


一、前言
fluentd是日志收集器的一种,类似的还有fluent bit、filebeat等。
二、部署
以Damenset形式部署,在每个节点上运行节点级日志记录代理,另外有边车模式,这些都是集群级别的日志收集策略。
2.1、架构图
Elasticsearch+fluentd+kibana(EFK)总的架构图如图所示:
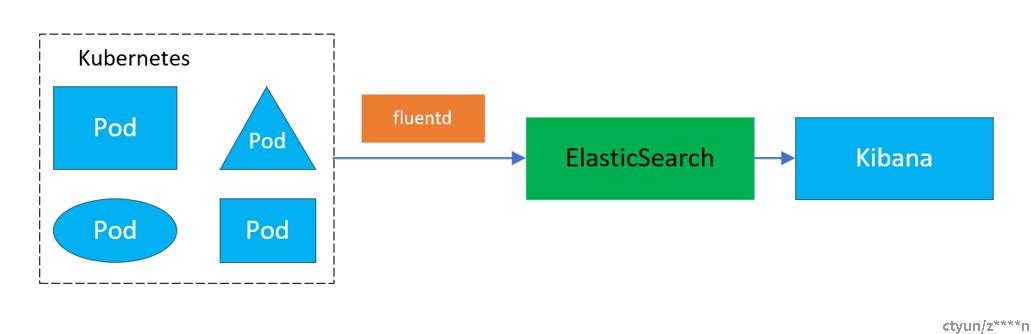
|
组件名称 |
用途 |
部署机器 |
|
fluentd |
收集每台node上pod容器的日志 |
任一台可执行k8s的机器 |
|
es |
存储fluentd收集过来的日志 |
- |
|
kibana |
可视化日志 |
docker内或者k8s内均可 |
kubectl get node(显示当前集群机器)
以Daemonset形式部署,会在每个node机器上部署一个fluentd。
2.2、日志源设置
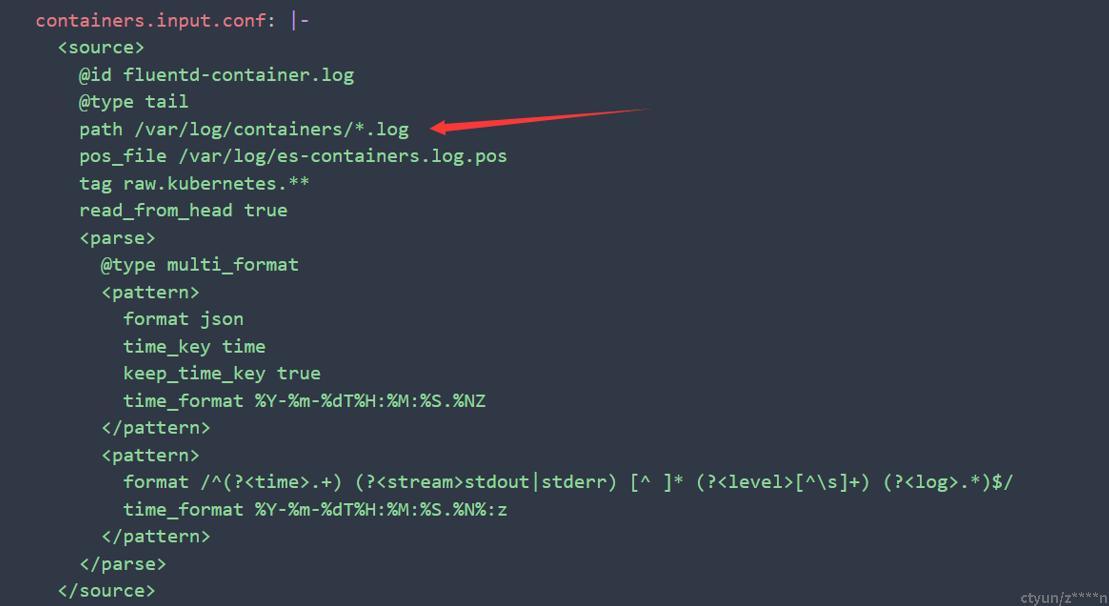
箭头处所指为日志挂载路径,k8s里每个pod运行会在宿主机某个路径下存储日志文件,这个是一般的存储位置。pattern部分是对日志时间格式的规定。
2.3、多余信息删除
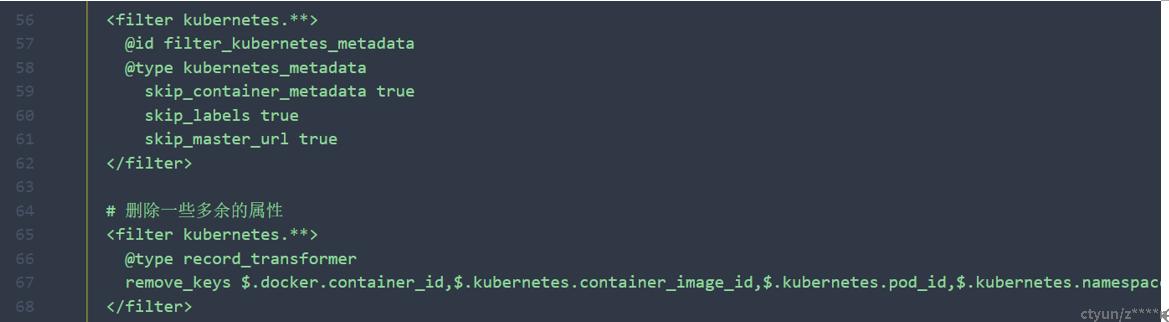
删除日志中一些无用的属性字段。在kibana中查看会有明显的感觉。
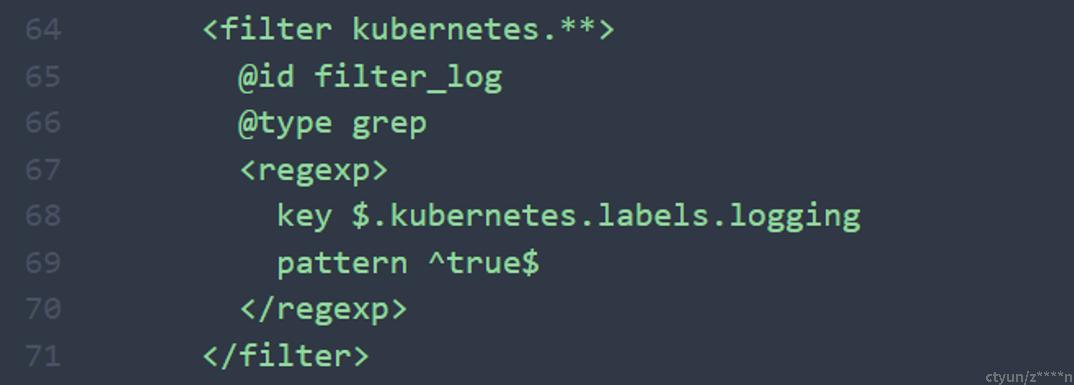
2.4、匹配特定label的容器
以上配置用于匹配特定label的容器,fluentd将只会收集带logging:”true”标签的容器的日志。
2.5、输出配置
下面分析输出配置:
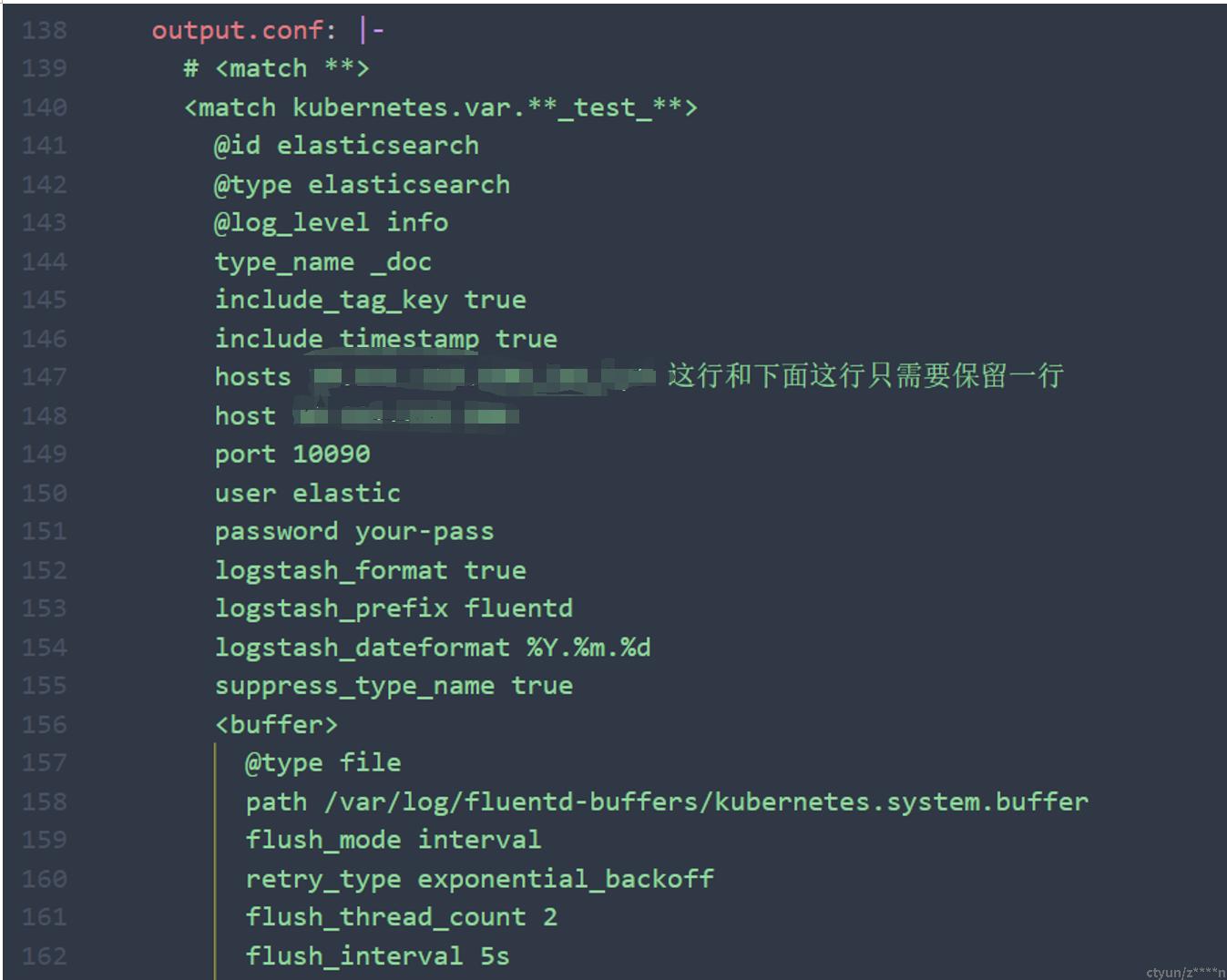
140行:设置收集器想要收集哪个namespace下的容器日志。
141-151行:填写elasticsearch相关信息,迁移只需要修改连接信息。host和hosts只能写一个,当写hosts时,多个ip以逗号隔开。
152-155行:设置索引格式为按天创建,例如:fluentd-12.26
156行及以下:设置日志缓冲区大小,日志会先存到缓冲区,然后再打到es上去。
