


大数据常用架构之lambda架构
前言
目前大数据领域有两个成熟的架构体系,分别是Lambda架构和Kappa架构,它们是处理海量数据的两大热门选择,分别以融合批处理和实时处理,以及专注于流处理的方式,为各大公司提供了成熟的技术解决方案。
关于Lambda架构
Lambda架构设计的目的旨在提供一个能满足大数据系统关键特性的架构,包括高容错、低延迟、可扩展等,它整合离线计算与实时计算,融合不可变性、读写分离和复杂性隔离等原则,可集成Hadoop、Kafka、Spark、Storm等各类大数据组件。Lambda是用于同时处理离线和实时数据的,可容错的,可扩展的分布式系统,它具有鲁棒性,提供低延迟和持续更新,可用于机器学习、物联网和流处理场景。
Lambda架构的诞生离不开现有设计思想和架构的铺垫,如事件溯源架构和命令查询分离架构。
lambda架构可分解为三层,批处理层、加速层和服务层。
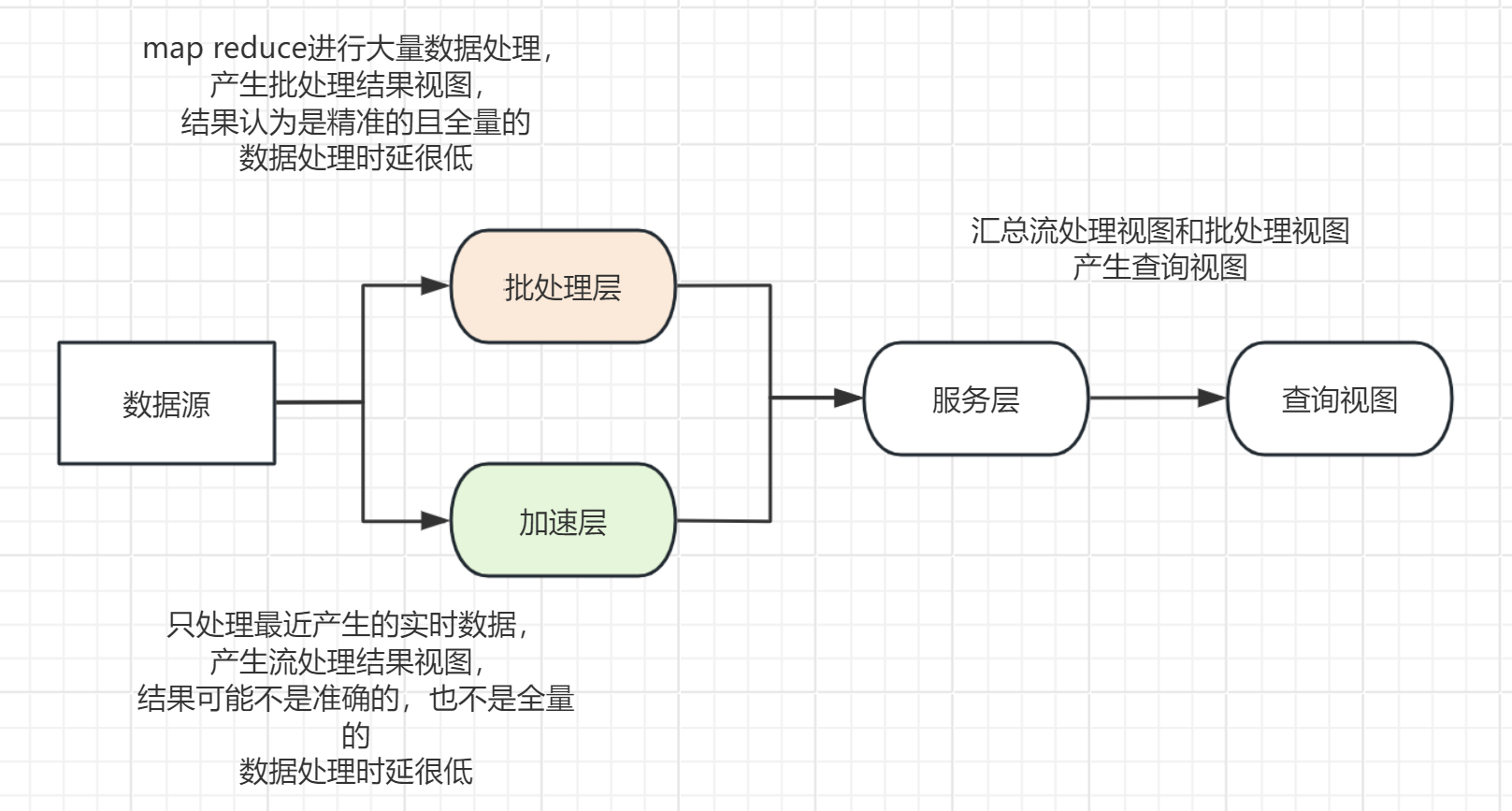
设计批处理层(Batch Layer)和加速层(Speed Layer)的依据
- 容错性。Speed Layer中处理的数据也不断写入Batch Layer, 当Batch Layer中重新计算的数据集包含Speed Layer处理的数据集后,当前的Real-time View就可以丢弃,这也就意味着Speed Layer处理中引入的错误,在Batch Layer重新计算时都可以得到修正。这一点也可以看成是CAP 理论中的最终一致性 (Eventual Consistency)的体现。
(CAP理论,指的是在一个分布式系统中,Consistency(一致性)、Availability(可用性)、Partition Tolerance(分区容错性),不能同时成立。) - 复杂性隔离。 Batch Layer处理的是离线数据,可以很好地掌控。 Speed Layer采用增量算法处理实时数据,复杂性比Batch Layer要高很多。通过分开Batch Layer和Speed Layer,把复杂性隔离到Speed Layer,可以很好地提高整个系统的鲁棒性和可靠性。
横向扩容。当数据量/负载增大时,可扩展性的系统通过增加更多的机器资源来维持性能。也就是常说的系统需要线性可扩展,通常采用scale out(通过增加机器的个数)而不是scale up(通过增强机器的性能)
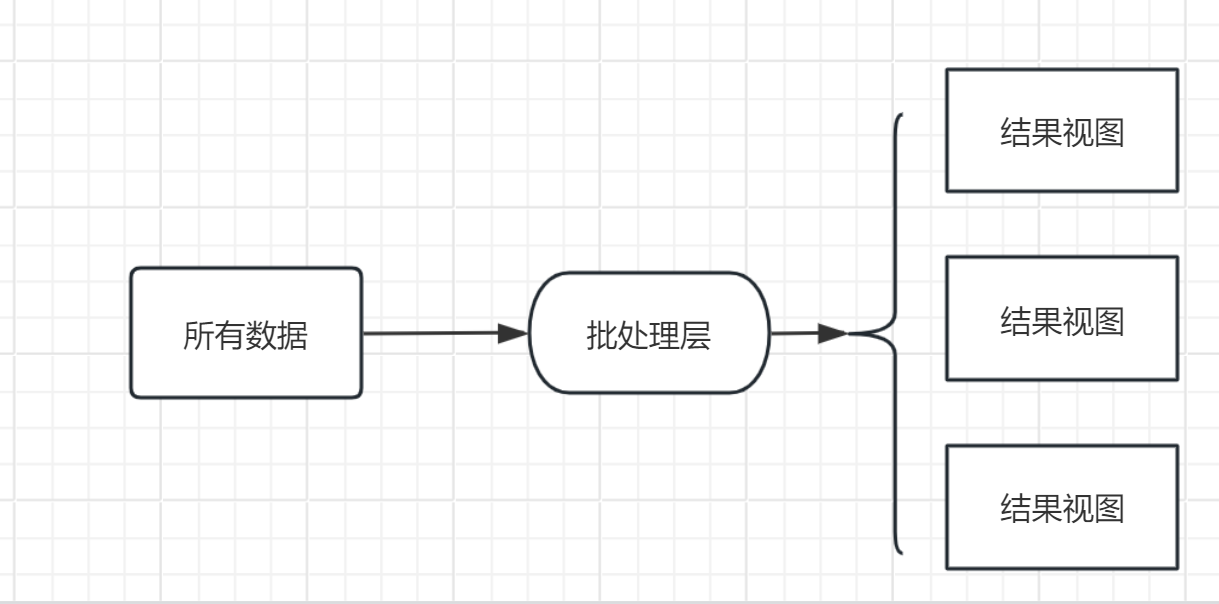
批处理层
批处理层是Lambda架构的基础层,主要负责处理离线数据。它接收原始数据流,并进行批量处理和分析。处理的数据集数据必须具有以下三个属性
-
数据是原始的。
-
数据是不可变的。
-
数据永远是真实的。
Monoid 特性(在数学上做分布+合并的操作)让我们可以将计算分解到多台机器并行运算,然后再结合各自的部分运算结果得到最终结果。同时也意味着部分运算结果可以储存下来被别的运算共享利用(如果该运算也包含相同的部分子运算),从而减少重复运算的工作量。
主要特点包括: -
高可靠性:批处理层使用容错性较强的分布式文件系统(如Hadoop HDFS)存储和处理数据,在处理过程中可以处理故障和错误。
-
长时间窗口:批处理层可以使用较长的时间窗口进行数据处理,因为它处理的是离线数据,不要求实时性。
-
复杂计算:批处理层可以进行复杂的数据计算和分析任务,例如大规模数据聚合、数据清洗、机器学习模型训练等。
如果预先在数据集上计算并保存查询函数的结果,查询的时候就可以直接返回结果(或通过简单的加工运算就可得到结果)而无需重新进行完整费时的计算了。这里可以把Batch Layer看成是一个数据预处理的过程。我们把针对查询预先计算并保存的结果称为View,View 是 Lambda 架构的一个核心概念,它是针对查询的优化,通过View即可以快速得到查询结果。
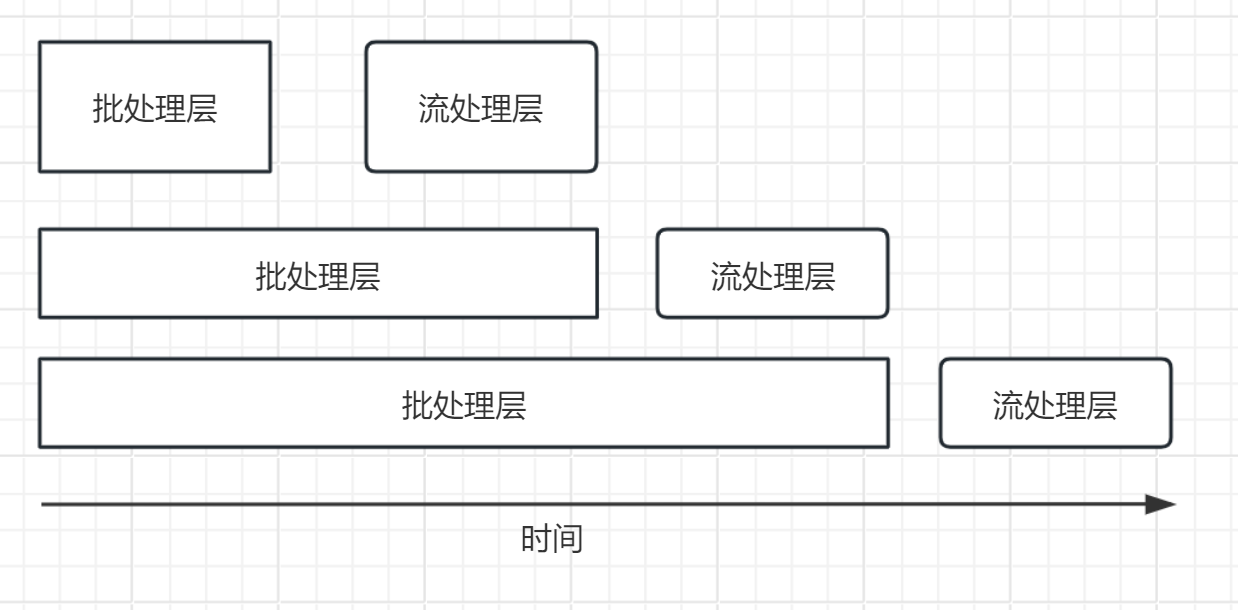
加速层
加速层是Lambda架构的实时处理层,负责处理实时数据流。它的作用是提供低延迟的查询结果,以弥补批处理层的延迟。
主要特点包括:
- 实时性:加速层处理实时数据流,可以快速响应查询请求,提供近实时的结果。
- 部分数据集:加速层处理的数据集通常是部分数据,而不是全部数据。它会根据实时数据流生成增量更新,以保持数据的最新状态。
- 简单计算:加速层通常执行较简单的计算任务,例如数据过滤、聚合、索引等。由于实时性要求较高,计算任务需要轻量级和高效。
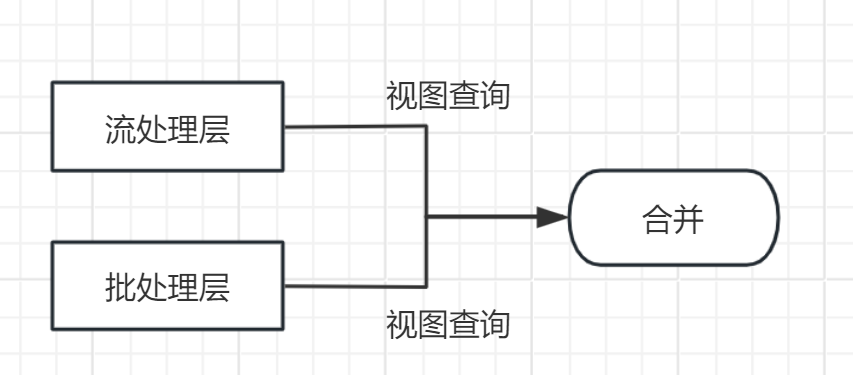
服务层
服务层是Lambda架构的最上层,负责提供数据查询和服务接口。它整合批处理层和加速层的结果,为用户提供统一的访问接口。主要特点包括:
- 统一查询接口:服务层将批处理层和加速层的结果进行整合,为用户提供统一的查询接口。用户可以通过该接口查询历史数据和实时数据。
- 数据合并:服务层将批处理层和加速层的结果进行合并,保证查询结果的完整性和一致性。
- 数据展示和分发:服务层可以将查询结果展示给用户,并提供数据分发接口,将数据发送给其他系统或应用。
主要技术实现
Hadoop(HDFS)作为主数据存储层,负责存储大规模数据集。Spark或Storm构成速度层,提供快速的数据处理能力,特别适合需要迭代计算的数据挖掘和机器学习任务。HBase或Cassandra作为服务层,提供实时的数据访问和更新。Hive用于创建可查询的视图,使得数据可以被方便地查询和分析。
