


在机器翻译任务中,BLEU 和 ROUGE 是两个常用的评价指标,BLEU 根据精确率(Precision)衡量翻译的质量,ROUGE 根据召回率(Recall)衡量翻译的质量,而Meteor 是为解决BLEU标准中的一些固有缺陷,基于单精度的加权调和平均数和单字召回率的一种度量方法。
Bleu
Bleu 全称为 Bilingual Evaluation Understudy(双语评估研究),意为双语评估替换,是衡量一个有多个正确输出结果的模型的精确度的评估指标。比较候选译文和参考译文里的 n-gram 的重合程度。多用于翻译质量评估。
核心思想是比较候选译文和参考译文里的 n-gram 的重合程度,重合程度越高就认为译文质量越高。unigram用于衡量单词翻译的准确性,高阶n-gram用于衡量句子翻译的流畅性。 实践中,通常是取N=1~4,然后对进行加权平均。
BLEU 需要计算译文 1-gram,2-gram,...,N-gram 的精确率,一般 N 设置为 4 即可,公式中的 Pn 指 n-gram 的精确率。
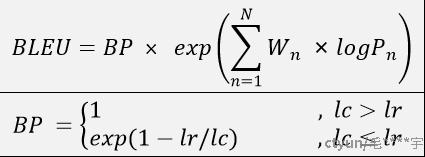
其中,Wn 指 n-gram 的权重,一般设为均匀权重,即对于任意 n 都有 Wn = 1/N。BP 是惩罚因子,如果译文的长度小于最短的参考译文,则 BP 小于 1。lc机器翻译的长度,lr最短的参考译文的长度。
ROUGE
ROUGE指标是在机器翻译、自动摘要、问答生成等领域常见的评估指标。ROUGE通过将模型生成的摘要或者回答与参考答案(一般是人工生成的)进行比较计算,得到对应的得分。ROUGE指标与BLEU指标非常类似,均可用来衡量生成结果和标准结果的匹配程度,
Rouge-N实际上是将模型生成的结果和标准结果按N-gram拆分后,计算召回率。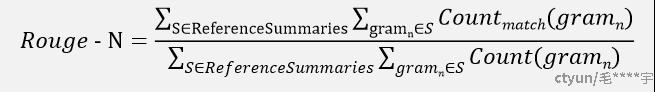
分子表示所有样本的标准结果按N-gram拆分后与生产结果按N-gram拆分后匹配上个数的和;分母表示所有样本的标准结果,按N-gram拆分后的和。
Rough-1
Rouge-1 即 N=1 情况下的 Rouge-N
Rough-2
Rouge-2 即 N=2 情况下的 Rouge-N
Rough-L
Rouge-L的L表示: Longest Common Subsequence,Rouge-L的计算利用了最长公共子序列。最长公共子序列与最长公共子串有些不同,这个是连续的,子序列不一定连续,但是二者都是有词的顺序的。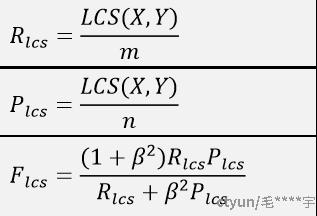
上面的公式中,X表示标准答案,长度为m,Y表示生成答案,长度为n;LCS(X,Y)表示X和Y的最长公共子序列;R表示召回率;P表示精准率;β是一个超参数,需要自己设置,一般设的比较大。
METEOR
为解决BLEU标准中的一些固有缺陷,基于单精度的加权调和平均数和单字召回率的METEOR度量方法。
同时METEOR将词序纳入评估范畴,设立基于词序变化的罚分机制,当待测译文词序与参考译文不同时,进行适当的罚分。最终基于共现次数计算准确率、召回率与F值,并考虑罚分最终得到待测译文的METEOR值。

其中,公式(1)中 P和R分别是unigram 情况下的准确率和召回率计算方式与BLEU、ROUGE类似,基于P和R值得到调和均值F值 ;
公式(2) 中的 #chunks 表示匹配上的语块个数,如果模型生成的译文很碎的话,语块个数会非常多;#unigrams_matched 表示匹配上的unigram个数。
公式(3) 即为考虑罚分后的METEOR值
参考文章
NLP评估指标之ROUGE
【NLG】(一)文本生成评价指标——BLEU原理及代码
“重磅!” 常见的NLG评估方法大整理 !!
