


概况
Amoro是基于开放数据湖格式构建的Lakehouse管理系统。Amoro与Flink、Spark和Trino等计算引擎合作,为Lakehouse带来了可插拔和自我管理的功能,提供开箱即用的数据仓库体验,并帮助数据平台或产品轻松构建内部解耦、流与批量融合和湖原生架构。
架构
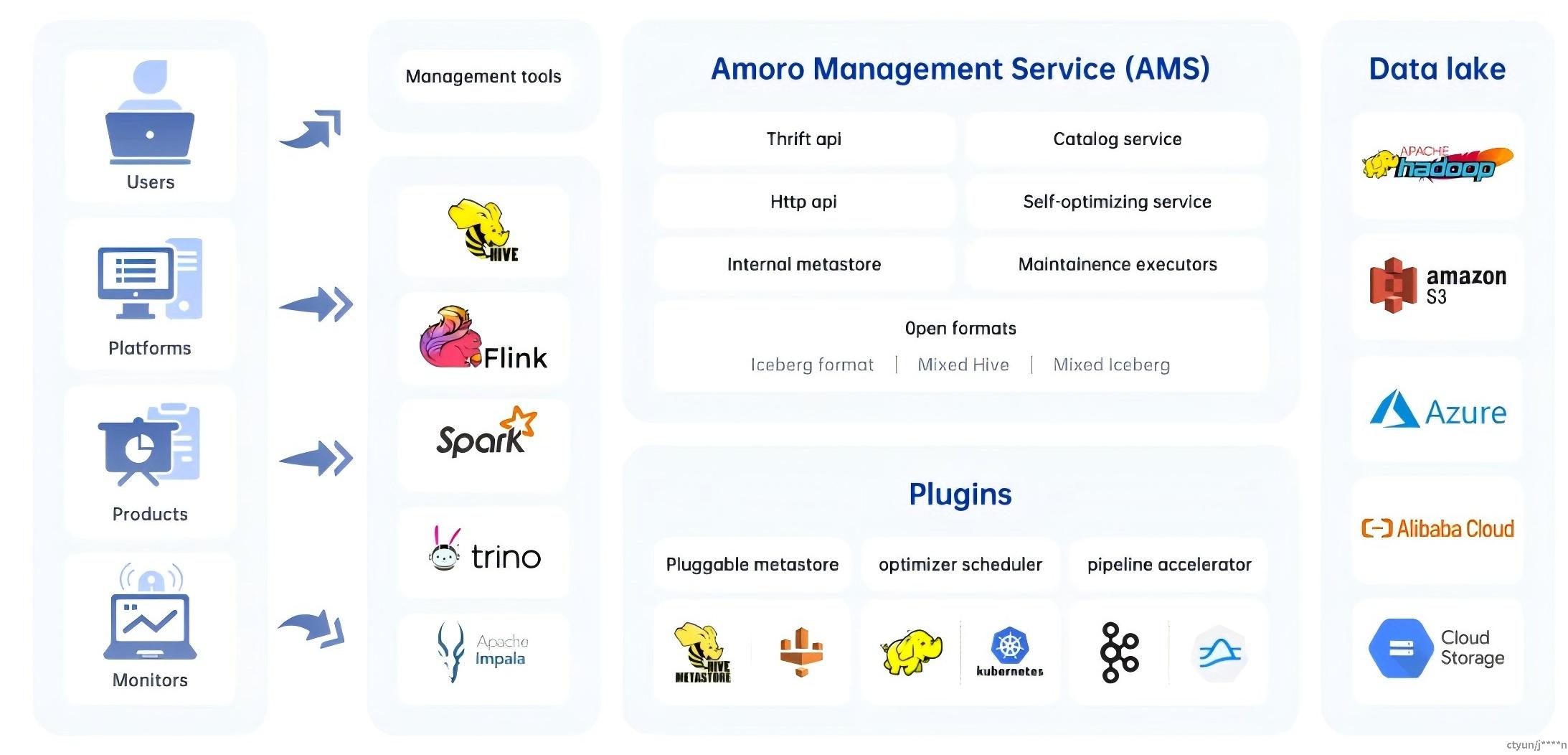
Amoro 的核心组件包括:
- AMS:Amoro 管理服务提供 Lakehouse 管理功能,例如自优化、数据过期等。它还为所有计算引擎提供统一的目录服务,可以与现有元数据服务结合使用。
- 插件: Amoro 提供大量外部插件,以满足不同场景的需求。
- 优化器Optimizers: 自优化执行引擎插件异步执行对所有类型表格式表的合并、排序、去重、布局优化等操作。
- Terminal终端: SQL 命令行工具,提供local模式Spark 和 Kyuubi 等多种实现。
- LogStore:提供毫秒到秒级的 SLA,用于实时数据处理消息队列,如基于 Kafka 和 Pulsar 等消息队列。
支持的表格式
Amoro 可以管理不同表格式的表格,类似于 MySQL/ClickHouse 选择不同的存储引擎。Amoro 通过使用不同的表格式来满足不同的用户需求。
目前,Amoro 支持三种表格式:
- Iceberg 格式 : 使用 Apache Iceberg 的原生表格式,具备 Iceberg 的所有功能和特性。
- Mixed-Iceberg格式 : 基于 Iceberg 格式构建,利用 LogStore 加速数据处理,在 CDC 场景下提供更高效的查询性能和流式读取能力。
- Mixed-Hive 格式 : 具有与Mixed-Iceberg表相同的特性,但与 Hive 表格兼容。支持将 Hive 表格升级到Mixed-Hive表格,升级后允许使用 Hive 原生的读写方法。
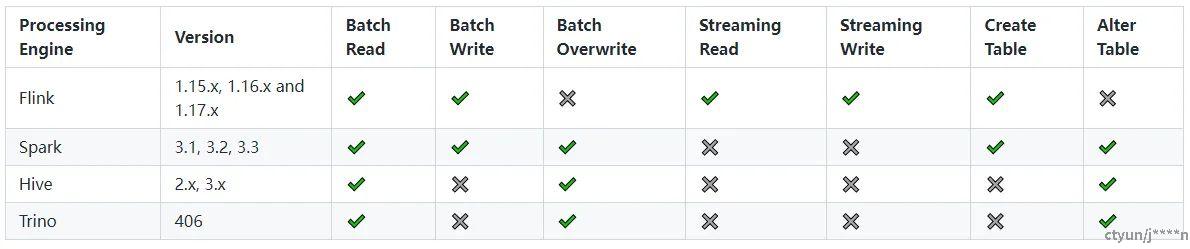
支持的引擎
-
Iceberg格式:有关详细信息,可参考:[Iceberg官网]
-
Paimon格式:派蒙格式表使用派蒙社区提供的引擎集成方法。有关详细信息,可参考:[paimon官网]
-
混合格式
概念
Catalogs
catalog是一个元数据命名空间,用于存储有关数据库、表、视图、索引、用户和 UDF 的信息。它为表和数据库提供了一个更高级别的命名空间。通常,一个catalog与特定类型的数据源或集群相关联。在 Flink、Spark 和 Trino 中,多目录功能可用于支持跨数据源的 SQL。
在之前的版本中,数据湖通常使用 Hive Metastore (HMS) 来管理元数据。不幸的是,HMS 不支持多目录,这限制了数据湖上引擎的功能。例如,一些用户可能希望使用 Spark 在不同的 Hive 集群中进行跨目录联合计算,通过指定目录名称,要求他们在上层开发一个 Hive 目录插件。此外,数据湖格式正在从单一的以 Hive 为中心的模式转变为像 Iceberg、Delta 和 Hudi 这样的竞争格式的格局。这些新的数据湖格式更加云友好,将有助于将数据湖迁移到云端。在这种情况下,需要一个支持多目录的管理系统来帮助用户管理不同环境和格式的数据湖。
使用方法
在实际应用中,建议创建以下目录:
-
如果想用HMS,建议选择 Hive 作为 Metastore,并根据表的格式选择 Mixed-Hive 或 Iceberg 作为格式。
-
如果想使用 Amoro 提供的 Mixed-Iceberg 格式,建议选择 Amoro 作为 Metastore
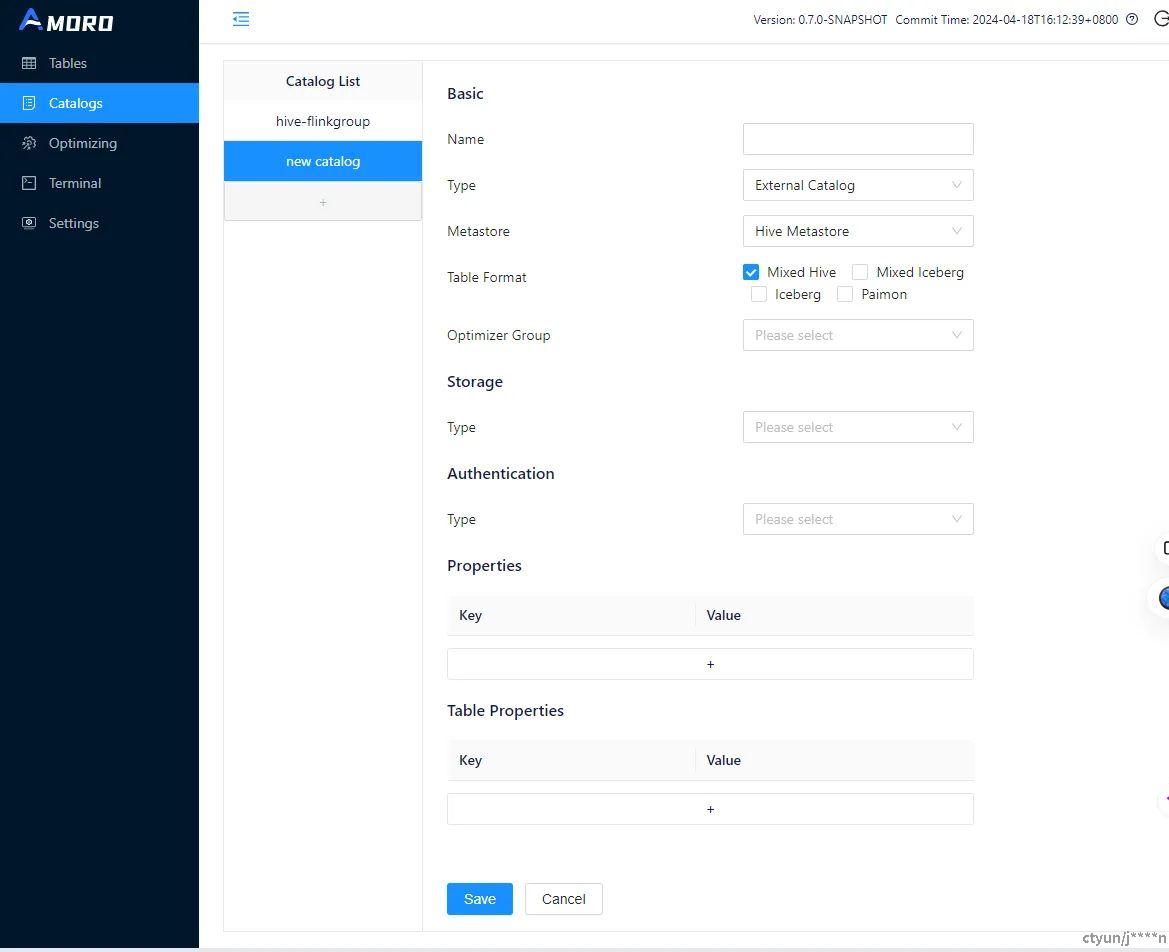
目前,创建 Amoro 目录时只能选择一种表格格式。这主要是因为引擎在使用目录时会将其解析为特定数据源,而一对一格式更直观。另一方面,使用 HMS 直接操作时,可以绕过这一限制,例如 Iceberg 社区提供的 SessionCatalog 实现。未来,Amoro 将考虑为用户提供更灵活的管理方法。
未来优化
- 扩展数据源: 除了数据湖之外,消息队列、数据库和数据仓库都可以作为对象在元数据中心进行管理。通过元数据中心和计算引擎的 SQL 基于联邦计算,AMS 将为 DataOps 和 DataFabric 等数据平台提供基础设施解决方案。
- 自动目录检测: 在 Spark 和 Flink 等计算引擎中,可以自动检测目录的创建和更改,从而实现一次配置永久可扩展。
Self-optimizing自优化
概况
湖仓一体的特性在于其开放性和松耦合,数据和文件由用户通过各种引擎维护。虽然这种架构似乎非常适合T+1场景,但当更多关注将湖仓一体应用于流式数据仓库和实时分析场景时,就会出现挑战。例如:
- 流式写入会产生大量碎片文件
- CDC 摄取和流式更新会产生过多的冗余数据
- 使用新的数据湖格式会导致孤立文件和过期快照。
这些问题会严重影响数据分析的性能和成本。因此,Amoro 引入了自优化机制,以创建开箱即用的流式湖仓管理服务,该服务与传统数据库或数据仓库一样易于使用。为此,使用新的表格式。自优化包括文件压缩、去重和排序等各种流程。

优化器Optimizer是负责执行自优化任务的组件,它是一个由 AMS 管理的常驻进程。AMS 负责检测和规划表的自优化任务,并将其调度到优化器,以实时分布式执行。最终,AMS 负责提交优化结果。Amoro 通过优化器组实现了优化器的物理隔离。
Amoro 自优化的核心特点是:
- 自动化、异步和透明——持续后台检测文件变更,异步分布式执行优化任务,对用户透明且不可感知
- 资源隔离和共享——允许在表级别隔离和共享资源,以及设置资源配额
- 灵活可扩展的部署——优化器支持多种部署方式,方便扩展
自优化机制原理
存在问题
在数据写入数据的过程中,可能会出现两种类型的放大问题:
- 读放大:如果在写入过程中生成了过多的碎片文件,或者删除和插入文件的映射过多(对于使用 Iceberg v2 格式的用户来说可能是一个熟悉的问题),并且优化无法跟上碎片文件生成的速率,会导致读取性能显著下降。
- 写放大:频繁调度优化会导致频繁压缩和重写现有文件,从而导致资源竞争和 CPU/IO/内存浪费,减慢优化速度,并进一步加剧读放大。
频繁执行优化对于缓解读放大是必要的,但会导致写放大。自优化的设计需要在读放大和写放大之间进行权衡。
解决方案
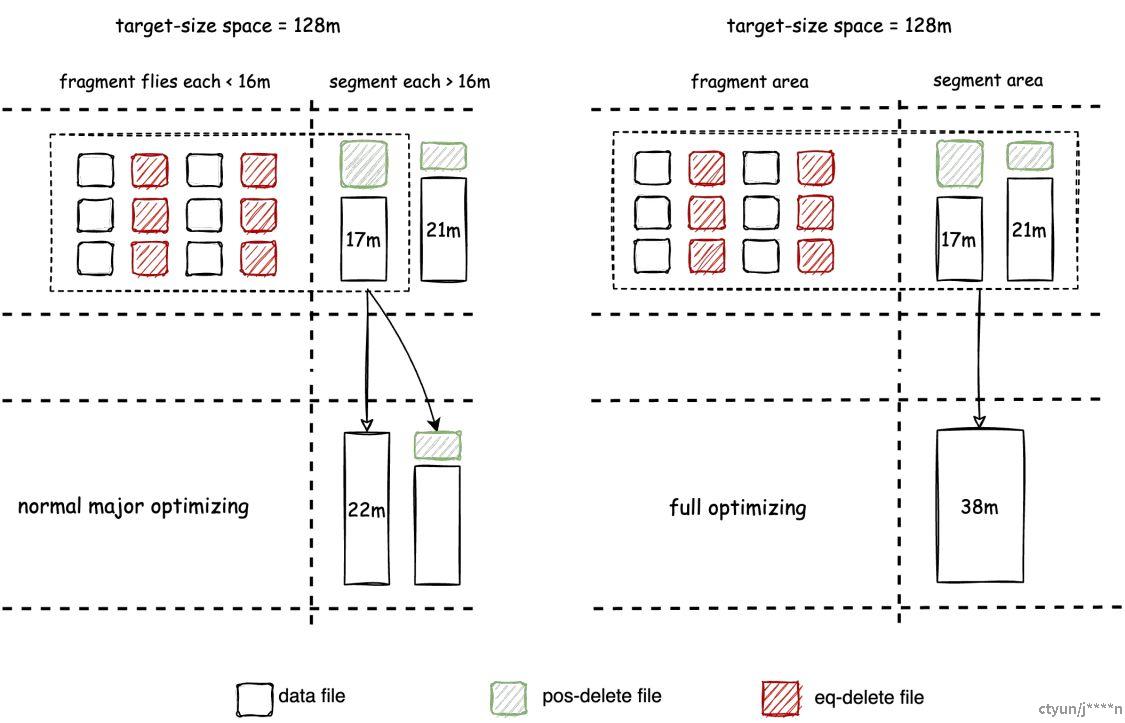
Amoro 的自优化借鉴了 JVM 中的分代式垃圾回收GGC算法。文件根据其大小被分为碎片和片段,在碎片和片段上执行的不同自优化过程分为两种类型:minor和major。两种优化执行逻辑一致,都包含文件压缩、数据去重和从写友好格式转换为读友好格式。
minor优化、major优化和完整优化的输入输出关系如表所示:

具体内容
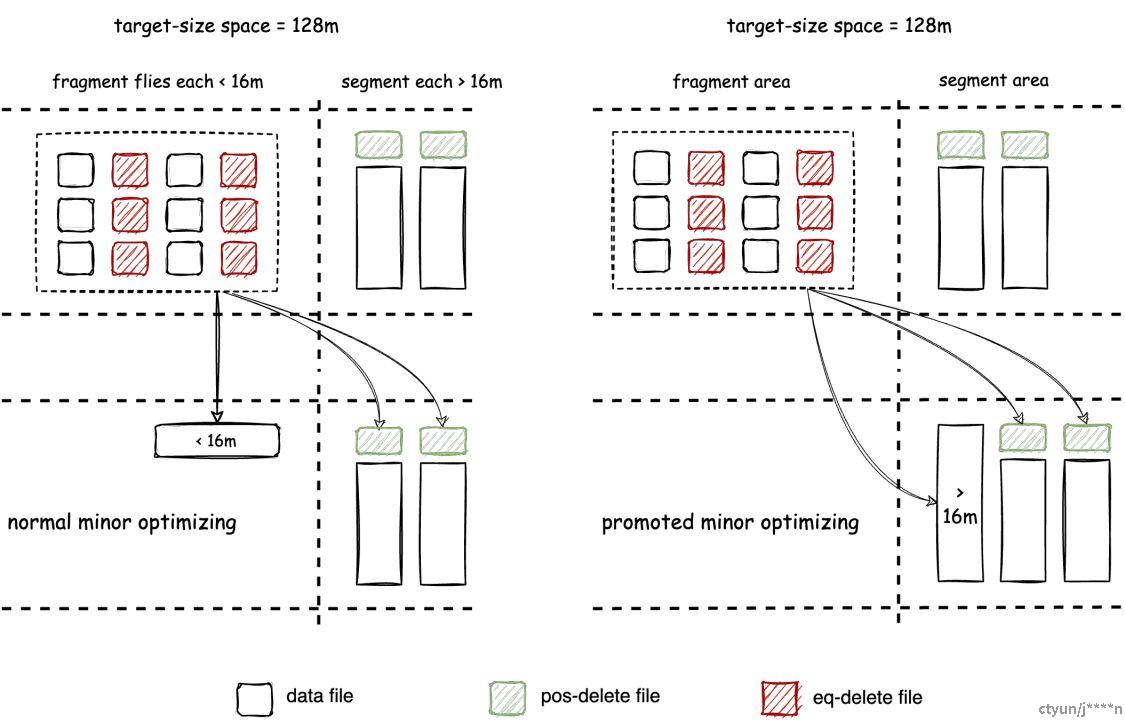
碎片和片段文件划分
Amoro v0.4 引入了两个参数来定义碎片Fragments和段Segments:
-- Target file Size for Self-optimizing
self-optimizing.target-size = 134217728(128MB)
-- The fragment file size threshold for Self-optimizing
self-optimizing.fragment-ratio = 8
self-optimizing.target-size定义了major优化目标的输出大小,默认设置为 128 MB。self-optimizing.fragment-ratio定义了片段文件阈值与目标大小的比例,值为 8 表示默认片段阈值是目标大小的 1/8,对于默认目标大小为 128 MB 的情况,则为 16 MB。
小于 16 MB 的文件被视为片段,而大于 16 MB 的文件被视为段,如下图所示:
碎片文件优化 - 解决读放大
minor优化旨在缓解读取放大问题,主要包括两个任务:
- 尽快将碎片文件压缩成段文件。 当碎片文件生成速度很快时,Minor 优化将更频繁地执行。
- 将写入友好的文件格式转换为读取友好的文件格式。 这涉及将混合格式的 ChangeStore 转换为 BaseStore,以及将 Iceberg 格式的 eq-delete 文件转换为 pos-delete 文件。
片段文件优化 - 解决写放大
多次执行 minor 优化后,表空间中将存在大量片段文件。尽管在大多数情况下,片段文件的读取效率可以满足性能要求,但仍可能存在以下问题:
- 每个片段文件上可能累积了大量的删除数据。
- 不同片段文件之间可能存在大量的重复主键数据。
在这个阶段,读取性能问题不再是由小文件大小和文件格式导致的读取放大问题引起的。相反,它是由大量冗余数据的存在造成的,这些数据需要在合并读取过程中进行合并和清理。
为了解决这个问题,Amoro 引入了major优化,它将片段文件合并以清理冗余数据并将其数量控制在有利于读取的水平。minor优化已经执行了多轮去重,major优化不会频繁安排,以避免写入放大问题。
此外,完整优化将目标空间中的所有文件合并成一个单一文件,这是major优化的特殊情况。
自优化调度策略
AMS 通过制定调度策略,确定对表格进行自优化的次序。为每个表格分配的实际自优化资源是根据所选择的调度策略确定的。
配额设置
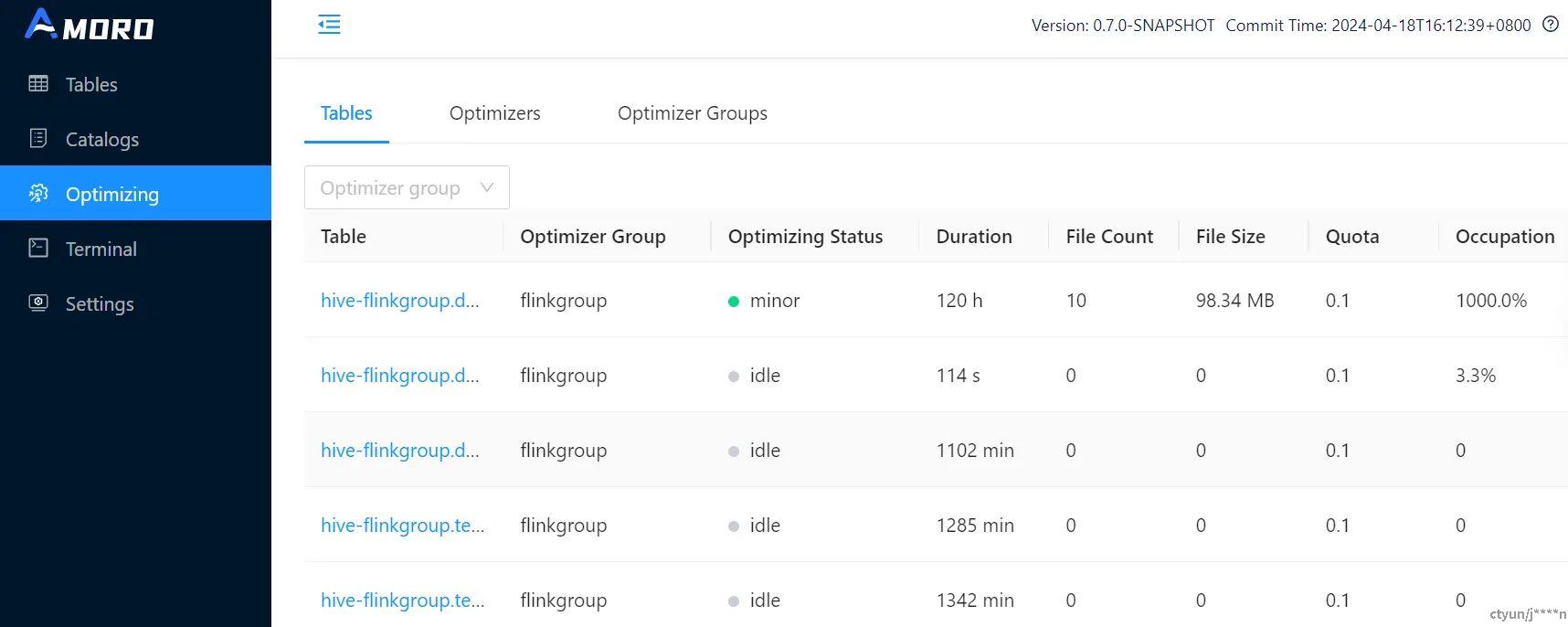
配额Quota:配额定义了单个表可以使用的最大 CPU 使用率,但自优化实际上以分布式方式执行,实际资源使用情况根据实际执行时间动态管理。在优化管理 Web UI 中,可以通过“Quota Occupy”指标查看单个表的动态配额使用情况。从设计角度来看,配额占用指标应该动态地接近 100%。
配额占用率Quota occupation:表示实际资源使用情况相对于预期使用情况的百分比。
在平台中,可能会出现两种情况:超卖和超买。
- 超卖 - 如果所有optimizer配置超过所有表配置的总配额,则配额占用指标可能会动态地接近 100% 以上
- 超买 - 如果所有optimizer配置都低于所有表配置的总配额,则配额占用指标应该动态地接近 100% 以下
AMS 页面可以查看每个表格的自优化配额和配额占用率:
对于单个表的配额,通过以下参数进行配置
-- Quota for Self-optimizing, indicating the CPU resource the table can take up
self-optimizing.quota = 0.1;
平衡策略设置
平衡策略是一种基于时间进度的调度策略,未自优化时间较长的表具有更高的调度优先级。该策略旨在使每个表的自优化进度保持在相似的水平,从而避免高资源消耗的表长时间不进行自优化,影响配额调度策略下的整体查询效率。
如果优化器组内的表在资源使用上没有特殊要求,并且所有表都期望具有良好的查询效率,那么策略设置为Balance是一个不错的选择。
自优化的使用
对于单个表,设置以下参数,可以对该表禁用自优化
self-optimizing.enabled = false;
建议:
- 不可更新的表,例如日志或传感器数据,并且习惯于使用 Iceberg 提供的 Spark 重写操作,则可以关闭自优化。
- 对于配置了主键并支持 CDC 摄取和流式更新的表,建议开启自优化
表水印Watermark - 解决数据新鲜度问题
数据新鲜度代表时效性,在很多场景下,新鲜度被认为是衡量数据质量的重要指标之一。对于流式数据仓库来说,数据新鲜度、查询性能和成本构成了一个三元悖论。

Amoro 利用 AMS 管理功能和自优化机制,为用户提供了解决三方悖论的方案。与传统的数据仓库不同,Lakehouse 表格被广泛应用于各种数据管道、AI 和 BI 场景。衡量数据新鲜度对于数据开发人员、分析师和管理员至关重要,Amoro 通过在流计算中采用水印概念来解决这一挑战,从而评估表格新鲜度。
使用方式
表格水印watermark:是在表格上的一个timestamp属性,用于描述表格的写入进度。该timestamp表明比此水印早的时间戳的数据已写入表格。
- 用途:监控表格写入的进度,也可以作为下游批处理计算任务的触发指示器
- 适用场景:混合格式Mixed Format格式的表
- 配置参数:
'table.event-time-field' = 'op_time',
'table.watermark-allowed-lateness-second' = '60'
- 'table.event-time-field':用于计算watermark的表事件时间字段,本例中为
- 'table.watermark-allowed-lateness-second': 计算水印允许最大延迟秒数(本例中为60s),该延迟可解决由于乱序写入导致的数据写入顺序差异问题
实践
优化器组调优
可以为不同的优化器组配置不同的调度策略,以满足各种优化需求。
参考文献
Amoro官方文档
