


Code Generation 技术
Code Generation 是将高级语言代码转换为低级语言代码(如机器码)的过程。它在数据库管理系统(DBMS)和计算引擎中尤为重要:当执行查询时,DBMS 会首先将查询发送给解析器parser以生成抽象语法树(AST)。然后将 AST 传递给binder,binder与系统通信,由AST获得Annotated AST(Logical Plan)。然后,优化器optimizer将带注释的 AST 转换为物理计划(Physical Plan)。最后,将物理计划被送给编译器,编译器使用代码生成Code gen方法生成本机代码(native code)。两种常见的 Code Generation 方法包括:
1. Transpilation(Source-to-Source Compilation)
Transpilation 作为一种 Code Gen技术,将一种高级语言的源代码转换为另一种高级语言的源代码。它通常用于将现代编程语言特性引入到不支持这些特性的环境中。Transpilation(转译)要编写将关系查询计划转换为命令式语言源代码的代码,然后使用传统的编译器编译来生成native code。
e.g. 全量Code gen,对于给定的一个查询计划,Transpilation 生成的是一个C/C++ 来实现的 计划执行(包括所有谓词、类型转换等),然后用例如GCC编译成一个so库运行时候 link 到DBMS/引擎,执行即可。
2. JIT Compilation(即时编译)
JIT Compilation 是另一种 Code Gen 技术,它在程序运行时将字节码转换为机器码。JIT编译生成的查询的中间表示(IR),可以快速编译成native code。JIT结合了编译和解释的优点,常用于虚拟机环境,如 JVM 。
2.1. Efficiently Compiling Efficient Query Plans for Modern Hardware论文阅读
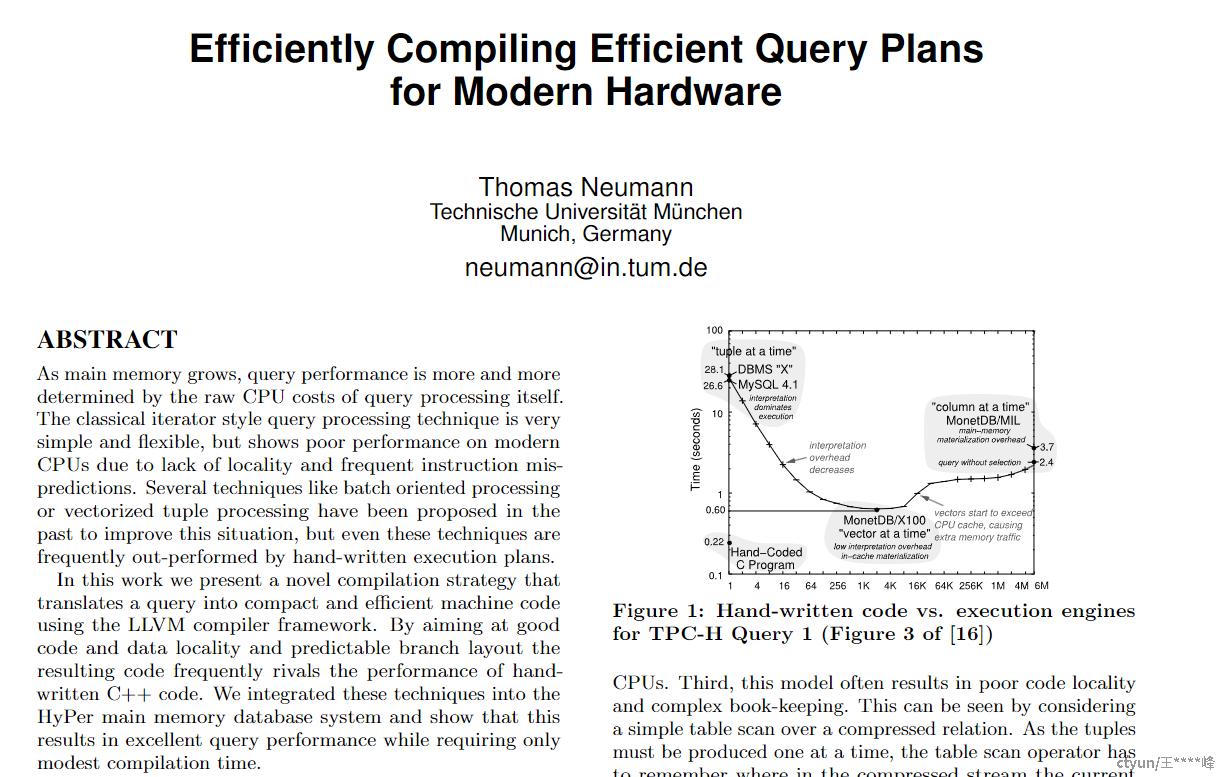
这篇论文(较早)提出的这一查询编译策略,利用LLVM 编译器框架将查询转换为紧凑高效的机器代码。它的关键思想包括:
1. 处理以数据为中心而非以操作符为中心,尽可能将数据保留在CPU寄存器中并模糊操作符边界;
2. Push-based model,数据被推向操作符而非被操作符pull拉取,提高了代码和数据的局部性;
3. 查询被编译成native code利用了LLVM编译器的优化。
论文提出的这种方法可以与手工编码的查询执行计划媲美,在某些情况下甚至更好。可以自行参考论文内容,查看论文中将JIT集成到HyPer然后进行若干OLAP引擎的性能对比结果。
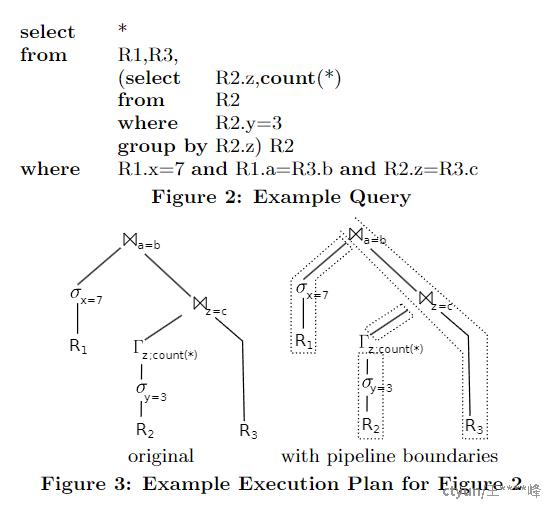

文中Figure2~4演示了如何将一个查询,通过对以pipeline breaker分界的一个查询计划的若干部分(fragments)以便进行Code gen实现查询计划的编译,这个概念一个核心思想是希望在查询处理过程中,所有数据都应尽可能长时间地保存在CPU register中,这些fragments(或 pipelines)内部保证这一点。

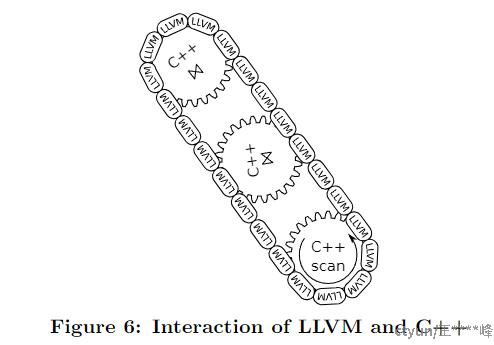
LLVM在查询编译策略中的作用主要包括以下几个方面:
- 生成高性能的机器代码。LLVM提供了一个优化的JIT编译器,可以将LLVM汇编代码快速编译为原生的机器代码,性能优于手工编写的C++代码。
- 提供了一个抽象的中间表示IR,隐藏了底层架构细节。开发者可以专注于生成LLVM汇编代码,而不需要关心具体的机器指令。
- 支持与C++代码的无缝集成。LLVM生成的机器代码可以直接调用C++实现的复杂数据结构和算法,实现了高性能的混合执行模型。
- 提供了强类型检查,帮助发现编码错误。相比手写汇编代码,LLVM汇编代码具有更好的类型安全性。
- 文中还提到这简化了复杂操作符Complex Operators的代码生成过程。LLVM可以帮助管理寄存器分配、函数调用等底层细节,使得开发者能够专注于高层次的查询逻辑。
Apache Spark
Apache Spark里有例如将查询的WHERE子句表达式树转换成Scala AST,然后编译这些AST生成JVM字节码的实现,然后放到本地执行。
Spark的Whole-Stage Code Generation工作原理也是将多个物理operator融合成一个 Java 函数,生成一个整体的执行计划,减少虚函数调用的开销,避免 Volcano 模型中的性能问题。
