Pooler进程是Teledbx的内部连接池,它是一个独立进程,入口是PoolManagerInit,下面从几个方面介绍一下pooler相关的内容。
一、Pooler线程模型
Pooler是多线程架构,主线程负责新的连接建立以及连接请求的处理和分发,采用poll IO多路复用。新的连接到来时,会为这个连接分配一个agent用来保存上下文。poll每次返回时,需要遍历agent,找出有事件到来的agent,解析请求的命令。然后根据命令的属性等因素,决定命令是否是在主线程处理,如果不是在主线程处理,则把请求分发给其他线程组处理。Pooler中分为如下几类线程:
主线程PoolerLoop:接收postgres backend的请求,处理一些非IO请求,并对请求进行分发,根据不同的请求类型发送往不同的线程组。
同步IO处理线程组pooler_async_utility_thread:处理主线程分发的命令,包括同步的连接建立和连接状态管理请求等。
异步连接IO线程组pooler_async_connection_management_thread:处理异步的批量IO操作,主要是异步连接建立和关闭。
辅助线程组pooler_sync_remote_operator_thread:负责处理连接管辅助功能,包括连接预热,连接内存占用检测等功能。
二、Pooler 连接管理
Pooler中相应的连接存储在DatabasePool中,一个dbpool对应一组数据库和用户名的组合,dbpool在用户首次登陆这个数据库时创建,使用哈希表来管理该用户往各个节点的对应数据库的连接池。每个节点的连接池存放在以nodeid为键的哈希表中。
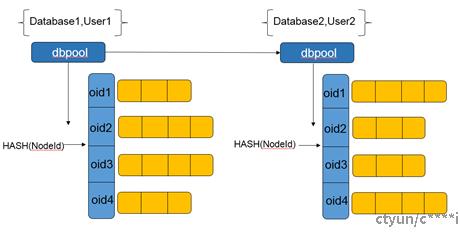
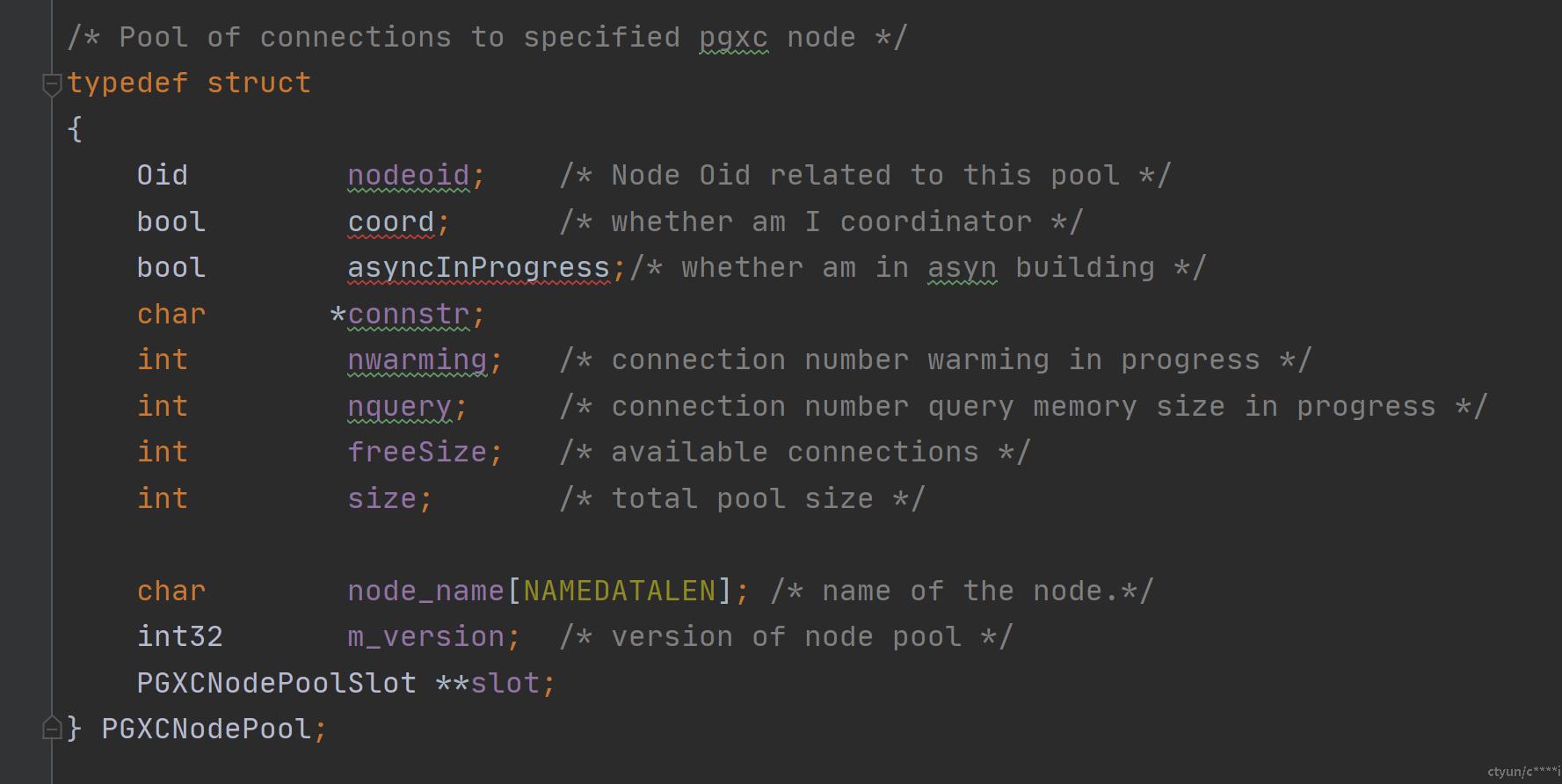
如上图所示,各个dbpool使用一个链表维护,每个dbpool有自己一个哈希表nodePools,哈希表里面存储的是一个个PGXCNodePool,一个PGXCNodePool就对应一个Oid,在使用的时候根据database和username找到dbpool,再根据oid找到PGXCNodePool。PGXCNodePool里面采用PGXCNodePoolSlot的数组来存放连接,一个PGXCNodePoolSlot对应着一个连接。在nodepool初始化时以MaxPoolSize来初始化slot数组,以nodepool为粒度维护着连接个数和空闲连接个数。Slot数组里面都是空闲的连接,当连接被申请走时,连接对应的slot槽位会被置为NULL,如果是agent申请走的,连接会挂在对应的agent上面。
三、Pooler 命令流程
主线程处理命令的入口是agent_handle_input,根据不同的命令走不同的处理流程。这里以获取连接为例介绍pooler命令的执行流程。
agent_handle_input中首先获取qtype,得到命令类型,根据命令类型走不同处理流程。获取连接时在handle_get_connections解析需要获取的nodeid,根据nodeid:
1) 在agent已经获取的连接中查找,agent会把已经拿到的连接存放在dn_connections和coord_connections中
2) 如果agent上没有,则在dbpool中根据nodeid查找,如果找到,则从dbpool中获取一个连接
3) 如果dbpool中没有空闲连接,则把请求分发给pooler_sync_remote_operator_thread线程,由该线程处理获取连接的操作
4) 如果要获取的所有连接在主线程都能直接拿到,则主线程直接把连接返回给客户端(backend),如果有些连接是分发给pooler_sync_remote_operator_thread线程处理,则需要在pooler_sync_remote_operator_thread线程中等所有分发任务处理完后由pooler_sync_remote_operator_thread线程将连接返回给客户端(backend)。
5) 获取连接时,会根据需要扩充线程池,主线程触发一个内部命令COMMAND_CONNECTION_BUILD,请求分发到
pooler_async_connection_management_thread线程处理,该线程异步批量创建连接,然后将连接返回给主线程,主线程在下次主循环前,调用pooler_sync_connections_to_nodepool将新创建的连接加到dbpool里面。
Pooler两种命令处理流程如下所示:

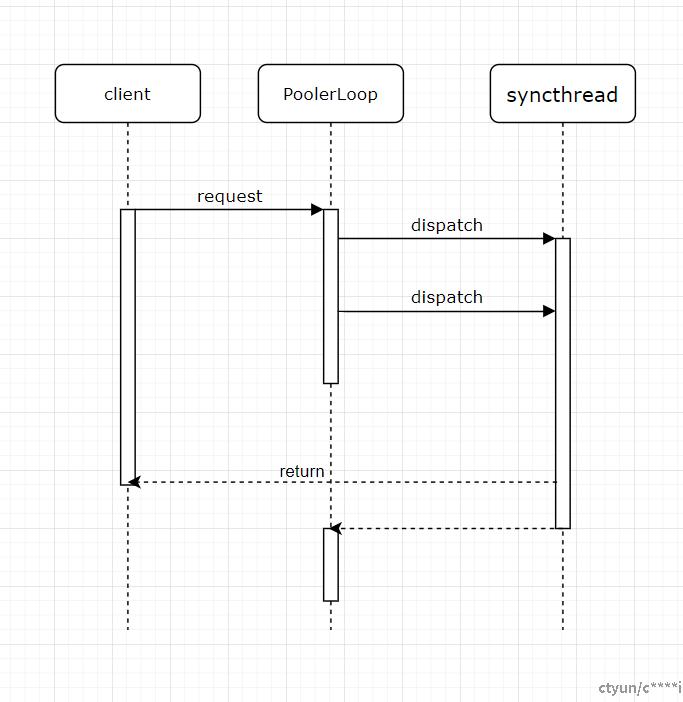
四、Pooler 请求分发
主线程和线程组之间的通信方式为消息队列和信号量。
1) 请求分发
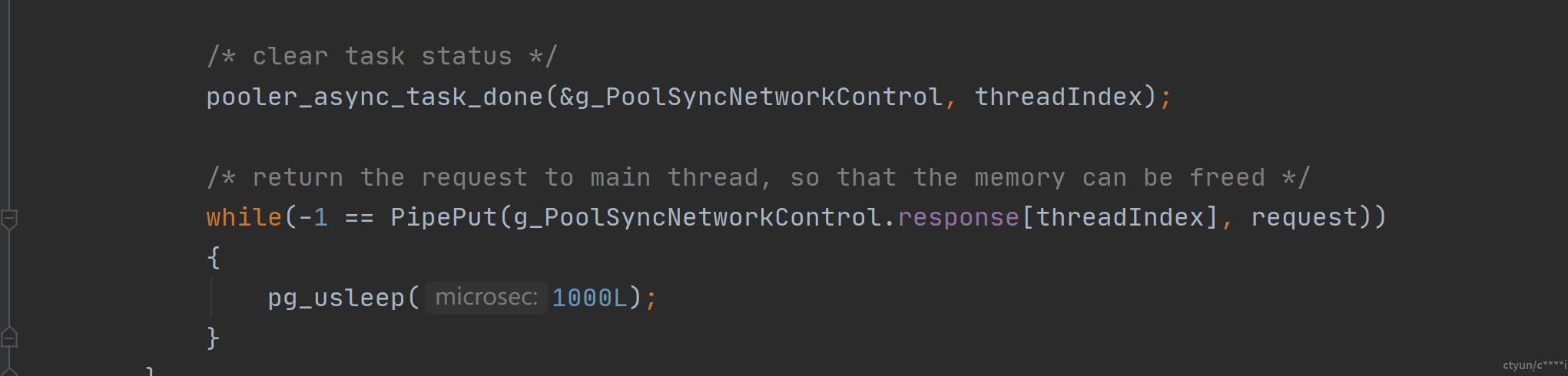
当需要进行请求分发时,会把请求的消息封装成一个个PGXCPoolAsyncReq,把请求相应的上下文存在req里面,然后使用pooler_async_task_pick_thread在线程组中选择一个线程,将req放到该线程的消息队列里面。 主线程收到的一个命令请求时,可能会分解成若干个req分发给其他线程处理,由PGXCASyncTaskCtl记录任务的状态等信息。
在线程创建的时候,会为该线程创建一个PGPipe类型的请求队列和响应队列,以及一个信号量,把req放到请求队列里面后,就使用信号量唤醒响应的线程来处理请求。
2) 请求处理与回复
pooler_sync_remote_operator_thread等线程平时就在信号量处等待,当信号量被唤醒时,在请求队列里面取出请求,根据请求的类型和上下文对请求进行处理,因为一个请求可能被分解为若干个独立的子任务,因此在最终回复客户端之前需要等待所有的子任务都处理完,所有任务处理完后就由改线程将处理结果回复给客户端(backend)。

3) 响应主线程
子线程中的任务处理完了之后,还会将主线程分发的req返回给主线程。主线程在每次主循环的pooler_handle_sync_response_queue中处理,释放相应的内存。