


优化Go语言中的缓存性能:减少缓存未命中提高执行效率
在现代计算中,CPU缓存的有效利用直接影响程序的性能。CPU需要从主存(内存)读取数据,而这往往是一个缓慢的过程。本文将介绍如何通过优化数据结构,减少缓存未命中,从而提高程序的运行效率。
CPU缓存结构
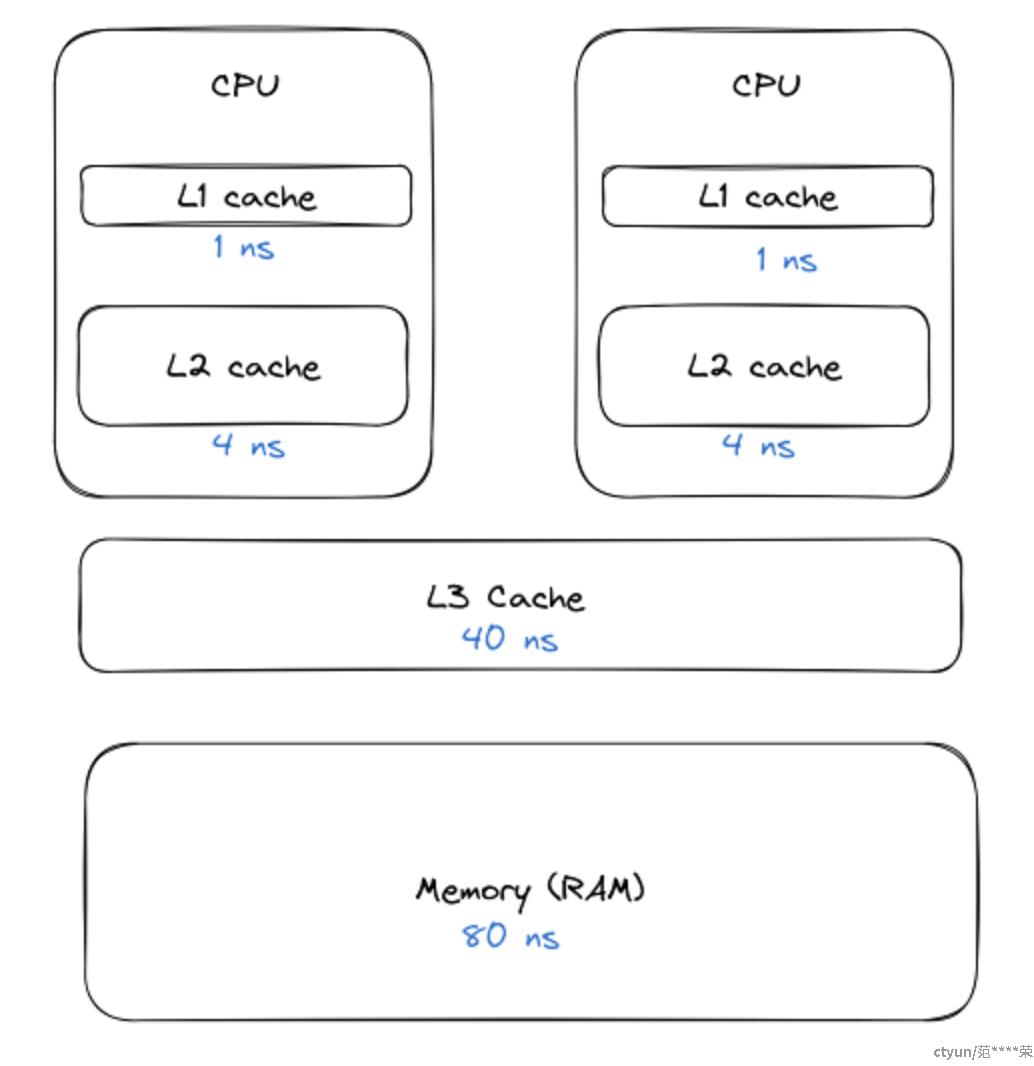
处理器在访问数据时,会依赖不同级别的缓存。通常,L1缓存是每个CPU独立拥有的,它提供最快的访问速度,而L3缓存则是所有CPU共享的。根据Intel架构,L3缓存维护L1和L2缓存中的数据副本。访问主存比L1缓存慢大约80倍,因此将数据尽量保存在更靠近处理器的缓存中是提高性能的关键。
问题示例:用户结构体的缓存未命中
我们通过一个简单的Go结构体来展示缓存问题的影响。假设我们有一个User结构体,其中包含一个128x128字节的图片数据:
type Image [128 * 128]byte
type User struct {
Login string
Active bool
Icon Image
Country string
}
在这个例子中,Icon字段的大小为16KB,而我们可能需要处理成千上万个用户实例。这些用户数据很难全部装入L1或L2缓存中,这会导致频繁的缓存未命中,进而降低性能。
为了验证这一点,我们编写了一个简单的API,用来统计每个国家的活跃用户数:
func CountryCount(users []User) map[string]int {
counts := make(map[string]int)
for _, u := range users {
if !u.Active {
continue
}
counts[u.Country]++
}
return counts
}
我们对这段代码进行了基准测试,基准测试代码:
var users []User
func init() {
const size = 10_000
countries := []string{
"AD",
"BB",
"CA",
"DK",
}
users = make([]User, size)
for i := 0; i < size; i++ {
users[i].Active = i%5 > 0 // 20% non active
users[i].Country = countries[i%len(countries)]
}
}
func BenchmarkCountryCount(b *testing.B) {
for i := 0; i < b.N; i++ {
m := CountryCount(users)
if m == nil {
b.Fatal(m)
}
}
}
并获得了以下结果:
$ go test -bench . -benchtime 10s -count 5
goos: linux
goarch: amd64
pkg: users
cpu: 12th Gen Intel(R) Core(TM) i7-1255U
BenchmarkCountryCount-12 4442 2630315 ns/op
BenchmarkCountryCount-12 4143 2814090 ns/op
BenchmarkCountryCount-12 3848 2642400 ns/op
BenchmarkCountryCount-12 4255 2639497 ns/op
BenchmarkCountryCount-12 4131 2661188 ns/op
PASS
ok users 67.257s
平均每次操作耗时约为2.67ms,对于某些场景可能已经足够,但如果需要更高的性能,我们必须分析缓存未命中的问题。
分析缓存未命中
通过使用perf工具,我们可以捕获缓存未命中情况:
$ perf stat -e cache-misses ./users.test -test.bench . -test.benchtime=10s -test.count=5
在运行基准测试时,缓存未命中数达到了数十亿次。由于User结构体过大,导致它无法完全装入L1或L2缓存,因此每次访问都会产生大量缓存未命中。
优化策略:使用切片代替数组
为了减少缓存未命中,我们可以对结构体进行优化。将Icon字段从一个16KB的数组改为一个引用切片,这样每个User实例的大小将大幅缩小,从而更多的用户数据能够同时存入缓存中。
修改后的结构体如下:
type Image []byte
type User struct {
Login string
Active bool
Icon Image
Country string
}
我们在初始化时为每个用户分配内存来存储图片数据:
for i := 0; i < size; i++ {
users[i].Active = i % 5 > 0
users[i].Country = countries[i % len(countries)]
users[i].Icon = make([]byte, 128*128)
}
优化效果
通过再次运行基准测试,性能有了显著提升:
$ go test -bench . -benchtime=10s -count=5
goos: linux
goarch: amd64
pkg: users
cpu: 12th Gen Intel(R) Core(TM) i7-1255U
BenchmarkCountryCount-12 189669 63774 ns/op
BenchmarkCountryCount-12 185011 63880 ns/op
BenchmarkCountryCount-12 188542 63865 ns/op
BenchmarkCountryCount-12 187938 64261 ns/op
BenchmarkCountryCount-12 186956 64297 ns/op
PASS
ok users 63.364s
每次操作的平均耗时降至64微秒,性能提高了约41.8倍。此外,缓存未命中数也显著减少,从数十亿次降低到了数百万次。
结论
在大型数据结构的场景中,合理地选择数据结构以及减少数据占用的缓存空间是优化程序性能的有效手段。通过减少缓存未命中,我们可以显著提升代码的执行效率。在实际开发中,使用工具如perf来分析性能瓶颈,并针对性地优化数据结构是提升系统性能的关键方法。
