


对系统编程人员来说,深入理解cache至关重要,功能开发已不是难点,稍微懂点编程的都能够完成一些软件的功能开发,但是如何写出高效能的代码,以及优化Linux系统的性能却是非一日之功可以达成的,需要不断地学习、积累、实践、验证,如此反反复复,理论结合实践,才是真正地学习进步。
本章节旨在理解cache基本原理,针对cache基本概念、cache内部架构、TLB、虚拟cache和物理cache做一些介绍。
Cache基础
cache一般是集成在CPU内部的RAM,相对于外部的内存颗粒来说造价昂贵,因此一般cache是很小的RAM,但是访问速度和CPU是匹配的。还有一点,如果访问数据在cache命中的话,不仅仅能提速,提高程序的性能,还能减低功耗。典型的CPU中,Cache的排布大概如下图所示:
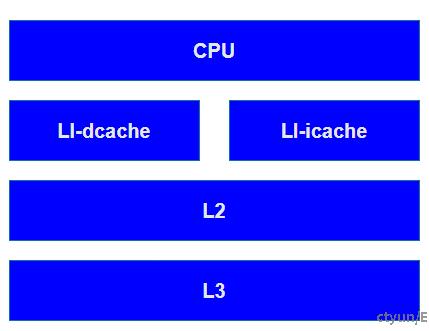
数据访问时先找寄存器,寄存器里没有找L1 Cache, L1 Cache里没有找L2 Cache依次类推,最后找到硬盘中
同时,我们可以看到,速度与存储容量的折衷关系。容量越小,访问速度越快,总结如下:
L1速度> L2速度> L3速度> RAM
L1容量< L2容量< L3容量< RAM
经典的架构设计,如下图所示:
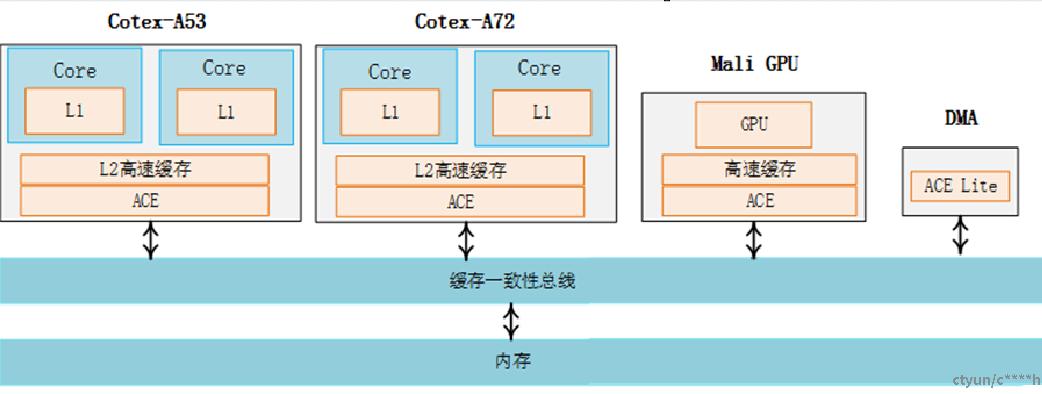
ARM64系统的架构由Corte-A72和Cortex-53组成了大小核架构,每个CPU核心都有L1 cache,每个cluster(可以理解为核的集群)里共享一个L2 cache,另外还有Mali GPU和DMA外设。
Cache工作模式(经典模式)
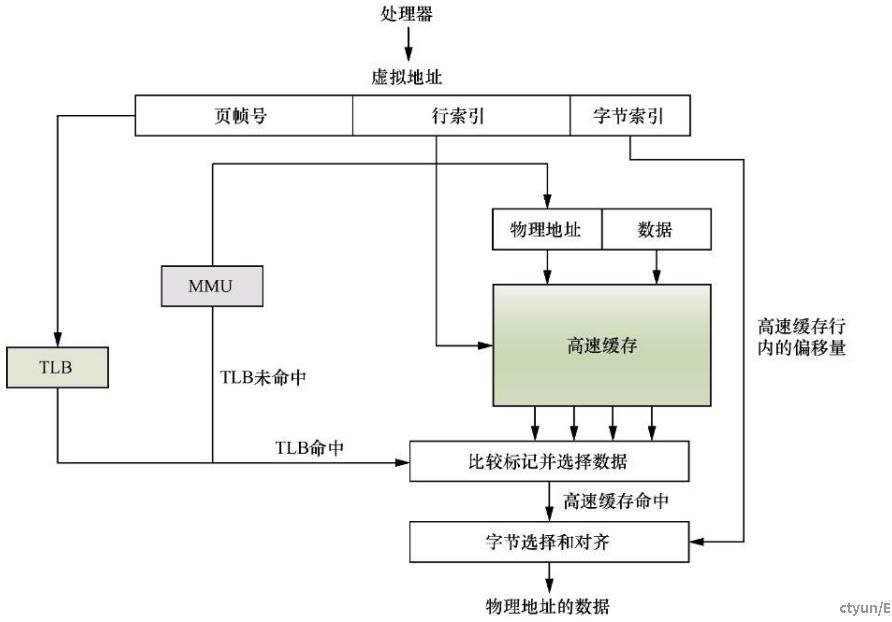
CPU在访问内存的时候,会同时把所需要访问的虚拟地址同时发给TLB和cache。TLB(Translation Lookaside Buffer)是一个用于存储虚拟地址到物理地址转换的小缓存,可以理解为页表缓存。处理器先使用EPN(effective page number,有效页帧号)在TLB中进行查找最终的RPN(Real Page Number,实际页帧号)。如果这期间发生TLB未命中(TLB Miss),将会带来一系列严重的系统惩罚,处理器需要访问MMU并且查询页表。假设这里TLB 命中(TLB Hit),此时很快获得合适的RPN,并得到相应的物理地址(Physical Address,PA)
Cache内部结构
冯-诺依曼架构中,指令cache和数据cache是同一个,在优化后的哈弗架构中使用独立的指令cache(I-cache)和数据cache(D-cache),即可以同时访问指令和数据。
在ARMv8处理器中,L1 cache区分指令cache和数据cache,但是L2 cache还是统一的,即折中冯诺依曼架构和哈弗架构。
cache需要保存地址、数据和一些状态信息,所以需要一些术语来统一对cache进行描述。现代Cache组织模式为“4路(way)组(set)相连模式”。所谓的“4路(way)组(set)相连模式”,如下图所示:
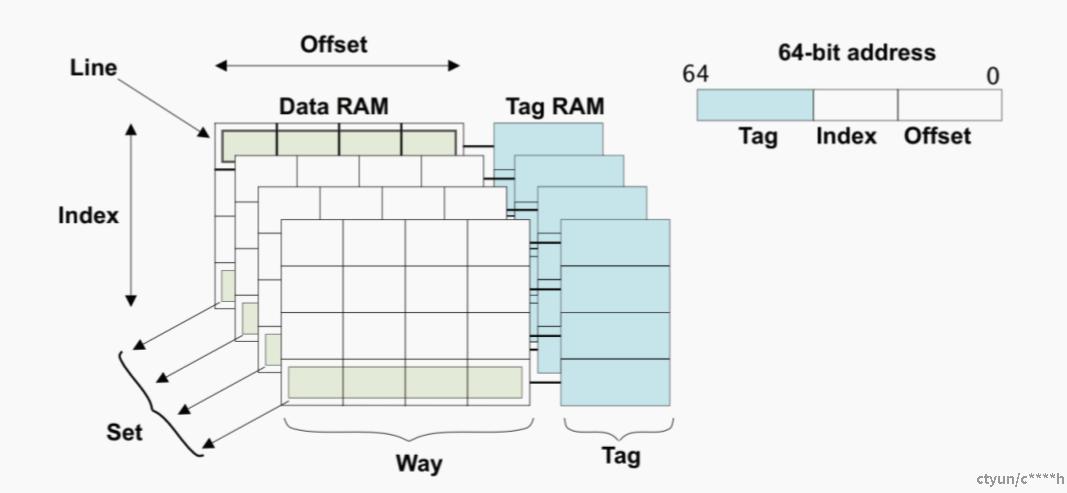
理解cache,SET、WAY、TAG、INDEX,这几个概念是关键。
-
tag是内存地址的高位部分,存储在cache中用于标识相应的数据。一般来说cache的大小指的是所保存的数据规模,并不包括其中需要储存tag的物理空间。很多时候并不是一个tag对应一个数据,而是对应一组数据,这一组数据块称为cache line,即cache读写的最小的粒度。
cacheline是主存的连续空间数据。
-
当某个cacheline包含有效的数据时,称为valid状态位,否则称为invalid状态。每一个cacheline都会有多个状态位。除了前面提到的valid/invalid,还有dirty状态位,表明cache中的数据是否与主存中的数据相同,以决定是否更新主存(多个dirty位可以更细粒度地表示cacheline中每个数据的状态)。
-
index是内存地址的一部分,以决定在哪些cacheline中搜索tag。
-
way是将cache进行划分成几个相同大小的部分,每几个way对应一个相同的index(set),个人认为这里的“way”理解为块更合适。
-
set就是由一组相同index的cacheline组成。
set、way涉及cache的映射方式,直接相连、组相连和全相连,后面会详细介绍。
-
offset,前面我们提到过,一个cache line由多个数据组成,有时候你不需要整个cacheline数据,这个时候可以根据其中的地址低位作为offset进行索引cacheline中各个数据。
Cache映射方式 – 直接映射:每组只有一个高速缓存行
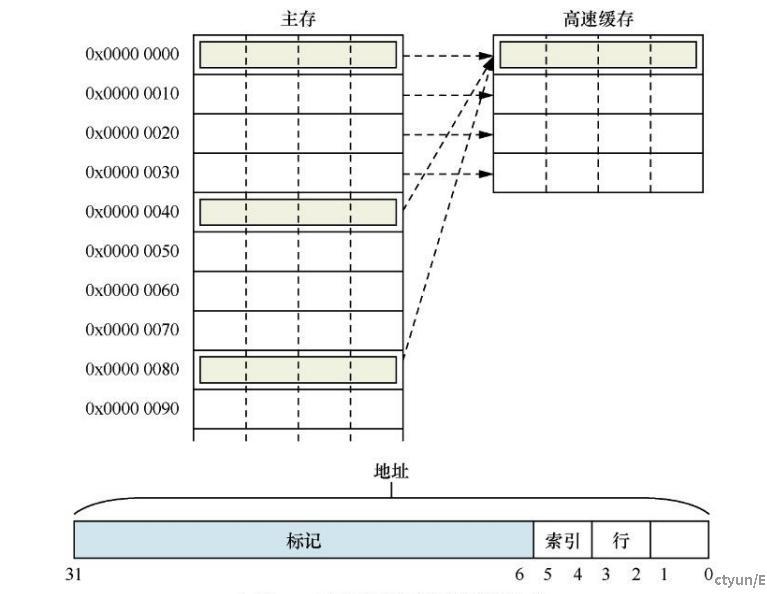
如上图所示,
假设cache只有4个cache line,那么直接映射的结果就是0x0地址到0x30,这段内存地址直接映射到cache里。
如果cpu要访问0x40到0x70,这段内存,那么又把数据会直接映射到cache里,这时候的映射,之前在0x0~0x30这段内存地址的数据在cache里必须被清理,否则后面的没办法映射。这里就产生了cache line的替换操作,某些场景中会造成的严重的性能问题。
Cache映射方式 –组相联:解决直接映射高速缓存中的高速缓存颠簸问题,提高性能
2路组相联的结构入下图所示:
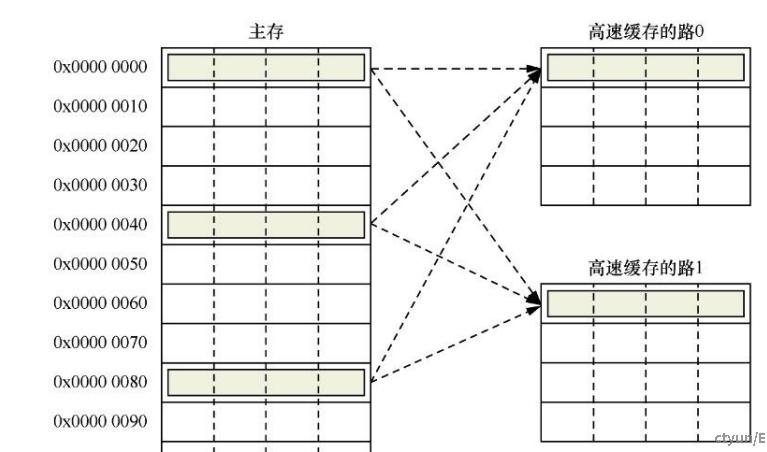
每一路包括4个高速缓存行,因此每个组有两个高速缓存行,可以提供高速缓存行替换。
地址0x00、0x40或者0x80的数据可以映射到同一个组中任意一个高速缓存行。
当高速缓存行要发生替换操作时,就有50%的概率可以不被替换,从而减小了高速缓存颠簸。
组相联的高速缓存:
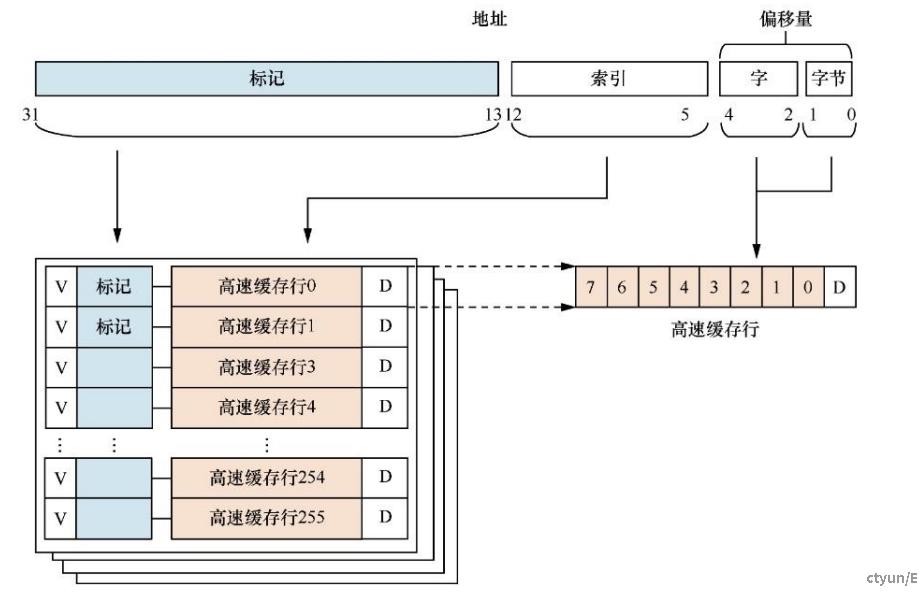
如上图所示,32KB大小的4路组相联的cache,其中cache line为32字节,
高速缓存的总大小为32KB,并且是4路(way),所以每一路的大小为8KB:
way_size = 32 / 4 = 8(KB)
高速缓存行的大小为32字节,所以每一路包含的高速缓存行数量为:
num_cache_line = 8KB/32B = 256
所以在高速缓存编码地址Address中,Bit[4:0]用于选择高速缓存行中的数据,其中Bit [4:2]可以用于寻址8个字,Bit [1:0]可以用于寻址每个字中的字节。Bit [12:5]用于索引域(Index)选择每一路上高速缓存行,其余的Bit [31:13]用作标记域(Tag)。
TLB(Translation Lookaside Buffer)
TLB(一块很小的高速缓存)用于缓存已经翻译好的页表项,一般在MMU内部。TBL表现包含一个页面的基本信息,如有效标记位、VPN、PFN、修改位等。
当CPU需要访问一个虚拟地址时,首先会在TLB中查询,如果TLB中没有相应的表现(TLB mis),则需要访问页表来计算出对应的为u里地址;如果TLB中有相应的表项(TLB hit),则直接从TLB表项中获取物理地址,如下图所示,
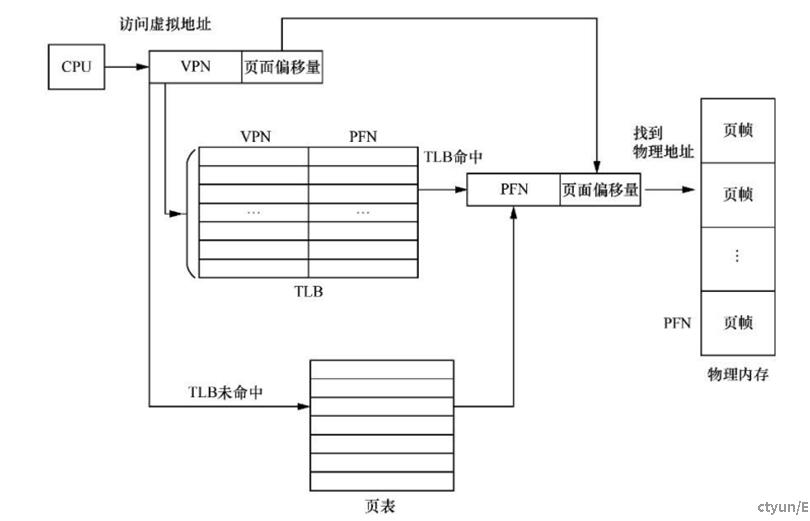
TLB 内部存放的基本单位是 TLB 表项,TLB 容量越大,所能存放的TLB 表项就越多,TLB命中率就越高,但是TLB的容量是有限的。
目前Linux内核默认采用4KB大小的小页面,如下图所示,
如果一个程序使用512个小页面,即2MB大小,那么至少需要512个TLB表项才能保证不会出现TLB未命中的情况。但是如果使用2MB大小的巨页,那么只需要一个TLB表项就可以保证不会出现TLB未命中的情况。对于消耗的内存以吉字节为单位的大型应用程序,还可以使用以吉字节为单位的大页,从而减少TLB未命中情况的出现次数。
虚拟cache
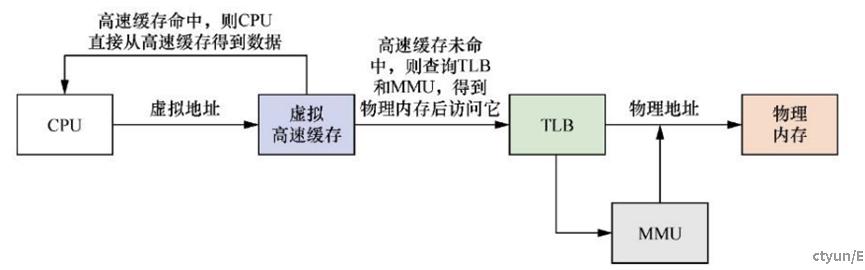
如上图所示,CPU使用虚拟地址来寻址高速缓存,我们称为虚拟高速缓存。处理器在寻址时,首先把虚拟地址发送到高速缓存中,若在高速缓存里找到需要的数据,那么就不再需要访问TLB和物理内存。
物理cache
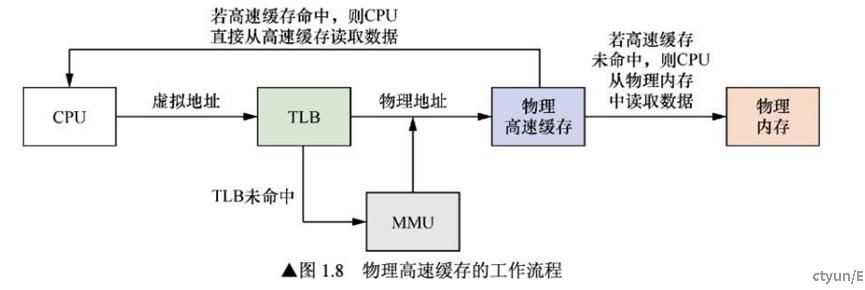
如上图所示,当处理器查询MMU和TLB得到物理地址之后,使用物理地址去查询高速缓存,我们称为物理高速缓存。使用物理高速缓存的缺点就是处理器在查询MMU和TLB后才能访问高速缓存,增加了流水线的延迟。
