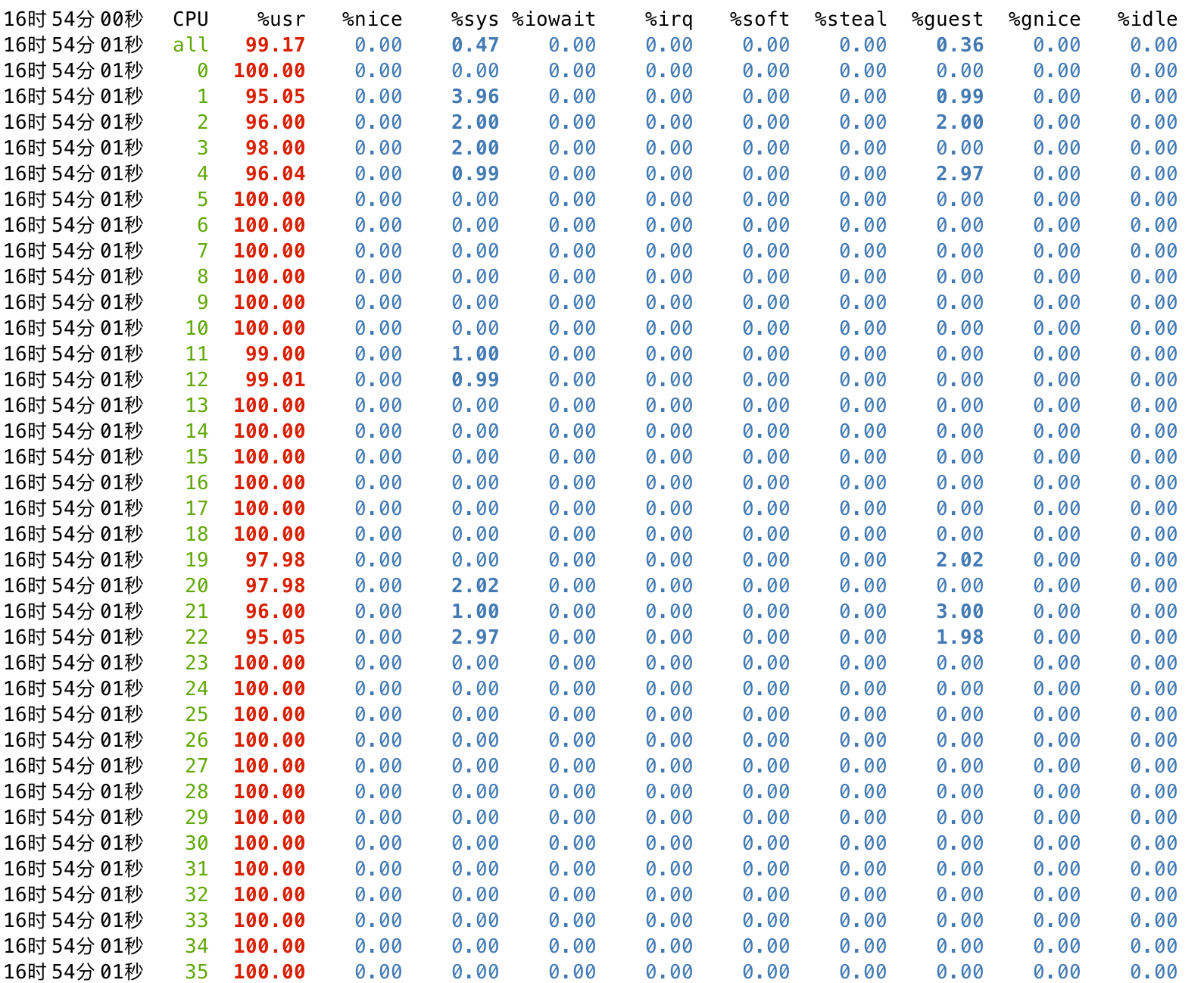
此时启动客户机,并通过 cpuz 跑分,可以看到单核分数仅在 140~160 之间,且存在较大范围的波动。
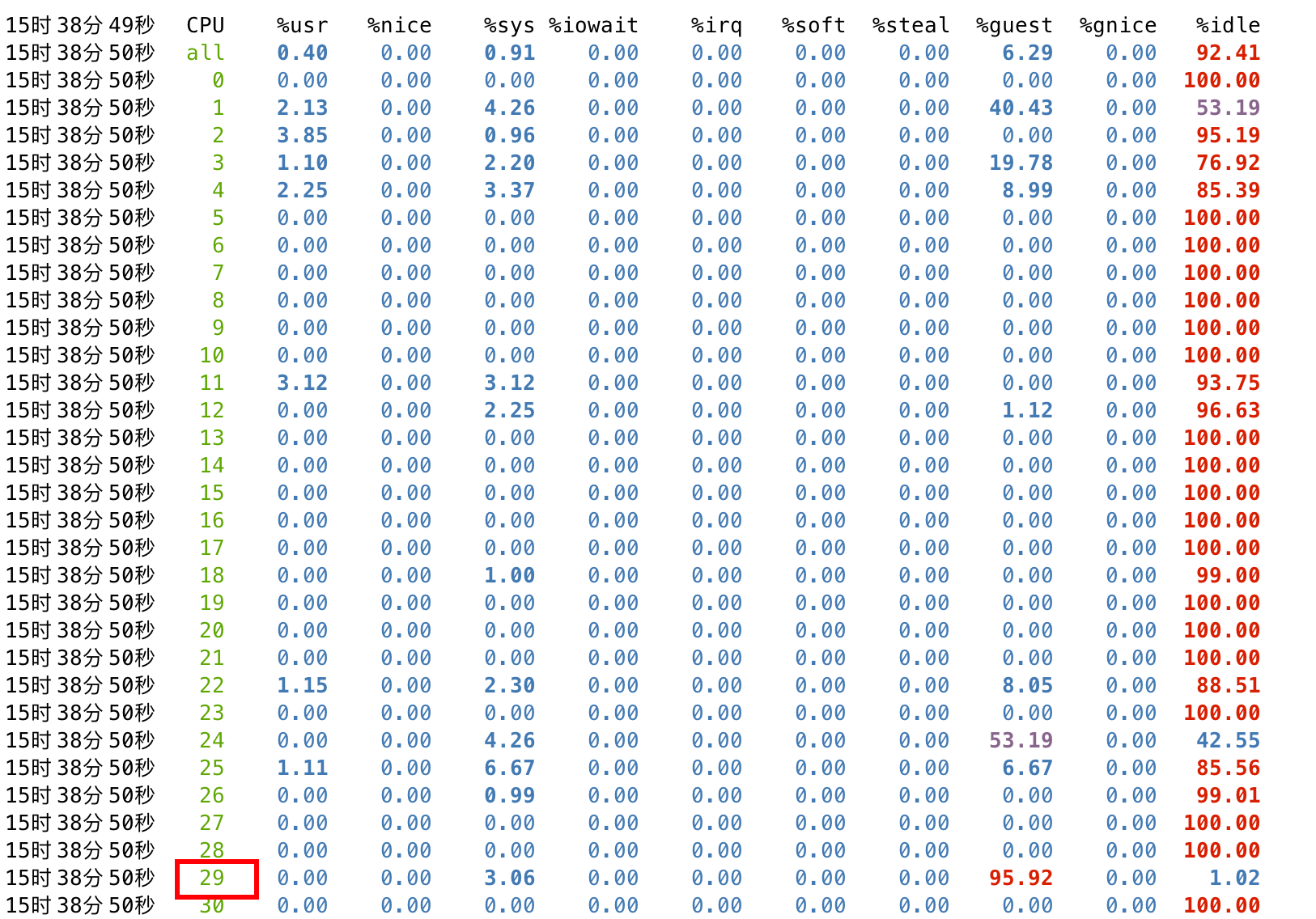
此时再在宿主机查看调度状态,可以看到分配给客户机的 pcpu(1-4,19-22)存在争用的情况,%usr 是宿主机 sysbench 的开销,而 %guest 是客户机内部 cpuz 的开销。
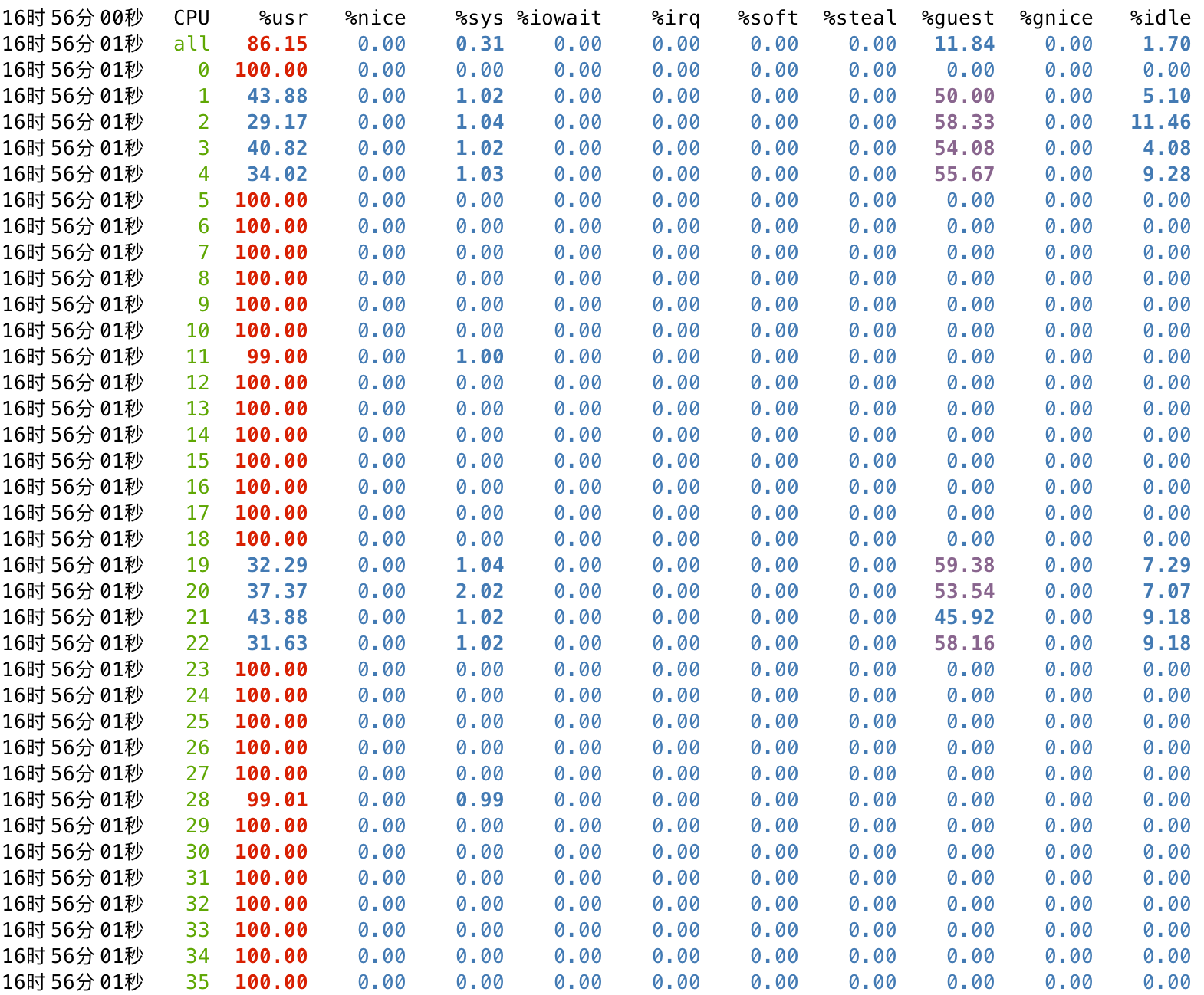
所以基于上述的测试,可以明确在宿主机的基础组件开销过大的情况下,会对客户机的性能产生影响。所以这里考虑将分配给客户机的 pcpu 从宿主机孤立出来,使得宿主机操作系统以及其它进程不会被调度到分配给客户机的 pcpu 上,避免客户机内部出现未知抖动。
首先修改 /etc/default/grub,增加 isolcpus 配置,并与 libvirt 的 vcpupin 中分配给客户机的 cpulist 保持一致:
$ vim /etc/default/grub GRUB_CMDLINE_LINUX_DEFAULT="isolcpus=1-4,19-22" |
然后 update-grub 并重启系统生效:
$ update-grub |
系统重启完毕后,重复刚才的验证步骤:
$ sysbench cpu run --time=1000000 --threads=36 |
此时可以看到被隔离出来的 1-4,19-22 这些物理核心是没有被 SMP 调度到的。
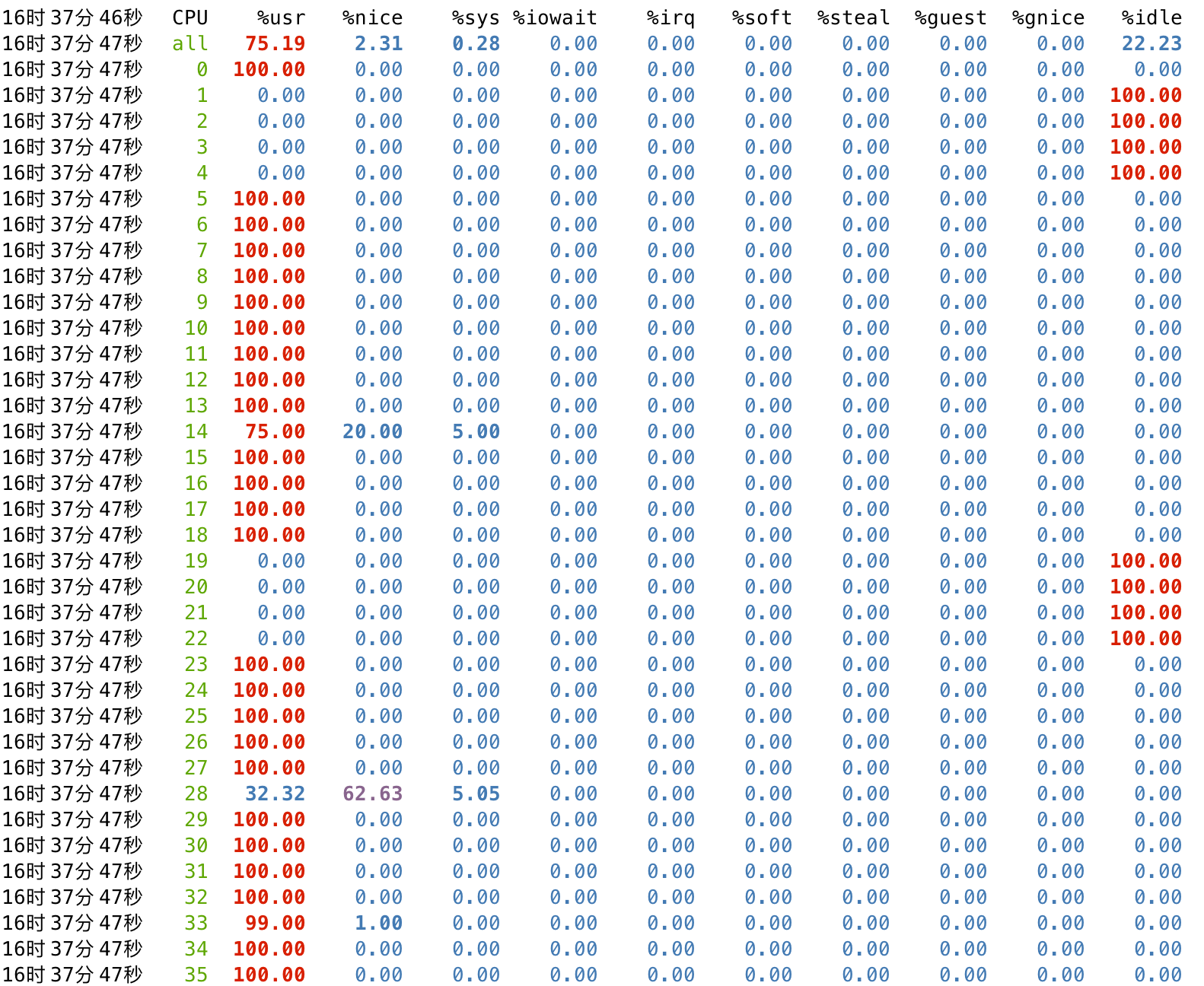
此时再启动客户机,通过 cpuz 跑分,分数基本稳定在 245~250 之间,宿主机上 sysbench 的开销并未对客户机性能造成影响。
同时通过 mpstat 观测,可以看到 cpulist 的 1-4,19-22 的开销主要集中在 %guest,并未出现与宿主机用户态进程抢占资源的情况。