


相关介绍
大规模的视觉和语言表示学习在许多vision-language任务上取得了很大的进步。现有的方法大多采用基于Transformer的多模态编码器来联合建模视觉token和单词token。由于视觉token和单词token不对齐,因此多模态编码器学习图像-文本交互具有挑战性。
大多数现有的VLP( Vision Language Pretraining )方法(如LXMERT,UNITER,OSCAR)都依赖于预训练过的目标检测器来提取基于区域的图像特征,并使用多模态编码器将图像特征与单词token进行融合;广泛使用的图像-文本数据集是从web中收集而来的,具有固有的噪声 。
结构
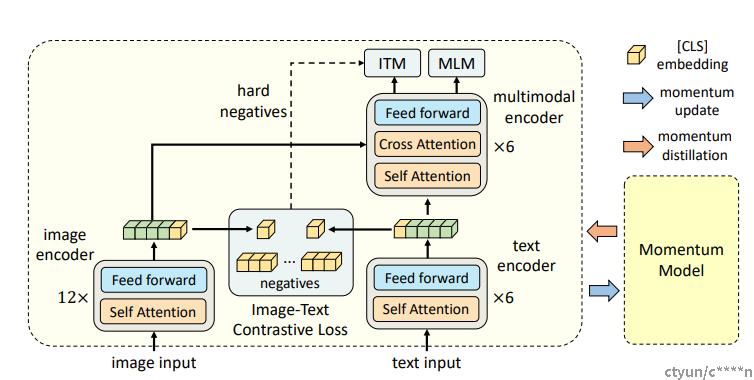
一个图像编码器、一个文本编码器和一个多模态编码器。使用一个12层的视觉TransformerViT-B/16作为图像编码器,并使用在ImageNet-1k上预训练的权重来初始化它。一个输入图像I被编码到特征tokens序列,使用[CLS] token的嵌入对齐。
对文本编码器和多模态编码器都使用了一个6层的Transformer。文本编码器使用BERTbase模型的前6层,多模态编码器使用BERTBase模型的最后6层。文本编码器将输入文本T转换为文本嵌入tokens,并输入多模态编码器。通过在多模态编码器的每一层进行交叉注意力,将图像特征与文本特征融合。
预训练任务
作者在三个目标任务上进行预训练,分别是:
- 图像文本对比学习(ITC)
- 图像文本匹配(ITM)
- 掩码语言建模(MLM)
作者在单模态编码器上进行ITC和MLM训练,在多模态编码器上进行ITM训练。
Loss
图像文本对比学习
学习了一个相似性函数,使匹配的图像-文本对具有更高的相似性得分,受MoCo的启发,作者维护了两个队列来存储动量单模态编码器的最新的M个图像-文本表示 。
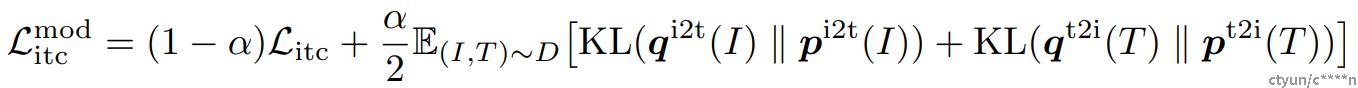
with torch.no_grad():
self._momentum_update() # EMA
image_embeds_m = self.visual_encoder_m(image) # (bs, 1+h/patch_size*(w/patch_size), vision_width)
image_feat_m = F.normalize(self.vision_proj_m(image_embeds_m[:, 0, :]), dim=-1) # (bs, embed_dim)
image_feat_all = torch.cat([image_feat_m.t(), self.image_queue.clone().detach()],
dim=1) # (embed_dim, bs+queue_size)
text_output_m = self.text_encoder_m.bert(text.input_ids, attention_mask=text.attention_mask,
return_dict=True, mode='text')
text_feat_m = F.normalize(self.text_proj_m(text_output_m.last_hidden_state[:, 0, :]),
dim=-1) # (bs, embed_dim)
text_feat_all = torch.cat([text_feat_m.t(), self.text_queue.clone().detach()],
dim=1) # (embed_dim, bs+queue_size)
sim_i2t_m = image_feat_m @ text_feat_all / self.temp # (bs, bs+queue_size)
sim_t2i_m = text_feat_m @ image_feat_all / self.temp # (bs, bs+queue_size)
sim_targets = torch.zeros(sim_i2t_m.size()).to(image.device)
sim_targets.fill_diagonal_(1) # row==col, value=1
sim_i2t_targets = alpha * F.softmax(sim_i2t_m, dim=1) + (1 - alpha) * sim_targets
sim_t2i_targets = alpha * F.softmax(sim_t2i_m, dim=1) + (1 - alpha) * sim_targets
sim_i2t = image_feat @ text_feat_all / self.temp # (bs, bs+queue_size)
sim_t2i = text_feat @ image_feat_all / self.temp # (bs, bs+queue_size)
# Image-Text Contrastive Learning loss
loss_i2t = -torch.sum(F.log_softmax(sim_i2t, dim=1) * sim_i2t_targets, dim=1).mean()
loss_t2i = -torch.sum(F.log_softmax(sim_t2i, dim=1) * sim_t2i_targets, dim=1).mean()
loss_ita = (loss_i2t + loss_t2i) / 2图像文本匹配
图像文本匹配预测了一对图像文本对是positive(匹配的)还是negative(不匹配的)。作者使用了[CLS] token在多模态编码器的输出嵌入作为图像文本对的联合表示,然后通过一个带有softmax的全连接层来预测一个二分类的概率。ITM的损失函数定义如下:
![]()
作者提出了一种对ITM任务进行hard negatives采样的策略。当负样本的图像文本对有相同的语义但在细粒度细节上不同,那么该样本是难样本。作者通过对比相似度寻找batch内的 hard negatives。对于一个batch中的每一幅图像,作者根据对比相似性分布从相同的batch中抽取一个负文本,其中与图像更相似的文本有更高的可能被采样。同样的,作者还为每个文本采样一个hard negative图像。
# forward the positve image-text pair
output_pos = self.text_encoder.bert(encoder_embeds=text_embeds,
attention_mask=text.attention_mask,
encoder_hidden_states=image_embeds,
encoder_attention_mask=image_atts,
return_dict=True,
mode='fusion',
)
with torch.no_grad():
bs = image.size(0)
weights_i2t = F.softmax(sim_i2t[:, :bs], dim=1) # (bs, bs)
weights_t2i = F.softmax(sim_t2i[:, :bs], dim=1) # (bs, bs)
weights_i2t.fill_diagonal_(0)
weights_t2i.fill_diagonal_(0)
# select a negative image for each text
image_embeds_neg = [] # List[torch.tensor], image_embeds_neg[0] shape is (1+h/patch_size ^2, vision_width)
for b in range(bs):
neg_idx = torch.multinomial(weights_t2i[b], 1).item()
image_embeds_neg.append(image_embeds[neg_idx])
image_embeds_neg = torch.stack(image_embeds_neg, dim=0) # (bs, 1+ (h/patch_size)^2, vision_width)
# select a negative text for each image
text_embeds_neg = []
text_atts_neg = []
for b in range(bs):
neg_idx = torch.multinomial(weights_i2t[b], 1).item()
text_embeds_neg.append(text_embeds[neg_idx])
text_atts_neg.append(text.attention_mask[neg_idx])
text_embeds_neg = torch.stack(text_embeds_neg, dim=0) # (bs, max_seq_length, hidden_size) hidden_size=vision_width
text_atts_neg = torch.stack(text_atts_neg, dim=0) # (bs, max_seq_length) mask
text_embeds_all = torch.cat([text_embeds, text_embeds_neg], dim=0) # (bs*2, max_length, hidden_size)
text_atts_all = torch.cat([text.attention_mask, text_atts_neg], dim=0) # (bs*2, max_length)
image_embeds_all = torch.cat([image_embeds_neg, image_embeds], dim=0) # (bs*2, 1+h/patch_size ^2, vision_width)
image_atts_all = torch.cat([image_atts, image_atts], dim=0) # (bs*2, 1+h/patch_size ^2)
output_neg = self.text_encoder.bert(encoder_embeds=text_embeds_all,
attention_mask=text_atts_all,
encoder_hidden_states=image_embeds_all,
encoder_attention_mask=image_atts_all,
return_dict=True,
mode='fusion',
)
vl_embeddings = torch.cat([output_pos.last_hidden_state[:, 0, :], output_neg.last_hidden_state[:, 0, :]],
dim=0) # (bs+2*bs, vision_width)
vl_output = self.itm_head(vl_embeddings) # (bs+2*bs, 2), 二分类
itm_labels = torch.cat([torch.ones(bs, dtype=torch.long), torch.zeros(2 * bs, dtype=torch.long)],
dim=0).to(image.device) # 正例的个数为bs, 负例的个数为2*bs
loss_itm = F.cross_entropy(vl_output, itm_labels) # 使用celoss掩码语言建模
掩码语言建模同时利用了图像和上下文文本来预测被掩盖的词。作者以15%的概率随机掩盖输入的token,并用特殊token[MASK]来替换它们。

input_ids = text.input_ids.clone() # (bs, seq_len)
labels = input_ids.clone() # (bs, seq_len)
probability_matrix = torch.full(labels.shape, self.mlm_probability)
input_ids, labels = self.mask(input_ids, self.text_encoder.config.vocab_size, image.device, targets=labels,
probability_matrix=probability_matrix) # (bs, seq_len)
with torch.no_grad():
# 输入是text的input以及图像的image_embeds_m
logits_m = self.text_encoder_m(input_ids,
attention_mask=text.attention_mask,
encoder_hidden_states=image_embeds_m,
encoder_attention_mask=image_atts,
return_dict=True,
return_logits=True,
) # 默认的mode, start_layer = 0, output_layer = self.config.num_hidden_layers
mlm_output = self.text_encoder(input_ids,
attention_mask=text.attention_mask,
encoder_hidden_states=image_embeds,
encoder_attention_mask=image_atts,
return_dict=True,
labels=labels,
soft_labels=F.softmax(logits_m, dim=-1),
alpha=alpha
)
loss_mlm = mlm_output.loss # 硬标签的损失和软标签的损失
loss_fct = CrossEntropyLoss() # -100 index = padding token
masked_lm_loss = loss_fct(prediction_scores.view(-1, self.config.vocab_size), labels.view(-1))
loss_distill = -torch.sum(F.log_softmax(prediction_scores, dim=-1) * soft_labels, dim=-1)
loss_distill = loss_distill[labels != -100].mean()
masked_lm_loss = (1 - alpha) * masked_lm_loss + alpha * loss_distill
动量蒸馏
用于预训练的图像文本对大多都收集自网络,往往都包含噪声。因此,正样本对经常是弱相关的,即文本包含和图像无关的文字或图像包含文本中没有描述的实体。对于ITC学习,图像的负样本文本可能也会匹配图像的内容。对于MLM,可能存在其他和标注不同的词能够更好地描述图像。但是ITC和MLM的one-hot标签会惩罚所有负标签预测,不考虑它们的正确性。
为了解决这一问题,作者提出从动量模型生成的伪目标中学习。动量模型是一个不断发展的教师模型,包含单模态和多模态编码器的指数移动平均版本。在训练过程中,作者训练基本模型使得它的预测值和动量模型的相匹配。对于ITC,作者首先使用来自动量单模态编码器的特征计算图像文本相似度,然后计算伪目标。
实验结果
作者在五个下游任务上测试了预训练模型,分别为:
- Image-Text Retrieval:包含两个子任务,即image-to-text检索和text-to-image检索。
- Visual Entailment:一个视觉推理任务,用于预测一张图片和一段文本之间的关系是蕴含的、中立的还是对立的。
- Visual Question Answering:给定一张图片和一个问题,预测答案。
- Natural Language for Visual Reasoning:预测一段文本是否描述了图片。
- Visual Grounding:定位对应于特定文本描述的图像中的区域
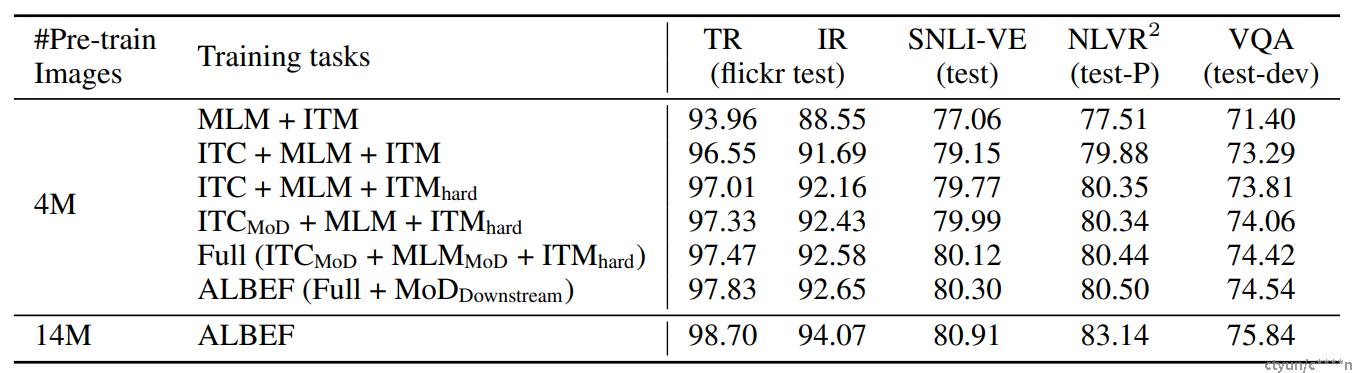
上表展示了本文方法的不同变体在下游任务上的性能。从表中可以看出,对比基础的预训练任务(MLM+ITM),增加ITC在所有任务上极大地提高了预训练模型的性能。前文所提到的hard negatives采样策略通过寻找更加具有信息的训练样本改进了ITM。此外,添加动量蒸馏改进了ITC、MLM和所有下游任务。表中最后一行表现了ALBEF可以有效地利用更多带有噪音的数据改进预训练的性能。
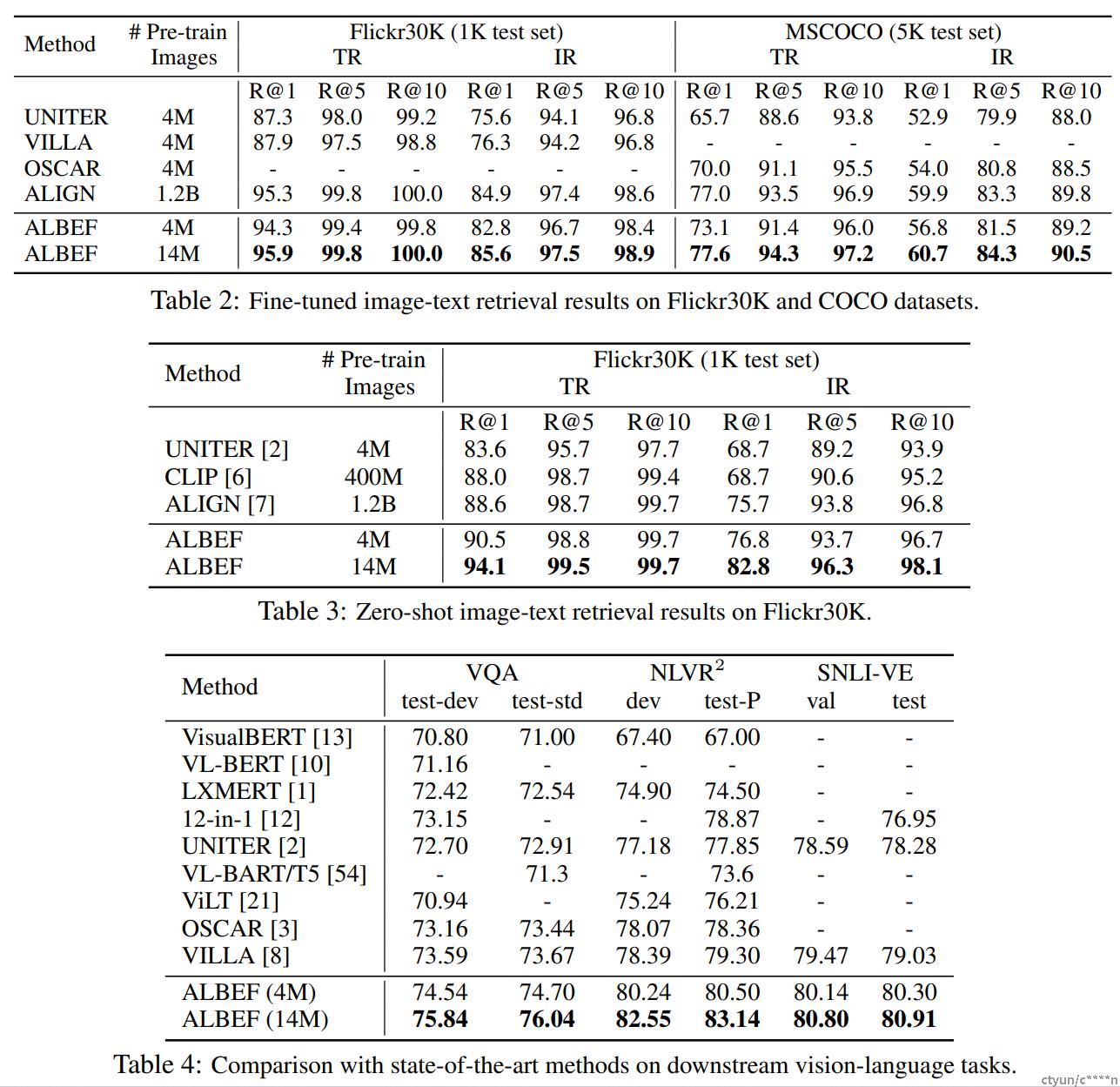
表4表现了本文方法和其他方法在其他理解类下游任务上的实验结果对比。在4M的预训练图片上,ALBEF已经取得了SOTA的性能。在14M的预训练图片上,ALBEF大大优于现有的方法,包括额外使用对象标签或对抗性数据增强的方法。和VILLA相对比,ALBEF在VQA test-std上取得了2.37%的改进,在NLVR^2 test-P上取得了3.84%的改进,在SNLI-VE test上取得了1.88%的改进。因为ALBEF是无检测器的,需要的图像分辨率更低,所以与大多数现有方法相比速度更快。

