


在FPGA的很多加速场景比如计算密集型场景往往需要对单笔计算的原始数据收集完全后才能启动计算流程,并在计算流程处理完成后才能释放。如果使用单Buffer来接收原始数据,那么在计算处理过程中,数据接收链路是闲置的,假设原始数据的接收时间是t1,计算处理时间是t2,那么整个链路的处理效率是1/(t1+t2),可以看出此时链路处理能力即未达到数据传输的瓶颈,也未达到计算处理的瓶颈,链路利用度不高。

图一 单buffer链路处理
本文采用一种乒乓buffer设计方法,开辟两片Buffer用于原始数据存储,轮流交替服务于原始数据接收和计算,这样可以充分利用计算的时间去接收下一波原始数据,从而提高整个链路的处理效率。值得注意的是为了保证计算数据的一致性,必须保证在计算和数据包的接收均完成后,才能进行Buffer功能的交替。
图二是t1<t2的情况,此时当计算处理Buffer1的数据时,Buffer2开始接收原始数据,当其接收完一个完整的用于计算的原始数据后,由于计算还未完成,需等待计算完成后,Buffer1和Buffer2的功能进行交换,此时Buffer1开始接收原始数据,计算处理Buffer2的数据。可以看出,两个Buffer功能交换的周期是t2,计算处理效率是瓶颈点,此时链路的处理效率是1/t2。
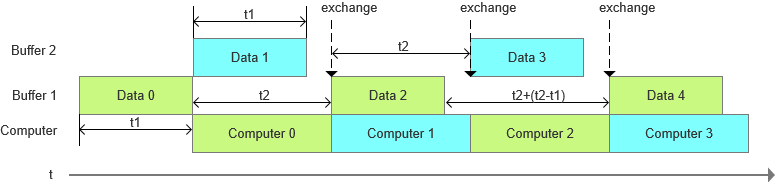
图二 双Buffer链路处理(t1<t2)
图三是t1>t2的情况,此时当计算处理Buffer1的数据时,Buffer2开始接收原始数据,当计算处理完成Buffer1的数据后,由于Buffer2还未完成原始数据的接收,需等待Buffer2接收完一个完整的用于计算的原始数据后,Buffer1和Buffer2的功能进行交换,此时Buffer1开始接收原始数据,计算处理Buffer2的数据。可以看出,两个Buffer功能交换的周期是t1,数据传输效率是瓶颈点,此时链路的处理效率是1/t1。
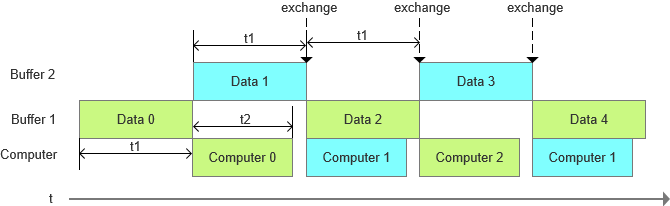
图三 双Buffer链路处理(t1>t2)
本文的乒乓Buffer方案,可以达到的链路处理效率是1/Max(t1,t2),此时已经达到链路上数据传输效率或者计算处理效率的瓶颈点,链路利用度已到最大,在FPGA计算密集型等场景可实现深度加速。
