


前言
最近要做一个分布式数据迁移服务,涉及到了分布式一致性的CAP,共识算法(Consensus Algorithm)等相关技术,这里大概学习记录下。
技术发展
传统业务服务架构
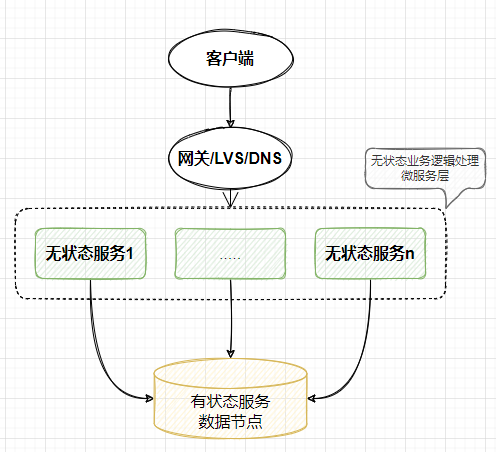
一些说明
1,业务系统一般分为无状态服务和有状态服务。无状态服务设计主要封装业务逻辑处理,可以水平横向扩展节点。有状态服务主要用于存储系统状态数据和逻辑中间数据,比如mysql,redis等。
2,有状态服务一般情况下使用单节点部署,而这样会存在高可用和单节点瓶颈性能问题。开发者便考虑给有状态服务做分布式处理。
分布式存储架构
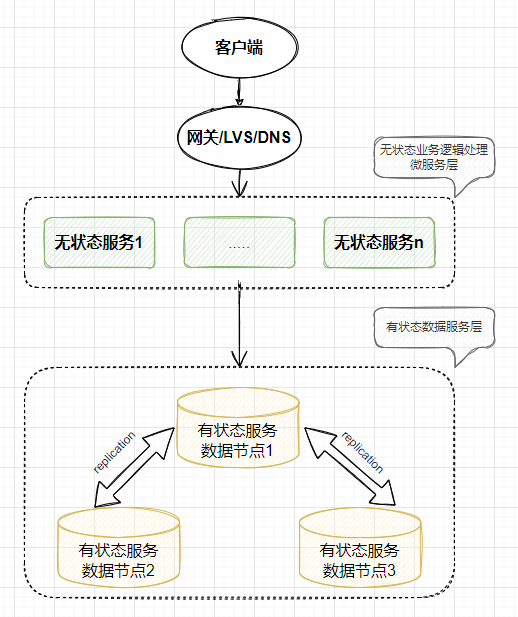
一些说明
1,无状态服务在分布式架构下,可以水平扩展。
2,有状态服务数据节点如果实现分布式,需要将多个同逻辑组的机器组合成一个整体对外服务。那问题在于:如何将多个有状态的节点组成一个整体对外服务。下面总结下思考过程。
CAP理论
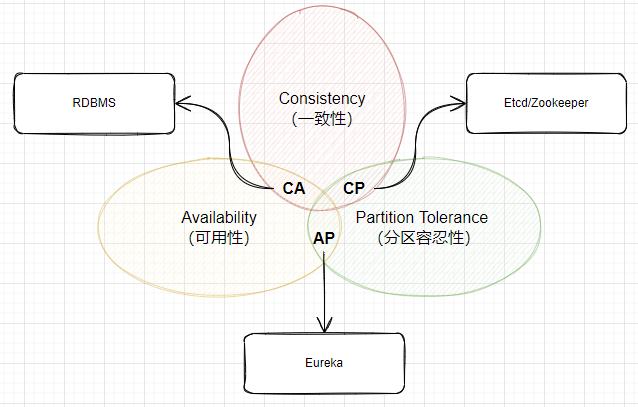
理论说明
在理解分布式系统前,必须要先了解CAP理论:一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance),CAP理论强调强一致性,线性一致性,真正做到多个节点作为一个完整的整体对外服务。需要注意的是CAP并不是一个算法,而是一种现实情况下分布式协议过程中的取舍理论;
一致性(Consistency):站在分布式系统的角度,对访问本系统的客户端的一种承诺:要么返回一个错误,要么返回绝对一致的最新数据,其强调的是数据正确。需要满足线性一致性读,也就是在t1更新操作完成之后,那么在 t1时间后,客户端一定能读到这个值,而不可能读到 t1之前的值。
可用性(Availability):分布式系统提供的服务必须处于100%可用状态。从分布式系统的角度,对客户端的承诺:一定会给返回数据,不会返回错误,不保证数据最新,强调不出错。
分区容错性(Partition tolerance):分布式系统下网络不是绝对可靠的。因此分区容错性表示对客户端承诺:服务会一直运行,不管服务内部出现何种数据同步问题,强调服务不会挂掉。如果为保证服务可对外服务,分区容错不可避免。网络不可能绝对可靠,在网络出现问题的情况下如果等待网络恢复,则无法保证可用性,如果不等待网络恢复,则无法保证一致性。
总之:CAP非算法,是一种分布式协议过程中的取舍。所以既要系统可用性,又要数据的实时可见,还要系统能分区容错能力这个是做不到的。因此在设计分布式系统的前提下,要么选择AP(DNS,Gossip,Eureka,Redis主从,Nacos注册中心),要么选择CP(ZAB协议的Zookeeper,Raft协议的ETCD,hazelcast等)。
BASE理论补充
BASE理论:Basically Available(基本可用)、Soft State(软状态)、Eventually Consistent(最终一致性)。BASE理论是对CAP理论的一个补充和妥协。对CAP理论中选择一致性还是可用性的一个权衡结果,对AP的一个补充,即在AP的情况下,如何根据自身系统业务特点,采用适当的方式来使系统达到最终一致性C。即使无法达到强一致性,但是系统可以选择合适的方式达到最终一致性。
Basically Available(基本可用):分布式系统在出现不可预知故障时,允许损失部分可用性。
Soft State(软状态):分布式系统中的数据允许存在中间状态,且该中间状态的存在不影响系统的整体可用性。
Eventually Consistent(最终一致性):分布式系统保证数据最终一致,不需要实时保证数据强一致性。
小结
综上所述,一切皆有成本,皆需取舍,CAP和BASE理论主要是规划分布式系统设计过程中的理论可行性模型。为开发者设计分布式系统提供了系统设计的能力目标模型,要么CP,要么AP,然后AP使用恰当的方法实现最终一致性的C。本文主要关注分布式一致性的CP实现思路,CP的实现算法有Paxos,ZAB,Raft。下文主要学习下Raft算法。
一致性协议
按FLP Impossibility定理,注意是定理!!!理论上在一个异步网络环境(消息传输的目标进程无法确定是否是运行慢还是故障了,消息传递的时间是没有边界的)中,即使只有一个节点发生故障也是不存在完整的分布式一致性算法。具体可以查看论文《Impossibility of Distributed Consensus with One Faulty Process》通过反证法的对这个问题做了了非常严谨的证明。但是现实的情况下是没有这样极端的异步环境的,可以通过多种经验的方法或者限制将异步的网络环境转换成同步的网络环境。论文的最后也说明了分布式一致性算法在更加精细的模型下也是可以实现的。

因此才有了后续大名鼎鼎的Paxos,Paxos能OK的核心是使用了随机超时时间(同步网络)来解决问题。paxos论文看简化版本的《Paxos Made Simple》即可。《The Part-Time Parliament》就不要看了简直是天书。

一致性协议(consensus protocol)也叫共识协议。主要为解决在节点规模增大,网络丢包,延迟,乱序,或者宕机,部分网络隔离的情况下分布式系统的数据的一致性,简而言之:一致性算法允许一组机器像一个整体一样工作,即使其中一些机器出现故障也能够继续工作下去,使各自节点的提议达成一致。一致性协议分为弱一致性和强一致性,强一致性算法中最重要的是分布式共识算法的根本Paxos算法,不过由于Paxos太过复杂,难于理解和工程实现,因此在Multi-Paxos理论基础上简化提出了Raft算法,更加简洁清晰,通俗易懂。Raft算法论文可以查看《In Search of an Understandable consensus Algorithm》。下面简单学习了解下Raft算法。
分布式一致性算法RAFT
一些资源

模块组成
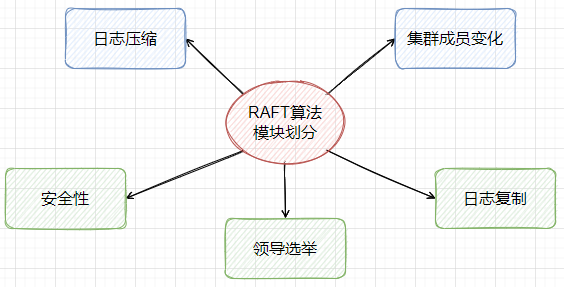
一些说明
下面的说明主要参考论文《Consensus:Bridging theory and practice》的说明,ETCD即按论文编写,所以这篇论文非常详细,更像是一个系统设计说明书。本文并不详细介绍Raft算法,这不是本文的主题,且raft算法已经在论文《Consensus:Bridging theory and practice》中写的非常详细了,不需要再做多余的说明。
1,raft算法将问题分为了领导选举(Leader election),日志复制(Log replication),安全性(Safety),集群成员变化(Cluster membership changes),日志压缩(Log compaction)等子问题。
2,领导选举(Leader election):Raft在当前任期内选举出唯一领导节点(Leader),领导节点接受客户端写请求(其实也包括读请求,不过一般工程实现上会让非主节点接受读请求,分担leader压力)并管理请求复制日志以保证其他节点间复制日志的一致性,同时领导节点会和其他节点(Follower)保持心跳信息,在其他节点没有收到领导节点的心跳信息后,且正好属于其选举时间内,则发起重新选举过程。
3,日志复制(Log replication):领导节点(Leader)在当前任期内赢得了选举后,则开始接收客户端的请求,然后将客户端请求的命令信息追加到日志文件文件中,然后发起AppendEntriesRPC请求其他节点同步这个最新的日志项。保证每个日志项,当这个日志成功完成复制后,领导节点将会把这个日志项写入到状态机(the state machine)中。
4,安全性(Safety):安全性主要是保证了任意Leader对于给定的Term,都拥有了之前Term的所有被提交的日志条目。Raft使用两条规则保证了安全性。a)只有拥有最新日志项的Follower节点才有资格选举为Leader,b)提交之前任期内的日志条目,领导节点(Leader)由于不能断定一个之前任期里的日志条目被保存到大多数服务器上的时候就一定已经提交了。提交之前term日志项时,必须保证当前term新建的日志项已经复制到超过半数节点。这样之前term的日志项才算真正提交;
5,集群成员变化(Cluster membership changes):在修改配置或者替换宕机的情况下,生产环境下不可能停服改配置重启。因此Raft算法提供了自动化配置改变并且将其纳入到Raft一致性算法中来。raft提供了联合共识(Joint Consensus),单节点成员变更(the single-server membership change),一般工程实现使用单节点成员变更方法。
6,日志压缩(Log compaction):日志压缩主要是为了处理不断增长的日志数据,使用快照的形式写入到稳定的持久化存储中,然后到那个时间点之前的日志全部丢弃。
总结
1,拜占庭将军问题概述了整个分布式系统理论的基础,如果需要达成分布式一致,不能有恶意节点。FLP Impossibility定理证明了在异步网络环境中,不存在完整的分布式一致性算法。CAP理论从网络的角度规定了要么AP,要么CP,不可能既要又要还要。而在这些分布式理论的基础上出现的Paxos和Raft算法提供了可工程化实现的技术方向。
2,Raft一致性算法允许一组机器像一个整体一样工作,即使其中一些机器出现故障也能够继续工作下去,使各自节点的提议达成一致。
3,Raft算法有多种著名的实现,比如ETCD,TiKV,Hazelcast,SOFAJRaft等。
