


视觉语言模型(Vision-Language Model,简称VLM)结合了计算机视觉和自然语言处理的技术,能够理解和生成图像与文本之间的关联。本文将综述基于transformer的最新VLM的四训练方法,并分析每种训练范式的性能和应用场景。其四种训练范式示意图下如图所示。
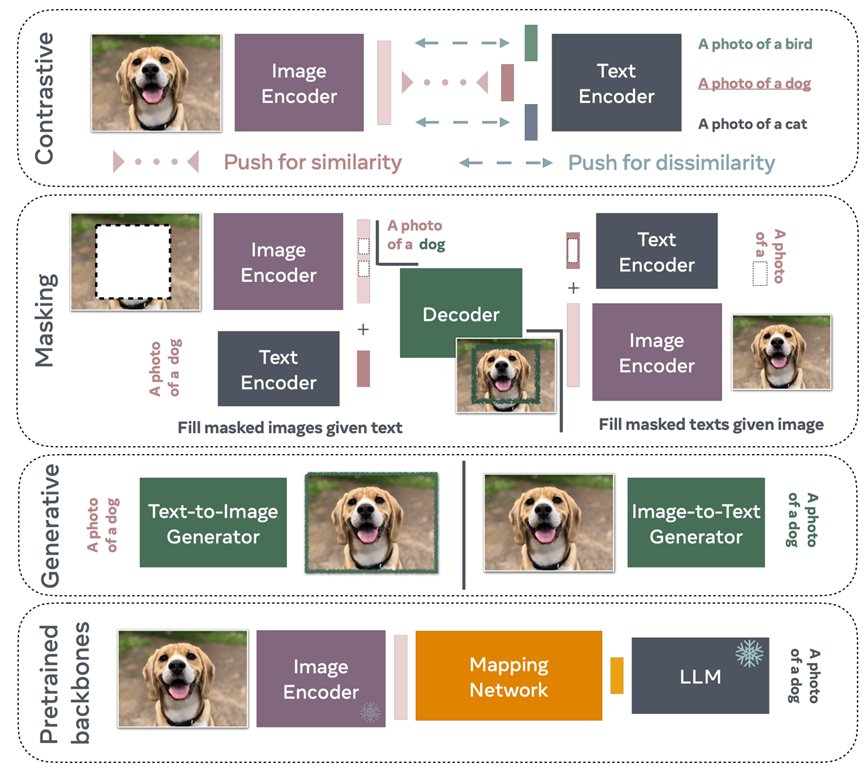
第一种是对比训练,这是一种常用的策略,它利用正例和负例对,然后训练VLM预测正例对的相似表示,同时预测负例对的不同表示。第二种是掩码,利用给定一些未掩码的文本重建掩码的图像块。类似地,通过掩码标题中的单词,可以训练VLM来重建给定未掩码图像的单词。第三种是基于在预训练主干上进行训练,模型通常会利用开源LLM(如Llama)来学习图像编码器(也可以进行预训练)和LLM之间的映射。学习预训练模型之间的映射通常比从头开始训练文本和图像编码器的计算成本更低。第四种是⽣成式VLM,虽然大多数这些方法都利用中间表示或部分重建,但该训练方式使其可以⽣成图像或字幕。鉴于这些模型的性质,它们通常是训练成本最高的。
对于以上四种训练VLM方法,现有模型有一些利用简单的对比训练标准,另一些使用掩膜策略来预测缺失的文本或图像块,而一些模型则使用生成范式,例如自回归或扩散。还可以利用预先训练的视觉或文本主干,例如Llama或GPT。在这种情况下,构建VLM模型只需要学习LLM和视觉编码器表示之间的映射。那么,在所有这些方法中,应该选择哪一种?我们是否需要像CLIP一样从头开始训练视觉和文本编码器,还是最好从预先训练的LLM(例如Flamingo或MiniGPT)开始。接下来将讨论在特定情况下应选择哪种类型的模型。
- 何时使用像CLIP这样的对比模型?
对比模型(如CLIP)将文本与视觉概念关联起来,同时保持简单的训练范式,将文本和图像表示推向表示空间进行匹配。通过这样做,CLIP学习在图像和文本空间中都有意义的表示,这使得我们能够用单词提示CLIP文本编码器,以便我们可以检索映射到相应文本表示的图像。
例如,许多数据管理流程(如MetaCLIP)正在使用元数据字符串匹配来构建数据集,以确保每个单词或概念都具有足够的相关图像。CLIP模型也是构建更复杂模型的良好基础,尤其是在尝试改进基础时。对于那些希望尝试其他训练标准或不同模型架构以更好地捕捉关系或更好地理解概念的研究人员来说,CLIP是一个特别好的起点。但是,CLIP不是生成模型,因此无法根据特定图像生成标题。只能在已经存在的标题列表中检索最佳标题。因此,当前的CLIP模型不能用于提供给定图像的高级描述。另一个缺点是,CLIP通常需要非常大的数据集以及较大的批量大小才能提供不错的性能,这意味着CLIP通常需要大量资源从头开始进行训练。 - 何时使用掩膜?
掩膜是训练VLM的另一种策略。通过学习从掩膜图像和文本中重建数据,可以联合建模它们的分布。相比之下与在表示空间中运行的对比模型相比,基于掩码的模型可能需要利用解码器将表示映射回输入空间(从而应用重建损失)。训练额外的解码器可能会增加额外的瓶颈,这可能会使这些方法的效率低于纯对比方法。
但是,这样做的好处是不再存在批次依赖性,因为可以单独考虑每个示例(因为不需要负面示例)。删除负面示例可以使用较小的mini-batch,而无需微调额外的超参数(例如softmax温度)。许多VLM方法利用了多种掩膜策略以及一些对比损失。 - 何时使用生成模型?
基于扩散或自回归标准的生成模型在根据文本提示生成照片级逼真图像方面表现出了令人印象深刻的能力。VLM上的大多数大规模训练工作也开始集成图像生成组件。一些研究人员认为,能够根据单词生成图像是朝着创建良好世界模型迈出的重要一步,而其他研究人员则认为不需要这样的重建步骤。然而从应用的角度来看,当模型能够解码输入数据空间中的抽象表示时,可能更容易理解和评估模型所学到的内容。
虽然像CLIP这样的模型需要使用数百万个图像数据点进行大量的k-NN评估才能显示最接近给定词嵌入的图像是什么样的,但生成模型可以直接输出最可能的图像,而无需如此昂贵的流程。
此外,生成模型可以学习文本和图像之间的隐式联合分布,这可能比利用预训练的单峰编码器更适合学习良好的表示。然而,与对比学习相比,它们的训练计算成本更高。 - 何时在预训练的主干上使用LLM?
当资源有限时,使用已经预训练好的文本或视觉编码器可能是一个不错的选择。在这种情况下,只需要学习文本表示和视觉表示之间的映射。然而,这种方法的主要问题是VLM将受到LLM的潜在幻觉的影响。它还可能受到来自预训练模型的任何偏差的影响。因此,在尝试纠正视觉模型或LLM的缺陷时可能会产生额外的开销。
有些人可能会认为,利用独立的图像和文本编码器将信息投影到较低维度的流形中很重要,我们可以在此流形上学习映射,而另一些人可能会认为,联合学习图像和文本的分布很重要。总而言之,当计算资源有限且研究人员对学习表示空间中的映射感兴趣时,利用预先训练的模型是很有趣的。
以上这些范式并不互相排斥,许多方法依赖于对比、掩膜和生成标准的混合,从而获得较好的模型性能。同时应针对任务类型、数据规模、计算资源选择最适合的模型架构与训练策略。
