


1、概述
Linux审计系统(Auditd)是一个深入集成至操作系统内核的高级安全框架,旨在全面记录系统行为,从文件访问、系统调用到用户活动、权限变更等,为系统安全策略执行、合规性检查、入侵检测和事件响应提供详实的数据支撑。
本文以5.10内核源码为例,结合应用层审计规则,阐述audit子系统是如何监控系统调用的以及审计日志的生成过程。
2、总体架构
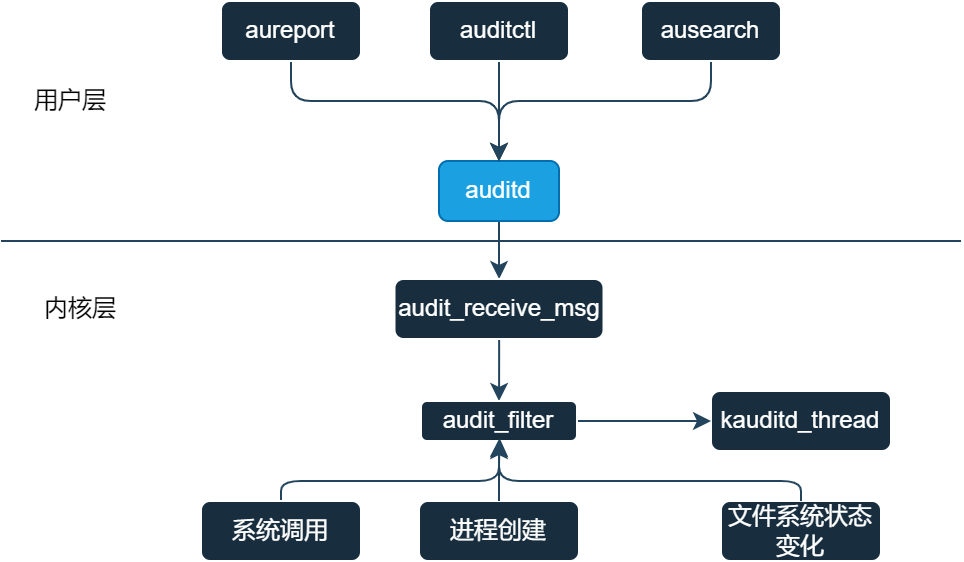
如上图所示,Linux audit审计系统分为用户层和内核层。用户层可以通过auditctl配置审计规则发给auditd守护进程,守护进程auditd通过netlink协议与内核进行通信交互。
内核层在启动阶段就会初始化audit子系统,创建一个netlink socket,启动audit_receive内核线程来处理用户层守护进程auditd发送的一些消息,例如审计规则解析,audit使能等。
内核维护一个日志队列,通过kaudit_thread内核线程来操作,当队列长度大于audit_backlog_limit(默认是60字节)时进行休眠(默认是60秒),否则从队列里取下一个节点进行日志格式化处理,然后写入到printk子系统里。
对于审计规则的触发,主要由以下三点:
-
- 系统调用
- 进程创建时
- 文件系统状态变化
这几个入口点都可以触发audit审计机制,后面我着重介绍一下audit审计系统时如何监控系统调用的。
3、audit子系统解读
本章结合源码解读audit子系统在内核启动时是如何初始化各个内核线程的和audit审计系统时如何监控系统调用。
3.1 audit内核启动初始化
Linux内核中审计子系统的初始化函数audit_init,它在系统启动的核心初始化阶段被调用。
kernel/audit.c

-
- 条件判断与早期返回:首先检查audit_initialized标志是否为AUDIT_DISABLED,如果是,则直接返回,表示审计功能被禁用;
- 内存管理:利用kmem_cache_create创建了一个名为audit_buffer的内核内存缓存区,用于高效管理审计缓冲区结构体的分配与释放;
- 队列与哈希表初始化:初始化了多个队列(audit_queue, audit_retry_queue, audit_hold_queue)来管理不同状态的审计消息,并通过循环初始化哈希表audit_inode_hash,用于快速检索涉及审计的文件inode信息;
- 并发控制:通过mutex_init初始化互斥锁audit_cmd_mutex.lock,确保对审计命令的并发访问得到同步控制;
- Netlink子系统集成:通过打印信息日志和注册audit_net_ops到netlink子系统,支持通过netlink接口进行审计消息的收发,同时根据audit_default变量的值输出审计子系统的启用状态;
- 系统状态标记与线程启动:将audit_initialized设置为AUDIT_INITIALIZED以表明审计系统已成功初始化,并启动kauditd_thread线程专门处理审计事件队列。如果线程启动失败,则触发系统panic;
- 审计日志记录:最后,通过audit_log函数记录一条审计日志,确认审计系统已经初始化完毕并处于启用状态。
Linux内核audit_init函数完成了审计子系统的全面初始化工作,包括资源分配、数据结构准备、并发控制机制设置、网络通信接口集成以及后台处理线程的部署,确保了审计功能在系统启动后即可正常运行。
3.1.1 audit_net_ops:netlink子系统注册
net_ops结构体定义如下:
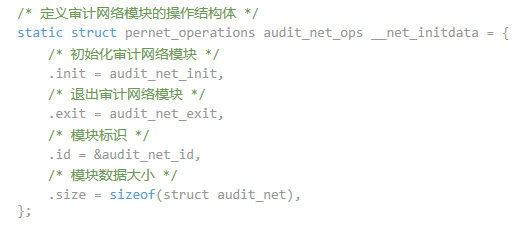
-
- .init:指向audit_net_init函数,此函数在网络子系统初始化时被调用,负责设置或配置审计模块的初始状态;
- .exit:指向audit_net_exit函数,此函数在网络子系统关闭或退出时被调用,用于清理或释放审计模块占用的资源;
- .id:指向audit_net_id,用作审计网络模块的唯一标识符;
- .size:指定结构体struct audit_net的大小,这在内存管理中用于分配或复制结构体时计算所需空间
下面看下audit_net_init的具体实现:

audit_net_init 函数目的是初始化给定网络命名空间net中的审计(Audit)子系统相关的netlink套接字,大致可以分为以下四个步骤:
配置netlink套接字: 定义了一个netlink_kernel_cfg结构体cfg,用于配置Netlink套接字。
-
-
- 指定输入处理函数audit_receive(处理接收到的审计消息);
- 绑定操作audit_multicast_bind;
- 解绑操作audit_multicast_unbind,设置了非根用户接收标志(NL_CFG_F_NONROOT_RECV),并指定了支持的组数(AUDIT_NLGRP_MAX,审计相关的Netlink多播组的最大数量)。
-
创建netlink套接字: 调用netlink_kernel_create在指定的网络命名空间中创建一个netlink套接字,类型为NETLINK_AUDIT,并应用上述配置。这个套接字用于审计消息的发送和接收。
设置发送超时: 如果套接字创建成功,为了防止审计消息发送时长时间阻塞,设置了发送超时时间sk_sndtimeo为系统时钟频率(HZ)的十分之一秒。
错误处理: 如果创建Netlink套接字失败,则通过audit_panic函数报告错误并返回ENOMEM(表示内存不足)。
上面这段代码定义了网络命名空间(netns)相关的初始化和清理函数,以及一个pernet_operations结构体,用于注册这些操作到内核的网络命名空间子系统中。
接下来,我们分析以下audit_receive函数,理解以下内核中,audit子系统是如何处理来自netlink sockt的消息。

上面这段代码定义了一个名为audit_receive的静态函数,其主要功能是从Netlink控制套接字接收并处理审计相关的消息。
函数接收一个类型为struct sk_buff的指针参数skb,表示从网络接口接收到的数据包或待发送的数据包。函数内部首先通过nlmsg_hdr(skb)获取Netlink消息头,并初始化消息处理的长度变量len。之后,通过加锁(audit_ctl_lock())保护共享资源,遍历消息缓冲区中的所有Netlink消息。
对于每个消息,调用audit_receive_msg()进行具体处理,并根据处理结果或消息标志决定是否发送Netlink确认(netlink_ack()调用)。处理完一条消息后,通过nlmsg_next()移动到下一条消息,直至所有消息都被处理。
在消息处理循环结束后,解锁(audit_ctl_unlock())。如果审计消息队列长度超过了预设的后台限制(audit_backlog_limit),函数会采取措施惩罚发送者:唤醒kauditd(一个负责处理审计日志的守护进程),并将当前进程置于不可中断的等待状态一段时间(schedule_timeout()调用),以此来减缓审计消息的接收速度,避免队列过载。
audit_receive函数是审计子系统中处理实时审计消息的关键组件,它确保了消息的正确解析与处理,并在系统负载较高时能适当调节消息接收速率,以维护系统的稳定运行。
下面我们再分析一下audit_receive_msg的具体实现细节,理解一下audit子系统内部是是如何处理单个netlink 消息的,详细代码分析如下:

此函数audit_receive_msg是audit子系统的核心处理逻辑之一,负责接收并解析来自auditd守护进程通过netlink socket发送的各种审计控制和配置消息。函数的主要职责是根据接收到的消息类型执行不同的操作,包括但不限于获取审计状态、设置审计参数、管理审计规则、处理审计信号信息以及调整TTY审计设置等。
函数参数说明
-
- struct sk_buff *skb: 指向网络数据包的指针,包含了整个接收的数据包。
- struct nlmsghdr *nlh: 指向netlink消息头的指针,提供了关于消息类型、长度等元数据。
函数核心逻辑
-
- 消息验证与预处理:首先通过audit_netlink_ok函数验证消息的合法性,确保来源可靠且类型有效。
- 消息类型分发:使用switch-case结构,依据nlh->nlmsg_type(即msg_type)的不同值,执行相应的处理逻辑。主要处理的审计消息类型包括:
- AUDIT_GET: 回复当前审计系统的状态信息,这里可以使用auditctl -s进行获取
- AUDIT_SET: 根据请求更新审计系统的配置,如启用状态、失败策略、PID、速率限制等。
- AUDIT_GET_FEATURE/AUDIT_SET_FEATURE: 获取或设置审计特性。
- AUDIT_USER系列: 处理用户空间触发的审计事件记录。
- AUDIT_ADD_RULE/AUDIT_DEL_RULE: 添加或删除审计规则。
- AUDIT_LIST_RULES: 列出当前的审计规则。
- AUDIT_TRIM: 调整审计日志存储以节省空间。
- AUDIT_MAKE_EQUIV: 在审计标签树中创建等价关系。
- AUDIT_SIGNAL_INFO: 发送审计信号信息。
- AUDIT_TTY_GET/AUDIT_TTY_SET: 获取或设置TTY审计状态。
- 安全上下文处理与资源管理:在处理特定消息(如AUDIT_SIGNAL_INFO)时,涉及安全上下文的获取和释放,以及动态内存的分配与释放,体现了对系统资源的细致管理。
- 错误处理:函数内广泛使用错误码(err)来跟踪操作结果,确保在遇到问题时能够及时反馈错误信息。
总的来说,audit_receive_msg函数是审计框架中处理审计控制指令的关键组件,通过精细地解析和响应多种审计相关消息,实现了审计系统配置的动态调整和事件处理。其设计体现了高度模块化和错误容错性,对于维护系统安全审计功能的灵活性和可靠性至关重要。
audit_receive_msg每个case可能会调用如下函数:audit_log_user_recv_msg--->audit_log_common_recv_msg,具体代码分析如下:

-
- 关键操作:
- 检查审计功能是否启用以及消息类型,以决定是否跳过日志记录。
- 从当前进程获取有效用户ID和线程组ID,准备审计日志的基本信息。
- 调用audit_log_start初始化审计缓冲区,为记录日志做准备。
- 向缓冲区写入标准日志前缀,包括进程ID和用户ID,以及会话和任务上下文信息。
- 条件处理:
- 在审计未启用或特定消息类型下,通过将*ab设为NULL避免日志记录,体现了资源节约逻辑。
- 关键操作:
audit_log_common_recv_msg负责处理核心审计日志的接收与记录工作。它根据传入的审计上下文(struct audit_context *context)、审计缓冲区指针(struct audit_buffer **ab)以及消息类型(u16 msg_type)来决定是否记录日志及记录哪些内容。
通过以上分析,我们终于看到了audit_log_start 函数了,其核心目的是在Linux审计系统中初始化一个新的审计日志缓冲区,以便记录特定类型的审计事件,下面是代码详细分析:

该函数用于开始一个审计记录,它会根据当前的系统状态决定是否创建一个审计缓冲区。 如果审计系统未初始化、审计过滤条件不满足、审计队列过满或者内存分配失败,函数将返回NULL。 否则,它将返回一个指向审计缓冲区的指针,这个缓冲区可以被后续的审计记录函数使用。
set_current_state(TASK_UNINTERRUPTIBLE);
stime = schedule_timeout(rtime);
怎么理解这两句代码呢?这里为什么要这么设置?rtime的默认值是60秒
这两行代码是Linux内核中用于线程调度和睡眠的经典操作,它们与进程的等待和超时处理紧密相关。下面是对这两行代码的详细解释:
-
-
set_current_state(TASK_UNINTERRUPTIBLE);这行代码将当前进程(
current)的状态设置为不可中断的睡眠状态(TASK_UNINTERRUPTIBLE)。这意味着进程会放弃CPU使用权并进入睡眠,直到某个特定条件满足后被唤醒。在此期间,进程不会响应信号,即使接收到信号也不会被唤醒或终止,因此是“不可中断”的。这种状态常用于需要确保操作原子性或资源一致性的场景。 -
stime = schedule_timeout(rtime);接下来的这行代码用来实现进程的限时等待。
schedule_timeout()函数会使调用它的进程睡眠指定的时间(由rtime参数给出),然后返回剩余的睡眠时间(以jiffies为单位,如果超时则返回0)。在这个过程中,进程放弃了CPU控制权,允许其他进程运行。当等待时间结束或被提前唤醒时,函数返回,并且stime变量会被更新为实际剩余但未使用的睡眠时间。
-
结合这两行代码,其作用是让当前进程在不可中断状态下等待最多rtime时间段。在这个例子中,rtime默认值为60秒,意味着进程会尝试等待60秒,或者直到某些条件触发它被唤醒(比如通过其他代码路径中的wake_up系列函数)。这样的设计可能是为了在等待审计队列空间释放时避免无限期阻塞,同时确保在等待期间不会因外部信号中断而导致不一致状态。如果等待超时(即队列仍然满且无法继续写入审计信息),则通过计算返回的stime来更新已消耗的等待时间,并可能据此做出进一步的处理决策,如记录错误信息并返回。
3.1.2 kauditd_thread:启动内核线程kauditd
audit_init函数中,网络中子系统注册完成后,紧接着就是启动内核线程 kauditd,该线程负责将审计记录发送到用户空间。它管理多个队列,包括主队列、重试队列和保持队列, 并尝试将审计记录通过网络发送出去。如果发送失败,记录会被移动到重试队列或保持队列, 以便以后再次尝试发送。详细代码如下:

代码定义了一个名为kauditd_thread的静态函数,它代表一个工作者线程,主要职责是将内核中的审计记录发送到用户空间。该函数通过一系列复杂的逻辑来管理不同类型的审计消息队列(主队列、重试队列、保持队列),并利用网络套接字(struct sock *sk)进行数据传输。关键操作包括:
-
- 初始化与循环控制:线程首先设置自己为可冻结状态,然后进入一个循环,该循环会在特定条件(由kthread_should_stop()判断)下终止。
- 审计连接处理:通过读取拷贝更新(RCU)锁访问全局审计连接auditd_conn,获取网络命名空间和端口ID,为后续的网络通信做准备。
- 队列处理逻辑:
- 保持队列与重试队列的清空尝试:使用kauditd_send_queue函数尝试发送保持队列和重试队列中的审计记录,设定最大重试次数为UNICAST_RETRIES。
- 主队列处理:处理主队列时,先执行组播发送,再根据网络套接字是否有效选择单播重发或记录保留策略。
- 资源管理和线程同步:
- 成功发送或遇到错误后,会适时释放网络命名空间引用,并重置审计连接状态。
- 使用wake_up唤醒可能因审计队列积压而等待的其他进程。
- 通过wait_event_freezable等待新的审计记录到来或线程被冻结,实现了高效的事件驱动和资源管理。
- 退出处理:当收到停止信号 kthread_should_stop 时,线程将正常返回0,结束执行。
整体而言,kauditd_thread是一个核心的后台线程实现,对于系统的安全审计功能至关重要,它确保了审计事件能够跨用户空间与内核空间可靠地传递,同时优化了网络通信效率和系统资源的使用。
3.2 audit审计监控内核系统调用
这里以 x86-64架构为例,结合内核5.10源码,分析一下audit子系统是如何监控系统调用的。
整体调用关系如下图所示:
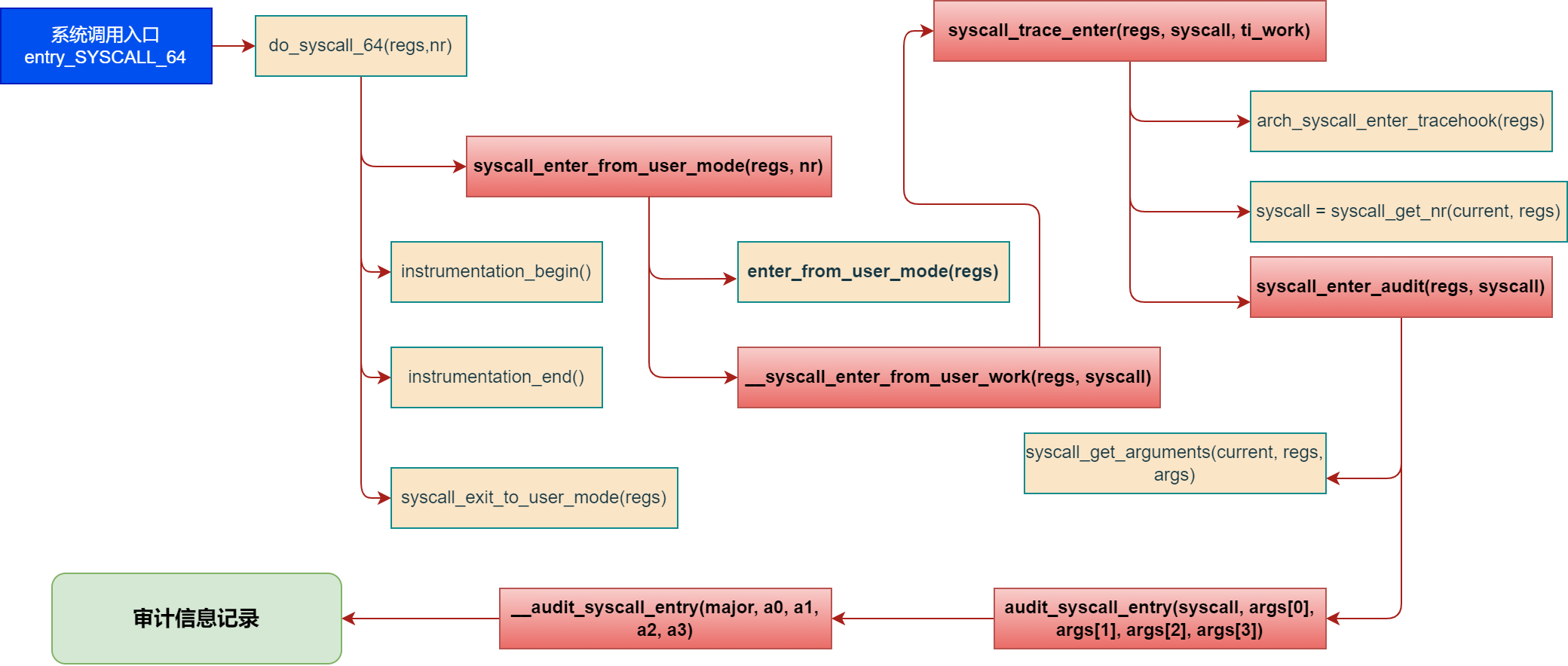
3.2.1 系统调用入口处理函数:do_syscall_64
arch\x86\entry\common.c

该函数负责根据系统调用号(nr)调用相应的系统调用处理函数,并处理一些特殊情况。这里我们主要关心的是 syscall_enter_from_user_mode(regs, nr) 函数,该函数用于做一些系统调用进入内核前的准备工作,比如安全检查、权限验证等,并可能返回修改后的系统调用号。audit审计记录系统调用就是在该函数内核调用记录的。
这里我们可以看一下 struct pt_regs的详细实现:
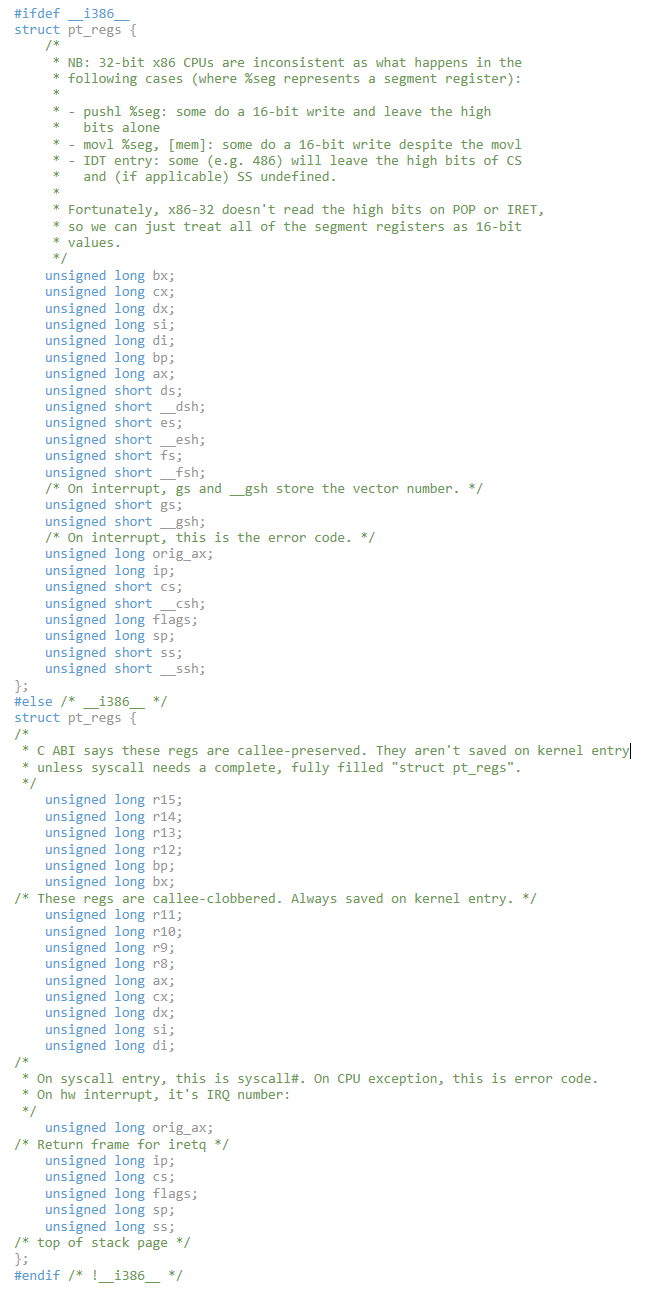
根据不同的体系结构(这里是针对i386和非i386,主要是x86_64)提供了不同的寄存器保存结构。struct pt_regs用于保存用户空间进程在进行系统调用、中断或异常处理时的寄存器状态,以便在处理完成后恢复到原来的状态。下面分别对两种架构下的struct pt_regs进行分析:
i386架构下的struct pt_regs
对于32位x86(i386)架构,struct pt_regs定义了如下字段:
-
- 通用寄存器:包括bx, cx, dx, si, di, bp, ax,它们分别对应于用户空间程序调用时的寄存器状态 <-----------------这里便是audit审计子系统记录的信息(bx、cx、dx、si)---- 这里为何只记录系统调用的前四个参数?
- 段寄存器:ds, es, fs, gs, ss,每个段寄存器后面跟着一个未使用的占位符(如__dsh),这是因为x86-32架构实际上只使用段寄存器的低16位,但为了对齐和兼容性保留了完整的32位宽度。
- 中断或系统调用相关:orig_ax 存储原始的系统调用号或中断错误码;ip(指令指针)、cs(代码段寄存器)、flags(标志寄存器)、sp(堆栈指针)和ss(堆栈段寄存器)用于保存中断或系统调用时的上下文,以便执行完内核操作后通过iret指令恢复。
非i386架构(主要指x86_64)下的struct pt_regs
对于64位x86架构(非i386,主要是x86_64),struct pt_regs的定义有所不同,以适应更宽的寄存器和不同的调用约定:
-
- 扩展的通用寄存器:除了基本的32位寄存器外,还包含了r8至r15这些新增的64位寄存器,这些寄存器在64位模式下是作为函数调用的额外参数传递或局部变量使用 <-----------------这里便是audit审计子系统记录的信息(di、si、dx、r10)---- 这里为何只记录系统调用的前四个参数?
- callee-preserved registers:r15至r12和bp(基指针)是callee-preserved,意味着在函数调用中由调用者保存,但在系统调用或异常处理时,内核会保存它们。
- callee-clobbered registers:r11至r8在函数调用中可以被调用者自由使用(无需保存),但在系统调用时仍然需要保存。
- 系统调用和异常处理相关:orig_ax用于存储系统调用号或错误码;ip, cs, flags, sp, ss与i386类似,用于上下文保存和恢复。
struct pt_regs的设计反映了不同处理器架构下用户空间程序状态保存的需求。对于i386,它侧重于传统的32位寄存器集,而x86_64则扩展了寄存器集合以支持更高效的64位运算和函数调用。无论哪种架构,struct pt_regs都是确保系统调用、中断或异常处理后能精确恢复用户空间执行状态的关键数据结构。
3.2.1 系统调用入口审计函数:syscall_enter_audit
syscall_enter_audit函数是系统调用审计机制的实现细节之一,强化了系统调用层面的安全监控能力,具体代码如下:
kernel\entry\common.c
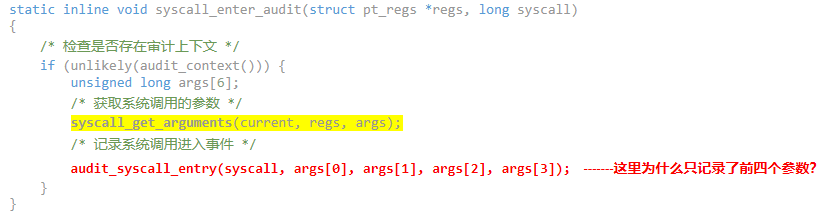
此负责在系统调用真正执行前记录审计信息,是系统安全监控和合规性验证的关键一环。它仅在审计上下文可用(通过audit_context()判断)时执行。
核心流程:
-
- 审计上下文检查:利用unlikely(audit_context()) macro高效地检查当前是否有有效的审计上下文。unlikely宏提示编译器该条件很少为真,可能优化生成的代码。
- 获取系统调用参数:如果审计被激活,通过syscall_get_arguments从当前进程的上下文中提取系统调用的参数到一个局部数组args中。上面提到的一些寄存器的值。
- 记录审计日志:调用audit_syscall_entry来记录系统调用的入口信息。包括系统调用号(syscall)和前四个参数(args[0]至args[3]),这一步骤对于追踪系统活动、检测潜在恶意行为至关重要。
我们先分析一下syscall_get_arguments的实现细节,再来看audit_syscall_entry函数的实现。

根据前面介绍的struct pt_regs的结构定义,对于32位x86(i386)架构,这里存储了bx、cx、dx、si、di、bp共刘六个通用寄存器的值;对于64位x86架构(非i386,主要是x86_64),这里存储了di、si、dx、r10、r8、r9六个通用寄存器的值。
这里的六个寄存器的值可以理解为系统函数调用的前六个参数。
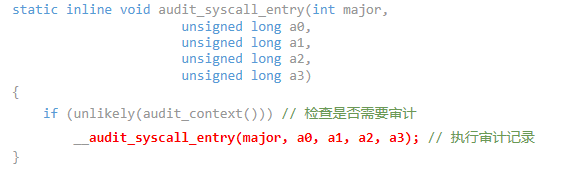
这里封装了一层,再记录之前先检查是否需要审计。

函数接收五个参数:
-
- major: 指定系统调用的主要类型或功能。
- a1至a4: 分别代表系统调用所使用的四个附加寄存器的值,这些通常用于传递系统调用的具体参数。
函数执行流程概述如下:
-
- 检查审计环境:首先确认审计功能是否已启用以及当前是否存在有效的审计上下文。若审计未启用或上下文缺失,则直接返回,不进行后续操作。
- 状态验证与错误检查:通过一系列的状态检查确保审计上下文的正确性和一致性。例如,如果审计上下文已被标记为正在使用中或存在名称计数异常,则会触发错误检查(BUG_ON宏)。
- 状态依赖处理:根据当前审计状态决定是否需要进一步处理。如果是构建审计上下文的状态(AUDIT_BUILD_CONTEXT),则初始化一些审计记录的字段,并检查当前任务是否受审计守护进程监控。
- 填充审计信息:最后,函数会填充审计上下文的多个字段,包括架构类型、系统调用编号、参数、时间戳等,为后续可能的审计记录输出做准备。
分析了syscall_get_arguments和audit_syscall_entry函数的实现细节,我们再回到之前的一个问题,下图标红的一行:
PS:这里比较令人费解,为什么只记录前四个参数呢?按照当前的源码的调用分析,audit context结构是在进程fork时创建的无论前六个参数是否都存在,都已经保存再内核栈里面了,如果是指针也可以保存下来,并且前四个参数也可能是存在指针的情况,这里也是留下了一个疑问,待深入研究理解之后,再尝试进行解读。
4、个人的一些思考
经过对Linux audit子系统的部分解读,这里也提出一些问题(或者说笔者认为当前audit子系统存在的一些缺陷):
- audit_log_start 函数中设计为直接切换为不可中断模式后,直接进入睡眠模式
set_current_state(TASK_UNINTERRUPTIBLE);
stime = schedule_timeout(rtime);
这里当审计日志超过配置的队列长度60字节后,非常容易触发,CPU中频繁进行上下文切换,非常容易造成操作系统性能下降,典型的案例就是ssh登录卡顿,正常我们仅需要2~3秒即可登录系统,如果审计日志队列超过了默认长度,对于多核CPU也会造成一定影响,实测4核的情况下,需要约10秒;单核或双核的情况下影响较大,需要60秒作用。
如果把队列长度配置为8192(支持的最大值),同样避免不了该问题,如下图所示
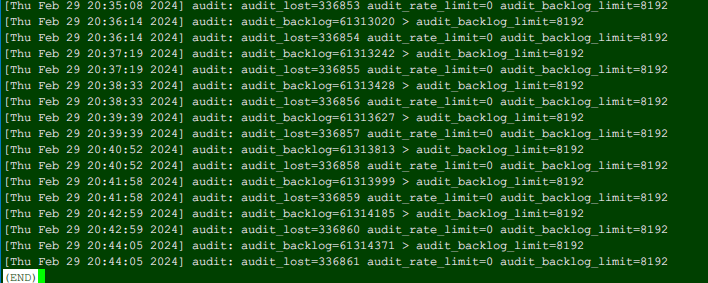
- 这种情况下,ssh已经无法登录设备。
- 审计日志丢失,超过日志队列长度后,达到睡眠直接后,清空队列
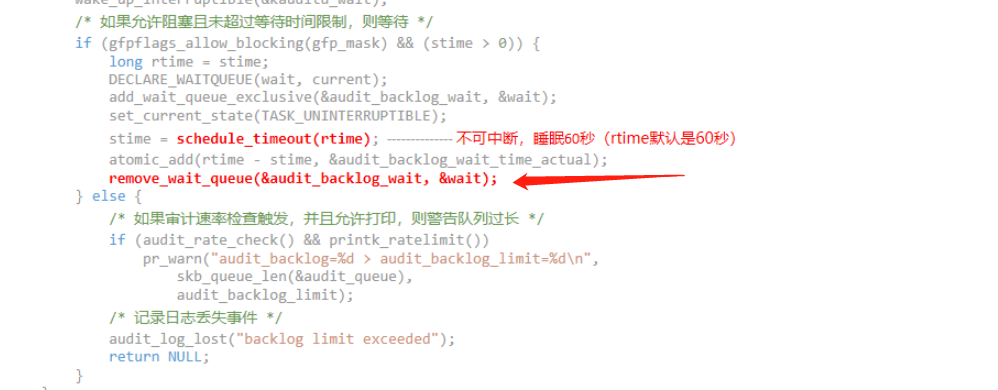
- 这里会导致审计日志丢失,可能会影响一些关键问题的排查。
- 系统调用参数审计不完整:仅只记录前四个参数
- 与用户层的auditd服务强关联
通过netlink与用户层的auditd进行通信交互,内核层日志队列的清空依赖于用户层的auditd服务,如果用户层的auditd服务没有开启,则内核层的审计日志队列就会堆积,日志队列超过audit_backlog_limit,便会触发当前线程睡眠rtime,这里暂停后又会影响整个audit审计子系统的运行。
5、总结
关于Linux audit子系统,这里仅仅是解读了audit子系统内核启动初始化过程以及audit是如何审计记录系统调用的。对于Linux audit子系统,除了监控系统调用,还能监控进程创建、文件系统状态变化等,这些我会在后续的文章中来分析解读。
