


起因:
最近笔者遇到一个开发需求。系统原来使用全局唯一的字段用户名(username)做为每个微服务业务存储的用户标识。例如业务对象的新增人,修改人,负责人等。这个字段的值本来是类似zhangsan,lisi这种相对还是有意义的。最近要求接入别人加IAM系统,不看不知道,一看吓一跳。这个IAM的用户标识不是用户的名称而是一个类似uuid,雪花算法类似的无意义值。如果显示这个IAM带来的用户标识,用户实际看到的是一堆长串无意义字符串,体验感直线下滑。(见下图)
思考:
由于系统已经开发了好几年。且不说100%,起码70%的返回给前端的接口里返回都带用户。用户基本信息包括用户标识和用户昵称。昵称显然是适合在前端页面展示的。但是昵称的问题是可以被修改,不能做为唯一标识。而且系统已经在生产部署过的场景,也不适合对已有数据进行大规模patching。
大致分析后大概有两个思路。
- 一个是后端提供一个全量用户基础信息(用户标识和昵称)的接口给前端。前端在刷新页面的时候读取并缓存起来。前端根据每个原来显示用户名的地方读取缓存的映射表转换成用户昵称显示。
- 另一个是后端在返回内容上加上对应的用户昵称字段,前端只需修改逻辑显示新增的昵称字段。
内部讨论后一致决定苦后端不能苦前端😂的理念(谁叫后端是大佬呢?)。开玩笑,其实第一种方案如果要解决用户修改后,如何让前端刷新缓存会让问题越来越复杂。
我们重新审视这个开发需求:现在已有一些完整的接口返回,业务主逻辑不需要改动,只需根据原接口的字段获取对应数据附加返回即可。如果只是为了完成这个需求,最简单的方法是每个微服务的后端研发同学写一个调用系统管理服务传入用户名返回用户昵称的工具类方法。在返回用户名的接口处调用这个工具类获取对应的用户昵称,然后把用户昵称填入。但做为软件开发的一个重要准则是DRY("Don't Repeat Yourself"):减少重复代码,提高代码的可维护性和可扩展性。
仔细发现这个功能需求跟企业集成模式EIP(Enterprise Integration Patterns)中的Enrich概念是一致的。具体请读者自己搜索enterpriseintegrationpatterns网页力Enrich的介绍
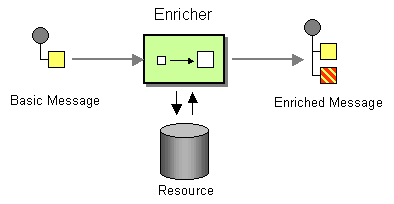
Use a specialized transformer, a Content Enricher, to access an external data source in order to augment a message with missing information.
使用专用转换器(内容扩充器)访问外部数据源,以便使用缺失的信息来扩充消息。
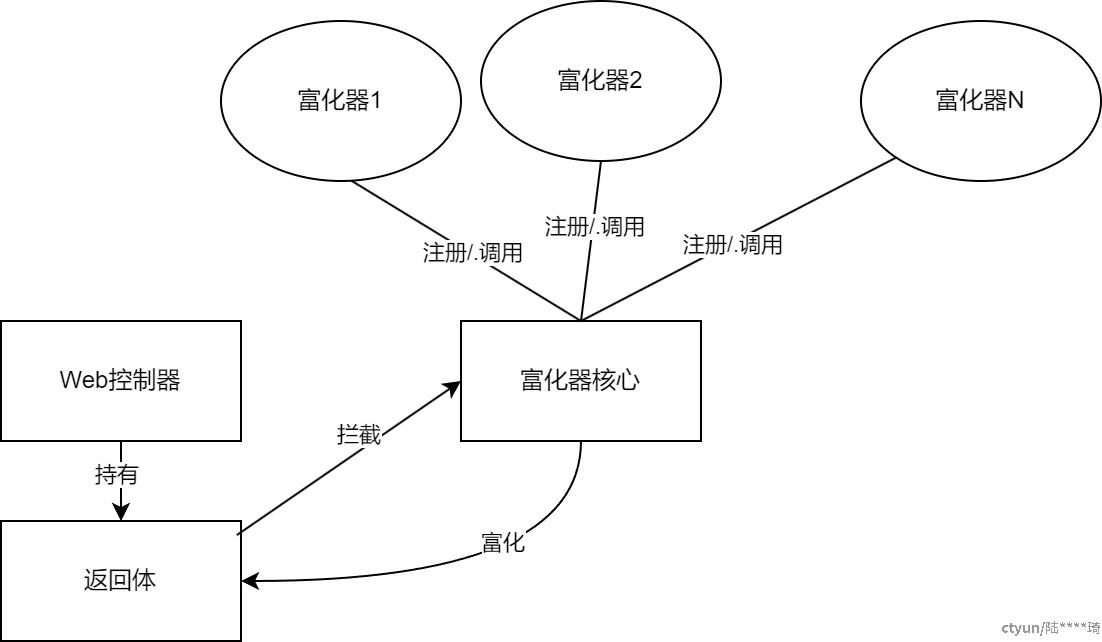
这时我们可以通过提供一个统一的昵称转换工具包,每个微服务引用后,只需通过简单的配置(例如注解)就可以完成统一和快捷的内容富化。但我们可以把这个需求进一步延展,除了增加用户昵称的需求,以后如果类似根据返回字段中数据源id增加数据源当前名称,对返回字段进行脱敏等需求时,是否可以快速实现并减少对各种返回类型的重复处理呢?一个返回内容富化器框架的想法就诞生了。框架分成两个主要部分:核心层和插件层。
核心层负责处理控制器接口返回的对象。根据注解对返回对象的富化字段进行抽取并根据字段上配置的具体富化注解调用相应的富化处理器。
插件层定义具体富化器注解,通过实现富化器插件接口完成返回对象的富化。
简单关系图如下:
大致思路有了,让我们开始手搓。Get your hands dirty!
手搓框架:
先解决返回体拦截的问题。
熟悉的同学开始从工具箱里拿出了Interceptor、Filter、ResponseBodyAdvice等等。我这边选择ResponseBodyAdvice,原因是我们微服务都是基于springmvc框架,并且这个方法对调用法方的代码侵入是最小的。我们先看一下ResponseBodyAdvice的使用说明。
Allows customizing the response after the execution of an @ResponseBody or a ResponseEntity controller method but before the body is written with an HttpMessageConverter.Implementations may be registered directly with RequestMappingHandlerAdapter and ExceptionHandlerExceptionResolver or more likely annotated with @ControllerAdvice in which case they will be auto-detected by both.
允许在执行@ResponseBody或ResponseEntity控制器方法后但在使用HttpMessageConverter写返回的body之前自定义响应。配合@ControllerAdvice注解就可以被容器检测并注入。很好的契合我们的需求。
接着看看ResponseBodyAdvice的接口定义
public interface ResponseBodyAdvice<T> {
/**
* Whether this component supports the given controller method return type
* and the selected {@code HttpMessageConverter} type.
* @param returnType the return type
* @param converterType the selected converter type
* @return {@code true} if {@link #beforeBodyWrite} should be invoked;
* {@code false} otherwise
*/
boolean supports(MethodParameter returnType, Class<? extends HttpMessageConverter<?>> converterType);
/**
* Invoked after an {@code HttpMessageConverter} is selected and just before
* its write method is invoked.
* @param body the body to be written
* @param returnType the return type of the controller method
* @param selectedContentType the content type selected through content negotiation
* @param selectedConverterType the converter type selected to write to the response
* @param request the current request
* @param response the current response
* @return the body that was passed in or a modified (possibly new) instance
*/
@Nullable
T beforeBodyWrite(@Nullable T body, MethodParameter returnType, MediaType selectedContentType,
Class<? extends HttpMessageConverter<?>> selectedConverterType,
ServerHttpRequest request, ServerHttpResponse response);
}其中在supports方法实现中通过返回布尔值决定拦截的请求返回是否需要被处理。在beforeBodyWrite方法实现中可以对返回体进行实质处理。
先实现supports方法,用一个自定义的@RespEnrich注解做为标识,如果controller里的API接口方法的返回需要被富化,就打上这个注解。代码如下
@Override
public boolean supports(MethodParameter returnType, Class<? extends HttpMessageConverter<?>> converterType) {
// Controller方法必须注册Enrich注解
List<Annotation> annotations = Arrays.asList(returnType.getMethodAnnotations());
return !ObjectUtils.isEmpty(annotations) && annotations.stream().anyMatch(RespEnrich.class::isInstance);
}接着就是重头戏beforeBodyWrite。这里我们需要进一步根据返回的类型进行细化处理。因为我们微服务的统一定义了返回的格式,这时我们需要把主要的内容data抽离出来。返回是有单个对象和多个对象(list或者page),这时候我们可以分单个对象和多个对象的场景,并且在富化器的接口设计上,我们也相应的可以加入批量处理的支持的判断。
@Override
public Object beforeBodyWrite(Object body, MethodParameter returnType, MediaType selectedContentType, Class<? extends HttpMessageConverter<?>> selectedConverterType, ServerHttpRequest request, ServerHttpResponse response) {
log.debug("body : {}", body != null ? body.toString() : null);
// 支持Response类包装
if (body instanceof SingleResponse) {
doEnrich(((SingleResponse<?>) body).getData());
} else if (body instanceof MultiResponse) {
doEnrich(((MultiResponse<?>) body).getData());
} else if (body instanceof PageResponse) {
doEnrich(((PageResponse<?>) body).getData());
} else { // 其他返回类型
doEnrich(body);
}
return body;
}我们参照Hibernate Validator的设计。富化器的接口也大致出来了。其中getAnnotation返回当前富化器支持的自定义注解。enrich方法实现对单个目标的富化。当supportBatch返回true时,框架遇到多个目标输入时会调用enriches方法进行更高效的批量处理方式。
public interface RespEnrichHandler<A extends Annotation> {
/**
* 获取本处理器支持的注解类型
*
* @return
*/
Class<A> getAnnotation();
default boolean supportBatch() {
return false;
}
void enrich(Field field, Object object);
default void enriches(Field field, List<?> objects) {
}
}哪些富化器注解会被支持呢,我们可以在类的初始化阶段对实现RespEnrichHandler接口的bean进行扫描并注册。
private final Map<Class<? extends Annotation>, RespEnrichHandler<? extends Annotation>> enrichHandlerMap = new HashMap<>();
public RespEnrichAdvice(ObjectProvider<RespEnrichHandler<? extends Annotation>> enrichHandlersProvider) {
enrichHandlersProvider.stream()
.forEach(eh -> enrichHandlerMap.putIfAbsent(eh.getAnnotation(), eh));
}这里我用到了ObjectProvider,ObjectProvider 是 Spring Framework 4.3 版本引入的一个接口,它扩展了 ObjectFactory 接口,专门为注入点设计,可以让依赖注入变得更加灵活和安全。ObjectProvider 提供了一种延迟加载对象的机制,允许在需要时动态地获取对象。它支持泛型,可以通过泛型指定要获取的 Bean 的类型,避免了类型转换的麻烦。没有用过的同学可以自行搜索学习。
我们回到框架核心的核心方法doEnrich系列。
private void doEnrich(Object any) {
if (any instanceof List) {
doEnriches0((List<?>) any);
} else if (any instanceof Object[]) {
doEnriches0(Arrays.asList((Object[]) any));
} else {
doEnrich0(any);
}
}
private void doEnrich0(Object object) {
// 获取输入对象所有declaredField,如果有注册的Enrich系列的属性,则调用对应的EnrichHandler。如果字段定义了Enrich注解,则递归处理。
Class<?> clazz = object.getClass();
Field[] clazzFields = getAllFields(clazz);
for (Field field : clazzFields) {
if (field.isAnnotationPresent(RespEnrich.class)) {
try {
PropertyDescriptor propertyDescriptor = BeanUtils.getPropertyDescriptor(field.getDeclaringClass(), field.getName());
Method readMethod = propertyDescriptor.getReadMethod();
Object fieldValue = readMethod.invoke(object);
doEnrich(fieldValue);
} catch (Exception e) {
log.error(e.getMessage(), e);
}
continue;
}
processAnnotationsOfOneItem(field, object);
}
}
private void doEnriches0(List<?> objects) {
if (ObjectUtils.isEmpty(objects)) {
return;
}
Object first = objects.get(0);
// 处理多层List或数组情况
if (first instanceof List || first instanceof Object[]) {
objects.forEach(this::doEnrich);
return;
}
Class<?> clazz = first.getClass();
Field[] clazzFields = getAllFields(clazz);
for (Field field : clazzFields) {
if (field.isAnnotationPresent(RespEnrich.class)) {
PropertyDescriptor propertyDescriptor = BeanUtils.getPropertyDescriptor(field.getDeclaringClass(), field.getName());
Method readMethod = propertyDescriptor.getReadMethod();
try {
List<Object> values = new ArrayList<>();
for (Object object : objects) {
Object fieldValue = readMethod.invoke(object);
values.add(fieldValue);
}
doEnrich(values);
} catch (Exception e) {
log.error(e.getMessage(), e);
}
continue;
}
processAnnotationsOfCollection(field, objects);
}
}这里用到了几次递归调用,主要为了处理嵌套定义的场景。在实际开发中,我们的对象很多时候都是对其他对象的组合。所以我们的返回对象也就不可能只有一层,如果框架一直对返回对象深度扫描,效率肯定无法保证。这个时候我们就可以学习Hibernate Validator中@valid的设计思路,框架只扫描当前对象的所有字段,对于嵌套的对象,如果字段上有@RespEnrich的注解,我们再深入这个字段的所有字段进行扫描。事实证明,这个策略非常有效。再仔细看,我们这里对目标对象的类型进行了判断,如果是多对象的时候,我们将进入批量的处理逻辑。在实际使用中,支持批量处理的富化器可以大大提高富化的效率。processAnnotationsOfOneItem 和 processAnnotationsOfCollection是对具体富化器方法的调用。其中processAnnotationsOfCollection也适配富化器不支持批量退化成串行处理。
private void processAnnotationsOfOneItem(Field field, Object object) {
Annotation[] annotations = field.getAnnotations();
if (ObjectUtils.isEmpty(annotations)) {
return;
}
Arrays.stream(annotations).forEach(a -> {
if (enrichHandlerMap.containsKey(a.annotationType())) {
RespEnrichHandler<?> handler = enrichHandlerMap.get(a.annotationType());
handler.enrich(field, object);
}
});
}
private void processAnnotationsOfCollection(Field field, List<?> objects) {
Annotation[] annotations = field.getAnnotations();
if (ObjectUtils.isEmpty(annotations)) {
return;
}
Arrays.stream(annotations).forEach(a -> {
if (enrichHandlerMap.containsKey(a.annotationType())) {
RespEnrichHandler<?> handler = enrichHandlerMap.get(a.annotationType());
if (handler.supportBatch()) {
handler.enriches(field, objects);
} else {
objects.forEach(object -> handler.enrich(field, object));
}
}
});
}好了,核心已经写完了。我们写一个简单的富化器看看。
富化器例子:
这个简单的富化器叫EnrichCopy,它读取注解中的SPEL表达式,把结果写入到当前的字段。
先定义富化器的注解
@Target({FIELD})
@Retention(RUNTIME)
public @interface EnrichCopy {
// 使用SPEL表达式,表达式的结果作为注解字段的值
@AliasFor("value")
String source() default "";
@AliasFor("source")
String value() default "";
}富化器的处理器
@Component
@Slf4j
public class EnrichCopyHandler implements RespEnrichHandler<EnrichCopy> {
@Value("${ddaf.resp-enrich.copy.enabled:true}")
private boolean enabled;
@Override
public Class<EnrichCopy> getAnnotation() {
return EnrichCopy.class;
}
@Override
public void enrich(Field field, Object object) {
log.debug("Before Call EnrichNickNameHandler for field:{} value:{}", field.getName(), object);
AnnotationAttributes attributes = AnnotatedElementUtils.getMergedAnnotationAttributes(field, EnrichCopy.class);
if (attributes == null) {
return;
}
String sourceFieldName = attributes.getString("source");
if (Strings.isNotBlank(sourceFieldName)) {
try {
ExpressionParser parser = new SpelExpressionParser();
EvaluationContext evaluationContext = new StandardEvaluationContext(object);
Object sourceFieldValue = parser.parseExpression(sourceFieldName).getValue(evaluationContext, field.getType());
PropertyDescriptor propertyDescriptor = BeanUtils.getPropertyDescriptor(field.getDeclaringClass(), field.getName());
Method writeMethod = propertyDescriptor.getWriteMethod();
writeMethod.invoke(object, sourceFieldValue);
} catch (Exception e) {
log.error("设置用户昵称错误: {}", e.getMessage(), e);
}
}
log.debug("After Call EnrichNickNameHandler for field:{} value:{}", field.getName(), object);
}
}是不是很快就实现了。在框架的作用下,我们只需要实现对给定字段的具体富化的逻辑,无需操心富化器使用方的各种使用场景。
结语:
此框架上线后,大大减少了后端微服务改造的成本和出错机会。后续大家可以发挥余力,贡献更多有用的富化器。让我们一起减少重复性工作,早点完成任务下班。😄😄
