


简述
朴素数据并行(DP)与分布式数据并行(DDP)。两者的总通讯量虽然相同,但DP存在负载不均的情况,大部分的通讯压力集中在Server上,而Server的通讯量与GPU数量呈线性关系,导致DP一般适用于单机多卡场景。而DDP通过采用Ring-AllReduce这一NCCL操作,使得通讯量均衡分布到每块GPU上,且该通讯量为一固定常量,不受GPU个数影响,因此可实现跨机器的训练。
我们将介绍由微软开发的ZeRO(零冗余优化),它是DeepSpeed这一分布式训练框架的核心,被用来解决大模型训练中的显存开销问题。ZeRO的思想就是用通讯换显存。
知识储备
我们来看在大模型训练的过程中,GPU都需要存什么内容:
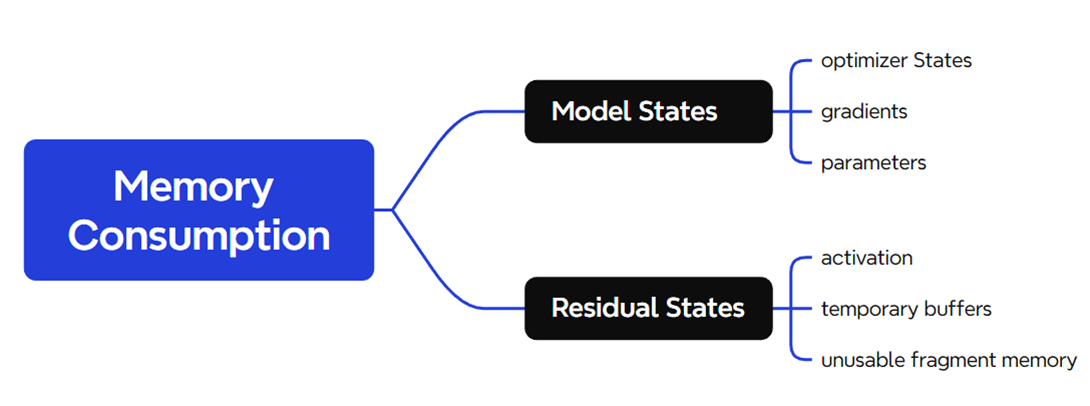
存储主要分为两大块:Model States和Residual States
Model States指和模型本身息息相关的,必须存储的内容,具体包括:
· optimizer states:Adam优化算法中的momentum和variance
· gradients:模型梯度
· parameters:模型参数W
Residual States指并非模型必须的,但在训练过程中会额外产生的内容,具体包括:
· activation:激活值。在流水线并行中我们曾详细介绍过。在backward过程中使用链式法则计算梯度时会用到。有了它算梯度会更快,但它不是必须存储的,因为可以通过重新做Forward来算它。
· temporary buffers: 临时存储。例如把梯度发送到某块GPU上做加总聚合时产生的存储。
· unusable fragment memory:碎片化的存储空间。虽然总存储空间是够的,但是如果取不到连续的存储空间,相关的请求也会被fail掉。对这类空间浪费可以通过内存整理来解决。
ZeRO-DP
知道了什么东西会占存储,以及它们占了多大的存储之后,我们就可以来谈如何优化存储了。
注意到,在整个训练中,有很多states并不会每时每刻都用到,举例来说;
· Adam优化下的optimizer states只在最终做update时才用到
· 数据并行中,gradients只在最后做AllReduce和updates时才用到
· 参数W只在做forward和backward的那一刻才用到
ZeRO想了一个简单粗暴的办法:如果数据算完即废,等需要的时候,我再想办法从个什么地方拿回来,就省了一笔存储空间,沿着这个思路,介绍ZeRO是如何递进做存储优化的。
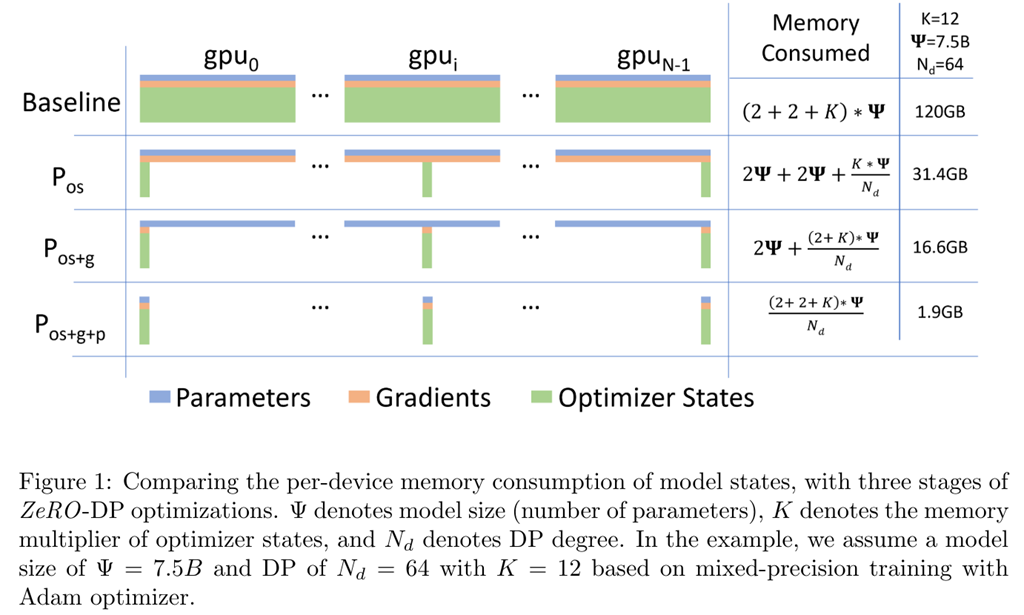
优化器状态分割
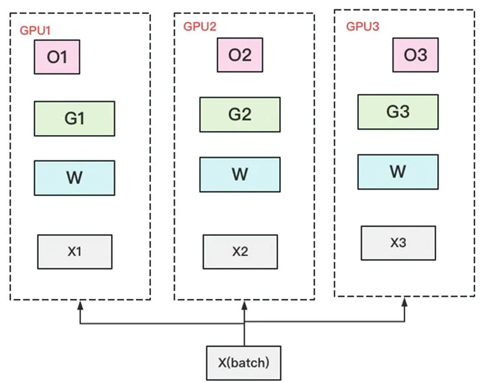
首先,从 optimizer state开始优化。将optimizer state分成若干份,每块GPU上各自维护一份。这样就减少了相当一部分的显存开销。如下图:
设GPU个数为Nd,显存和通讯量的情况如下:
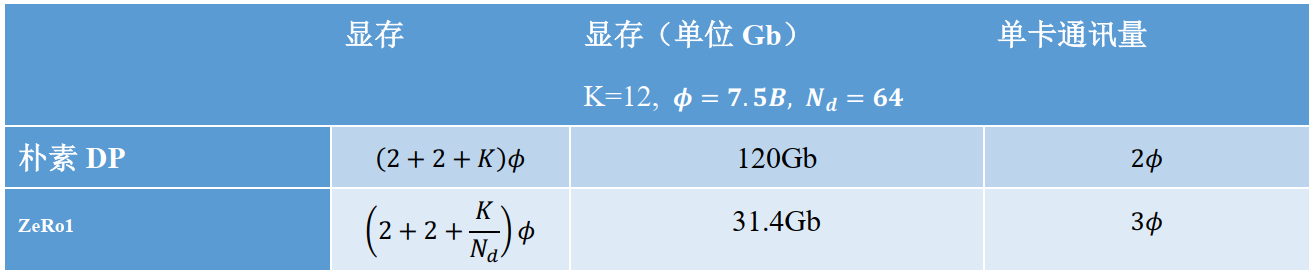
在增加1.5倍单卡通讯开销的基础上,将单卡存储降低了4倍。
优化器状态与梯度分割
我们把梯度也拆开,每个GPU格子维护一块梯度。

再次比对下显存和通讯量:

和朴素DP相比,存储降了8倍,单卡通讯量持平。
优化器状态、梯度、模型参数分割
我们把参数也切开。每块GPU置维持对应的optimizer states,gradients和parameters(即W)。
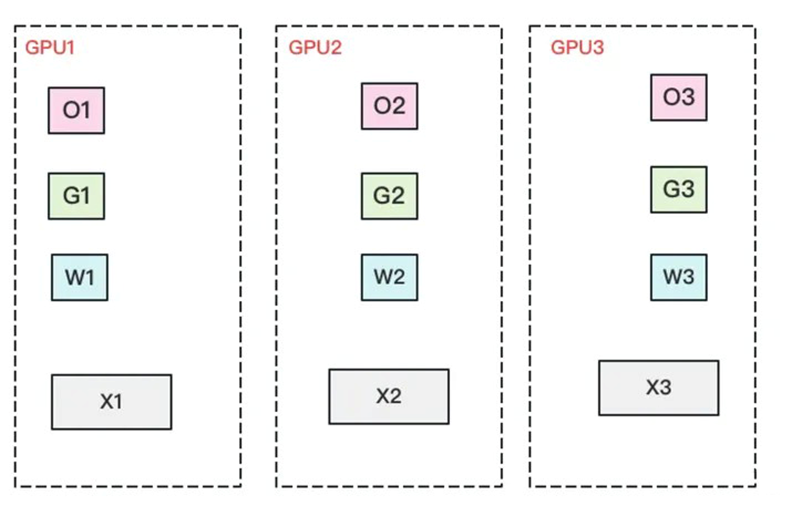
再次比对下显存和通讯量:
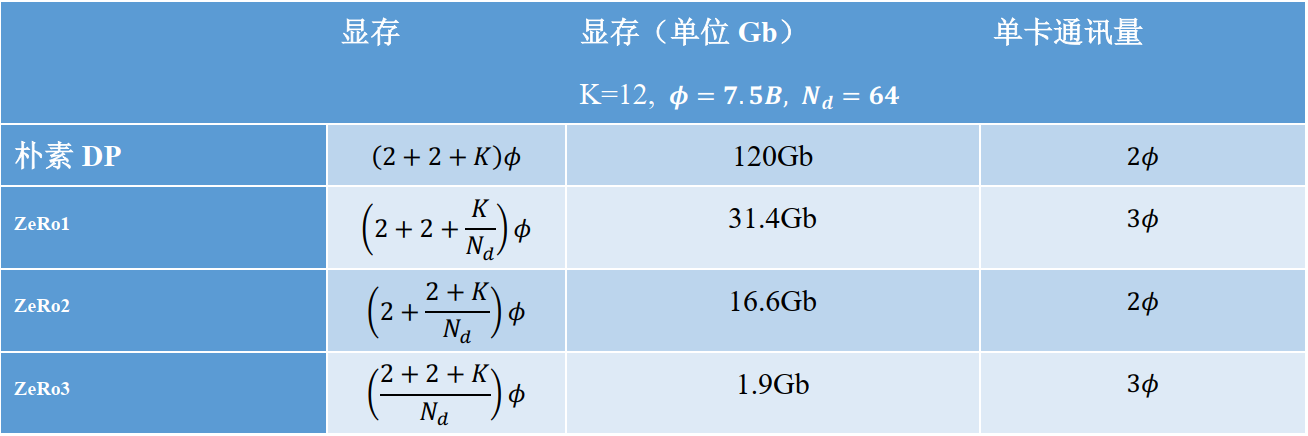
我们用1.5倍的通讯开销,换回近120倍的显存。只要梯度计算和异步更新做的好,通讯时间大部分可以被计算时间隐藏,因此这样的额外通讯开销,也是划算的。
