


RAG(Retrieval-Augmented Generation) 是一种结合了检索(Retrieval)和生成(Generation)的人工智能技术。这种方法通过增强语言模型(Language Model, LM)的能力,使其能够访问和利用外部知识库中的信息,从而生成更准确、更丰富的文本输出。
RAG的工作原理
1. 检索阶段:系统首先接收用户的查询(Query),然后从预先构建的知识库中检索出与查询相关的信息。
2. 生成阶段:检索到的信息被用作输入,结合用户的原始查询,生成模型据此生成回答或文本。
Query理解在RAG中的重要性
Query理解在RAG系统中扮演着至关重要的角色,主要体现在以下几个方面:提高检索准确性、处理自然语言的复杂性、适应用户表达的变化、处理复杂查询、提升用户体验
本篇文章将详细介绍以下几个问题:
1、 为什么要进行query理解;
2、 query 理解有哪些技术(从 RAG 角度);
为什么要进行query理解
1. 应对用户表达的模糊性: 自然语言的多样性和复杂性意味着同一词汇在不同上下文中可能指代不同的含义。Query理解赋予系统辨识并纠正这些潜在歧义的能力,确保系统能够准确捕捉用户的真实意图。例如,当用户询问“子龙是谁?”时,Query理解可以帮助系统区分用户是指历史上的赵云还是其他含义,甚至是某个特定的昵称。
2. 桥接Query与文档的语义差异: 用户习惯用非正式或口语化的语言提出Query,而知识库中的文档则倾向于使用正式的书面语言。Query理解在此发挥着桥梁作用,将用户的Query转化为与文档术语相匹配的表达,有效提升检索的召回率和准确性。例如,用户可能会问“手机坏了怎么办?”而文档中则可能使用“手机维修步骤”等术语。
3. 处理复杂的用户Query: 当用户提出涉及多个子问题或多个步骤的复杂Query时,Query理解能够将这些复杂Query拆解为更易于管理和回答的小问题。例如,面对“如何用Python分析数据并生成预测报告?”的Query,Query理解可以将之拆分为“如何用Python分析数据?”和“如何生成预测报告?”两个子问题,分别检索并生成回答。
Query理解的关键步骤
● 意图识别:分析Query的上下文,明确用户的真正需求。
● 术语转换:将用户Query中的非正式表达转换为知识库中的正式术语。
● Query分解:将复杂的Query分解为多个子问题,逐一解决以提供全面的回答。
通过Query理解,RAG系统不仅提高了检索的准确性和效率,而且生成的回答也更加精准和相关,极大地提升了用户的满意度和体验。
query 理解有哪些技术(从 RAG 角度)
在RAG架构中,掌握Query理解技术对于优化信息检索的效率和精确度至关重要。本文将重点介绍三种主流的Query理解策略:Query改写、Query增强和Query分解,它们构成了Query理解的核心。下面将详细介绍这几种方法:
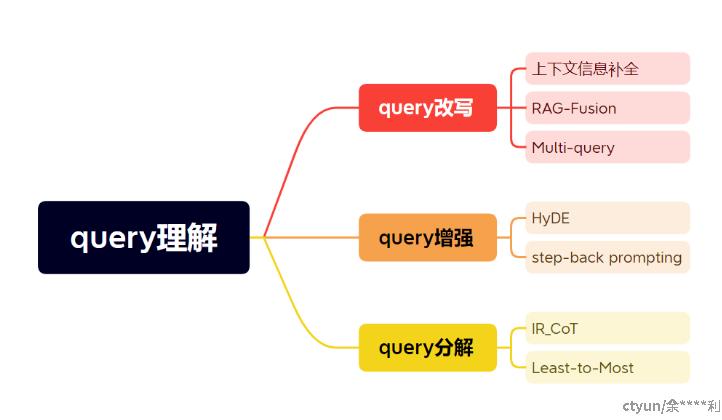
query改写
上下文信息补全
在连续对话的场景中,用户常常会使用指代词或省略部分信息,例如用「它」来指代之前讨论过的对象。这种表达方式如果没有适当的上下文支持,系统可能难以把握用户的真正意图,造成理解上的偏差,进而影响到信息检索的准确性。
为了解决这一问题,可以采用上下文信息补全的策略。这不仅包括对话历史,还涵盖了对话发生的时间、地点等背景要素。利用先进的大型语言模型(LLM),我们可以对用户的Query进行智能重构,将隐含于上下文中的关键信息融入到改进后的Query中,以此确保系统能够更全面地理解用户的询问,并有效地检索出相关联的信息。
上下文信息补全可以提高 query 的清晰度,使系统能够更准确地理解用户意图,不过,因为需要多调用一次 LLM,会增加整体流程的 latency 问题。因此,我们也需要权衡计算复杂度和延迟的问题。
RAG-Fusion
RAG Fusion 的设计宗旨在于增强搜索的精确度和周全性。这一方法的精髓在于,从用户的原始Query出发,创造性地衍生出多个角度的Query,以此捕捉Query的多元维度和细节差异。随后,利用逆向排名融合技术(Reciprocal Rank Fusion,简称RRF),对这些不同Query的搜索结果进行综合处理,形成一个整合后的排名列表。这样的处理不仅优化了搜索结果的排序,也提升了关键文档在最终排名中优先展现的几率。
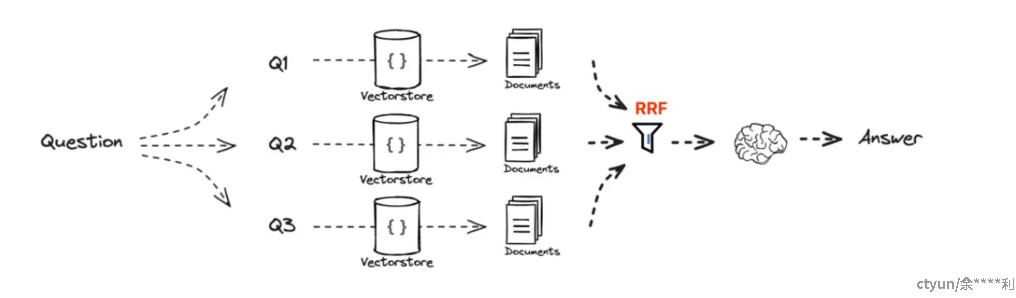
RAG Fusion 的操作流程可概括为以下几个阶段,如图例所示:
1. 多角度查询生成:初始步骤是直接依据用户提交的Query执行搜索。然而,单一Query可能过于狭窄,不足以覆盖全面的信息。为此,利用大型语言模型(LLM)对原始Query进行扩展,创建出一系列多样化的查询,这有助于拓宽搜索范围,深化搜索内容。
2. 逆向排名融合(RRF):这是一种高效的技术,它通过整合来自不同检索系统的排名列表,来提升整体搜索结果的质量。RRF通过对各系统返回的排名进行加权平均,形成一个统一的排名,从而提高相关文档排名的优先级。此方法的优势在于无需依赖训练数据,能够广泛应用于多种检索场景,并在多项测试中显示出超越传统融合技术的性能。
3. 创造性内容生成:在文档经过重新排名之后,将这些文档连同Query一起输入到LLM中。利用LLM的能力,可以创造出结构化的、富有洞察力的答案或者摘要,为用户提供更加深入和全面的信息。
这一连贯的流程确保了RAG Fusion在处理复杂查询时,能够提供更为精确和全面的信息检索结果。
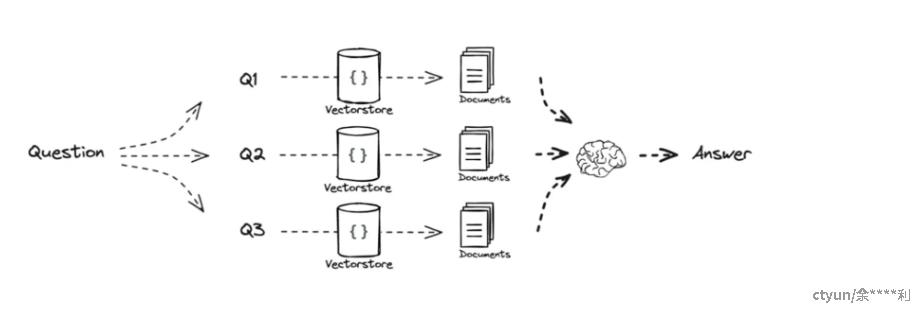
Multi-query
与RAG Fusion技术相似,MultiQuery方法也致力于通过创建基于单一用户Query的多个不同查询视角来检索文档。它依靠LLM来扩展用户的原始Query,生成一系列多样化的查询,并对每个查询进行检索,以收集相关文档。最终,这些文档被汇总,形成一个内容更为丰富的文档集。
不同于RAG Fusion采用的逆向排名融合(RRF)技术,MultiQuery选择将各个查询的搜索结果直接整合到上下文中。这种方法的优势在于它能够在上下文中保留更多的搜索结果,从而为用户提供了一个更为详尽的信息源,同时简化了排名融合过程的复杂度。通过这种方式,用户能够接触到更广泛的信息,这有助于他们更全面地理解问题并找到解答复杂问题的答案。
query增强
HyDE
RAG系统中的向量检索通常依赖内积相似度来衡量查询(query)与文档(doc)之间的相似性。然而,这种方法面临一个挑战:查询和文档往往不处于同一语义空间。将它们向量化并通过向量相似性进行检索,可能会导致检索精度有限且引入较多噪声。为了克服这一问题,一种解决方案是通过大量标注数据训练嵌入函数。
HyDE(Hypothetical Document Embeddings,假设性文档嵌入)技术提供了一种无监督的替代方案。它基于一个核心假设:与查询相比,由大型语言模型(LLM)直接生成的假设性回答与文档在语义空间上更为接近。
HyDE的工作流程如下:
1. 生成假设性回答:针对查询,HyDE首先生成一个假设性文档或回答(hypo_doc)。
2. 向量化处理:将这个假设性回答进行向量化。
3. 检索相似文档:利用向量化的假设性回答检索与其语义接近的文档。
通过这种方式,传统的query-doc检索转变为query-hypo_doc-doc检索,使得hypo_doc和doc在语义空间上更可能接近,从而在一定程度上提高了检索的精确度和相关性。
以一个具体例子来说明:如果用户询问“如何提高睡眠质量?”,HyDE可能会生成一个假设性回答,如“提高睡眠质量的方法包括保持规律的睡眠时间、避免咖啡因和电子设备等。”这个假设回答经过编码后,可能与知识库中关于睡眠改善的文档内容(如避免晚上喝咖啡或使用电子设备)更为接近,从而更容易找到相关文档。
HyDE的优势包括:
1. 简化了在单一向量空间中学习两个嵌入函数的复杂性。
2. 利用无监督学习直接生成和使用假设文档。
3. 即便在缺乏标注数据的情况下,也能显著提升检索的准确性和效率。
然而,HyDE也存在局限性。其假设性回答的质量高度依赖于LLM的生成能力。如果生成的回答不准确或不相关,可能会影响检索效果。特别是在讨论对LLM来说较为陌生的主题时,这种方法可能不太有效,甚至可能增加生成错误信息的风险。
step-back prompting
Step-back prompting技术致力于增强大型语言模型(LLM)在抽象推理方面的表现。它通过促使LLM在直接回答问题之前,先进行深入的思考和抽象,将复杂问题提升至更高层次的问题,从而实现更有效的推理。
这一技术包含两个关键步骤:
1. 抽象化(Abstraction):在直接回答问题之前,LLM被引导形成一个更高维度的「回溯问题」,这个问题关联到更广泛的高级概念或原则,并围绕这些概念或原则搜集相关的事实信息。
2. 推理过程(Reasoning):在已经建立的高级概念或原则框架下,利用LLM内在的推理机制,对最初的问题进行深入的逻辑推导。这种方法也被称作基于抽象的推理(Abstraction-grounded Reasoning)。
研究者们已经在包括STEM、知识问答(Knowledge QA)和多跳推理(Multi-Hop Reasoning)等具有挑战性的推理密集型任务中,对Step-Back Prompting进行了测试。涉及的模型包括PaLM-2L、GPT-4和Llama2-70B,实验结果显示在各类任务中均有显著的性能提升。例如,PaLM-2L在MMLU(涵盖物理和化学领域的测试)上的性能提升了7%至11%,在TimeQA上提升了27%,在MuSiQue上提升了7%。
Step-Back Prompting技术特别适合于那些需要进行复杂推理的领域,包括:
• STEM领域:解决涉及物理、化学等科学原理的应用问题。
• 知识问答:处理需要大量事实性知识储备的问题。
• 多跳推理:应对需要通过多个步骤或信息源串联起来进行推理的复杂问题。
query分解
IR-CoT
IR-CoT(Interleaving Retrieval with Chain-of-Thought Reasoning),是一种用于解决多步骤问题(Multi-Step Questions)的技术。IR-CoT 通过交替执行检索(retrieval)和推理(reasoning)步骤来提高大型语言模型(LLMs)在处理复杂问题时的性能。
IR-CoT 的核心思想是将检索步骤与推理步骤相结合,以指导检索过程并反过来使用检索结果来改进推理链(Chain-of-Thought, CoT)。论文作者认为,对于多步 QA 任务,单纯基于问题的一次性检索是不够的,因为后续检索的内容取决于已经推导出的信息。
IR-CoT的工作流程如下:
1. 初始化检索:使用问题作为查询,从知识库中检索一组相关段落。
2. 交替执行两个步骤:
● 扩展 CoT:利用问题、到目前为止收集的段落和已经生成的 CoT 句子来生成下一个 CoT 句子。
● 扩展检索信息:使用上一个 CoT 句子作为查询来检索额外的段落,并将它们添加到已收集的段落集中。
3. 重复上述步骤:直到 CoT 报告答案或达到最大允许的推理步骤数。
4. 终止:返回所有收集的段落作为检索结果,并使用这些段落作为上下文,通过直接 QA 提示或CoT 提示来回答原始问题。
Least-to-Most
Least-to-Most prompting 也可以用于解决多步推理的问题,它将复杂问题分解为一系列更简单的子问题,并按顺序解决这些子问题。
Least-to-Most prompting 包括两个主要阶段:
1. 分解(Decomposition):在这个阶段,将复杂问题分解为更简单的子问题。
2. 子问题解决(Subproblem Solving):在这个阶段,使用之前解决的子问题的答案来帮助解决当前子问题。
这种方法的核心思想是将问题分解为可管理的步骤,并利用逐步构建的答案来指导模型解决更复杂的问题。
