


技术简介
[数据级并行] SIMD也即单指令多数据指令(Single instruction, multiple data),通过一些CPU指令集、一些特殊寄存器,可以在同一时钟周期内同时对多个数据执行相同操作。由指令集暴露的数据并行性。不是一个具体的硬件设备比如GPU 以在同一指令周期内同时对多个数据执行相同操作。由指令集暴露的数据并行性。
SIMD在早期用于图像 像素的处理,这里对大规模数据并行性的需求体现在例如对图片的各种操作,例如放大/缩小,是把多个像素点同时加载到一个寄存器里,每个像素执行同样的计算然后写回内存实现图像的放大/缩小,图像处理的速度得到了很大提升。这是硬件级别的用于提高计算效率的数据并行处理技术。
02年论文Implementing Database Operations Using SIMD Instructions 这里是来自应是最先提出 将SIMD应用于数据库Operations,包括filter projection aggregation,都可以使用SIMD提升性能。对于OLAP/计算密集型程序来说,可能经常会需要对大量不同的数据进行同样的运算,因为现行较多执行引擎都采用了列式存储,而列式存储的一大特点就是局部性+顺序存储+同类数据。使用SIMD计算进行DB引擎的向量化执行可以做到数据级别的并行计算,实现性能提升。
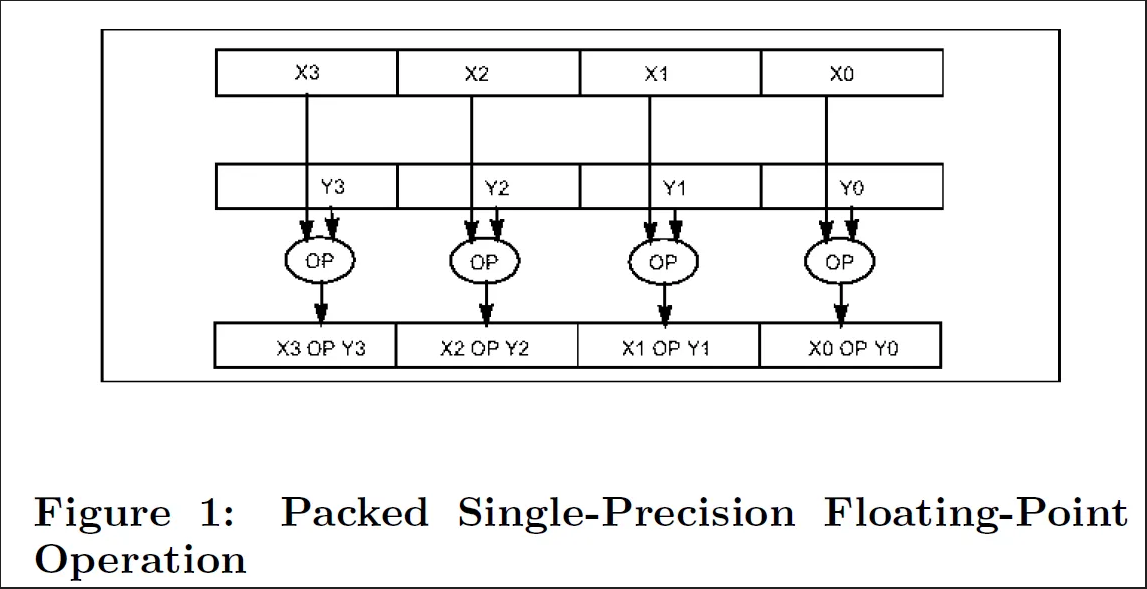
举例来说,相比于SISD(一条指令仅处理单个数据)4个数组元素的加法会涉及4次load操作,4个加法操作,4个存储操作。而如果使用128位的SIMD 整数加法,则可以并行load数据,及 SIMD ADD操作,如此进行4个数的加法仅需一条指令(即一个指令周期)完成4个数的加法。
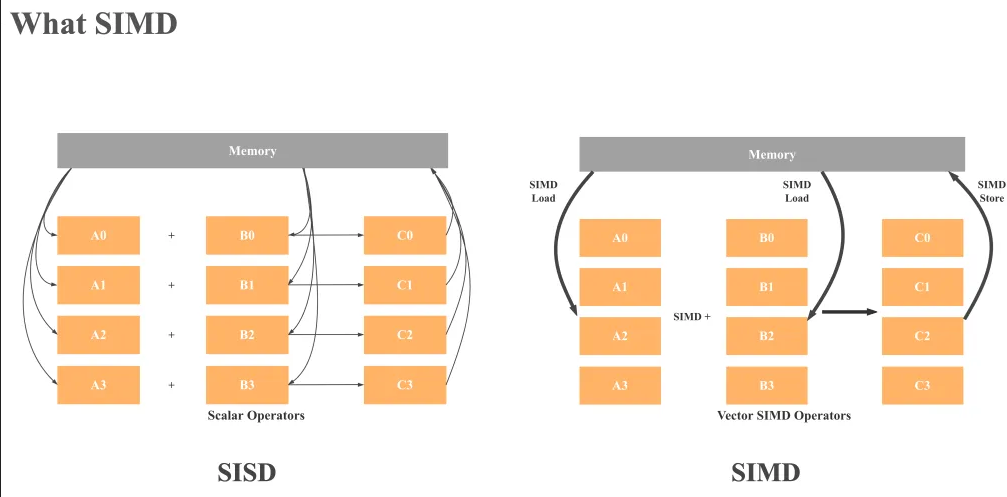
对此网上类似的说法有很多,但须注意可能对“指令周期”和“时钟周期”的概念的混淆。SIMD这里突出的是单个“指令周期”,建议对于特定的SIMD操作应参照Intel Intrinsics guide查看一条指令真正占用多少个时钟周期。对于本例子的SIMD add,为便于理解,可以简单认为并行执行add可以比SISD“获得4倍性能提升”(理论值、理想情况)。其他的SIMD的好处还包括帮助实现减少branching、提供去分支的代码实现(减少branch mispredict)。
SIMD执行需要硬件支持,目前大部分主流的指令级架构ISA都提供了SIMD支持,比如x86的AVX、ARM的NEON
x86: MMX, SSE, SSE2, SSE3, SSE4, AVX, AVX2, AVX512 、ARM: NEON, SVE 、RISC-V: RVV
在Linux 命令查看本机支持的指令集。

不同机器的CPU对指令集的支持情况不一,对程序开发人员的影响就是需要注意编译环境和运行环境的一致,这关乎程序能否正确运行或达到预期的效果。比如,编程时基于AVX-512等指令集进行了相关函数的底层实现,并在支持AVX-512特性的机台上完成了编译和测试(例如编译出了一些binary或library)。尽管在该台机器可以运行,但当移至只支持到AVX2的机台上,这些基于AVX-512特性的实现无法执行AVX-512对应汇编指令从而报错(例如illegal instruction非法指令)。
由于总是希望在当前运行的机台上,尽可能使用最好的SIMD指令集(组合)来实现程序中所需的逻辑,比如希望使用AVX-512的compressd实现高效的数据Filter功能,但又因为可能在任何一台机器上运行而无法确定运行时CPU的指令集支持,现在的一些大型开源项目中可以看到相关的实践是引入运行时分配,即在编写、编译期给出多个不同的程序版本,在运行时即时去判断underlying机台的支持状况,自行选择尽可能最优的底层实现。
实现方法
实现SIMD编程的方式由引用的网图可以主要分为自上至下5种,自上至下使用的难度逐渐增加,但自主可控制程度也逐渐提升。
编译器自动向量化 指的是编译器在侦测到代码满足一系列条件后,会尝试使用SIMD指令重写。例如一些执行较简单操作的loop循环,这种优化被称为自动向量化(auto vectorization)。这对数据的相互不依赖、内存对齐等有很多要求。
编译器向量化提示 Compiler Hint
提供额外信息,编译器可以转换更多SIMD代码。
使用SIMD库(或封装了SIMD的)
一些包装了启用SIMD指令的第三方库,具有较好抽象+易用的优势
使用SIMD intrinsics
由Intel c++编译器提供的SIMD intrinsics函数,是一组汇编码函数扩展
直接编写汇编代码
This method demands high expertise in programming.
如此多的实现方式,关于自主可控和易用性的balancing,一些论文中提出、建议了对于good practice是使用自动向量化 + Intel Intrinsics 混用的方式
实际应用
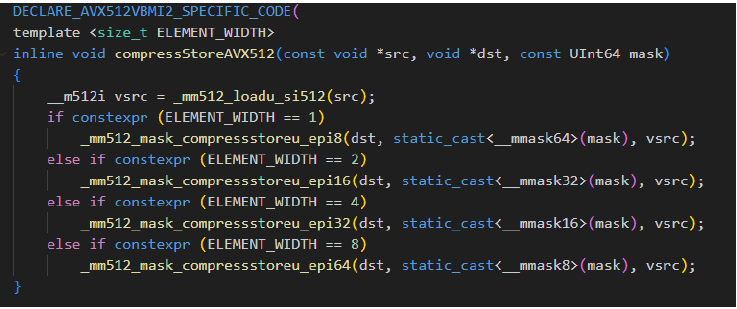
ClickHouse中有一些SIMD的应用。可以参考他们如何处理Aggregation 的SUM操作,其中有个addMany方法在运行时依靠cpuid指令即时判断机器支持的指令集,从而灵活选择不同的(最优)实现,处理方式就是 对同一个函数额外编译针对不同架构指令集支持的多个版本,这是在源码中看到的一系列Macro标识函数是MULTITARGET的。这样的好处是显而易见的,首先是保持与旧硬件的兼容性,再一个关键就是针对不同运行时机器的指令集尽可能执行最优的SIMD指令组合。

ClickHouse中的Filter实现也能见到很多SIMD的应用。

总结
SIMD是硬件级别数据并行执行特性;SIMD编程的工程实践可能一般编译期自动优化 + 手动编写SIMD intrinsics混合使用,可以参考Intel Intrinsics 和 GCC/CLANG的官方文档;注意编译和运行时环境的硬件支持状况。
SIMD能否达到预期收益也是一直需要考虑的问题,一般现在多见和列存、向量化执行结合使用,就是因为列存的数据访问方式是CPU cache friendly的,这就便于SIMD发挥作用,设想如果随机访问居多,数据总是在从内存load进CPU,SIMD的收益就会被这些动作拖累,导致无法获得预期的性能提升。其他一些挑战还包括AVX-512与intel CPU降频的问题。
