AI模型及权重数据在训练及推理过程中是结构化的数据,当这些数据保存到磁盘时需要进行序列化处理而从磁盘加载时需要进行反序列化的处理。不同的序列化方法即对应了不同的模型格式,这里介绍常见的pytorch pt格式和hugging face的safetensor格式。
pytorch模型格式
pytorch模型采用pickel方式来保存文件,可以采用torch.save来保存并采用torch.load来加载。
pytorch可以导出的模型的几种后缀格式,但是模型导出的关键并不是后缀,而是导出时提供的信息到底是什么,只要知道了模型的`model.state_dict()`和`optimizer.state_dict()`,以及相应的epoch batch_size loss等信息,我们就能够重建出模型,
| 保存场景 | 保存方法 | 文件后缀 |
|---|---|---|
| 整个模型 | model = Net() torch.save(model, PATH) | .pt .pth .bin |
| 仅模型参数 | model = Net() torch.save(model.state_dict(), PATH) | .pt .pth .bin |
| checkpoints使用 | model = Net() torch.save({ 'epoch': 10, 'model_state_dict': model.state_dict(), 'optimizer_state_dict': optimizer.state_dict(), 'loss': loss, }, PATH) | .pt .pth .bin |
| ONNX通用保存 | model = Net() model.load_state_dict(torch.load("model.bin")) example_input = torch.randn(1, 3) torch.onnx.export(model, example_input, "model.onnx", input_names=["input"], output_names=["output"]) | .onnx |
| TorchScript无python环境使用 | model = Net() model_scripted = torch.jit.script(model) # Export to TorchScript model_scripted.save('model_scripted.pt') 使用时: model = torch.jit.load('model_scripted.pt') model.eval() | .pt .pth |
由于pt格式采用的采用的python pickel方式来进行序列化和反序列化操作,而pickel加载外部数据本身存在安全性问题,python官方描述如下:
Warning
The `pickle` module **is not secure**. Only unpickle data you trust.
It is possible to construct malicious pickle data which will **execute arbitrary code during unpickling**. Never unpickle data that could have come from an untrusted source, or that could have been tampered with.
Consider signing data with hmac if you need to ensure that it has not been tampered with.
Safer serialization formats such as json may be more appropriate if you are processing untrusted data.
针对该问题,出现了safetensor格式
safetensor格式
safetensor格式是hugging face推出的一种安全格式,仅包括权重,可以防止文件中被恶意插入内容。
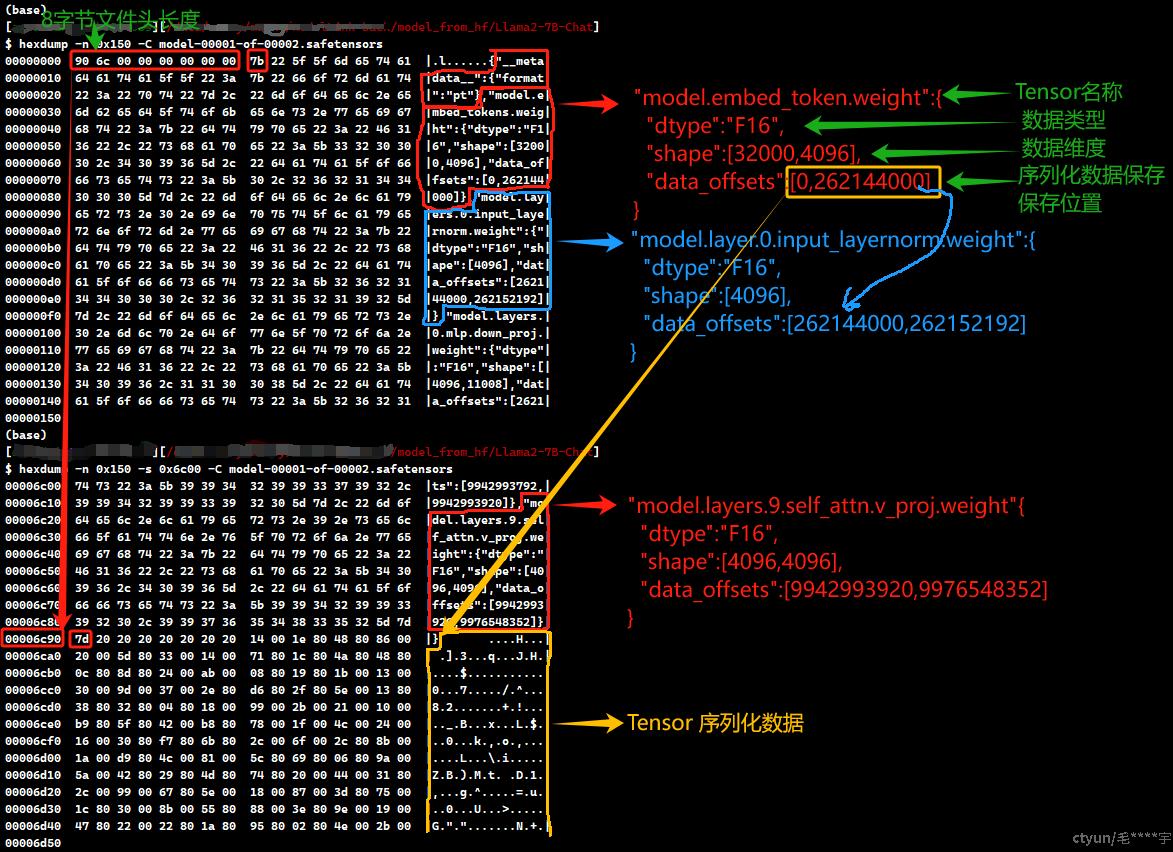
下面是文件格式简单解析
safetensor格式文件的前8字节是文件头长度信息,主要包括各tensor的描述信息,
首先是
"__metadata__": { "format": "pt" }
接下来为各tensor的描述信息
tensor名称:{
"dtype":数据格式, 数据格式可以是F16,BF16,F32,F64,I64,I32,I16,I8,U8,BOOL 等
"shape":[数据维度],
"data_offset":[起点位置,结束位置]
}
文件头信息之后即为各tensor的序列化数据。
一图胜千言,下图为采用hexdump命令导出的safetensors文件内容及注解