


一、对比学习概念简介
对比学习是一种自监督学习方法,主要使用在不同上下文中出现的相同事物的两种表现形式来训练模型。在对比学习中,首先需要识别和提取出原始数据中的“正样本”和“负样本”。正样本一般指的是相同事物的两种不同表现形式,而负样本则指的是不同事物的表现形式。模型的目标就是学会区分这两种情况。
假设已经有一个编码好的query h(一个特征),以及一系列编码好的样本h0,h1,h2,...,那么h0,h1,h2,...可以看作是字典里的key。假设字典里只有一个key即h+是跟h是匹配的,那么h和h+就互为正样本对,其余的key为h的负样本。
一旦定义好了正负样本对,就需要一个对比学习的损失函数来指导模型来进行学习。这个损失函数需要满足这些要求:
1、当h和唯一的正样本h+相似,并且和其他所有负样本key都不相似的时候,这个loss的值应该比较低。
2、如果h和h+不相似,或者h和其他负样本的key相似了,那么loss就应该大,从而惩罚模型,促使模型进行参数更新。
由上可知,对比学习的损失函数的目的主要在于使得模型可以更好的区分正负样本,在训练过程中,模型尝试最大化正样本对的相似性分数,并最小化负样本对的相似性分数。想要得到更好的训练效果,需要针对不同的场景选择合适的损失函数。
二、常见损失函数介绍
1、CoSENT-Loss
在对比学习中,使用过于简单的负样本可能会使得模型学习不充分,使用难负样本可以使模型获得能好的能力,但是对于难负样本来说,其一般与正样本语义不相同但字面上有比较多的重合,即对于难负样本来说,虽然其语义不同,但依然是“相似”的,因此不能一味的将正负样本的距离越拉越大,这样可能会使得模型过拟合,失去了泛化性。因此苏剑林在2022年提出了CoSENT目标来对对比学习的损失函数进行进一步的优化,CoSENT目标要求对于任意的正样本,只要其大于负样本对之间的相似度即可,至于大多少,模型自己决定就好。CoSENT目标的表达式如下所示:
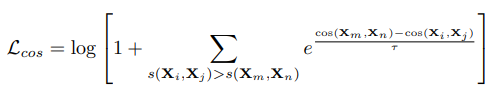
其中(i,j)是正样本,(m,n)是负样本。
(2)Angle-Loss
可以看到,为了计算两个向量的相似度,大多采用的是余弦相似度。考虑到余弦函数存在饱和区域(即函数值接近1或者-1的区域),在这些区域内,函数的梯度接近于零,在反向传播过程中,如果梯度值非常小,这可能会导致梯度消失问题,使网络难以学习,因此有学者提出可以使用AngleLoss来对这种情况进行改善,如下图所示:
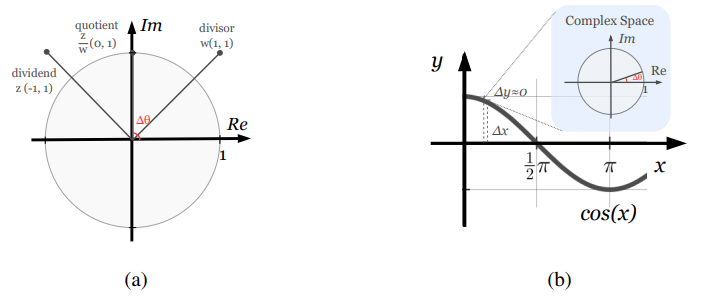
AngleLoss将原本的余弦函数映射到了复数空间,把原本计算不同向量的余弦相似度转换为计算不同向量在复空间中的角度差,具体实践主要是将原本n维的向量一分为二,前半部分看作实部,后半部分看作虚部,结合极坐标系的一系列公式可以得到如下的损失函数:
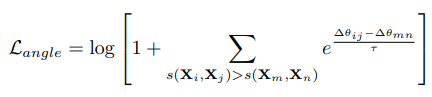
(3) IN-BATCH NEGATIVE-Loss
前文的CoSENT-Loss和Angle-Loss都需要标注好的有监督数据,如(text1,text2,label)的形式,这样的话负样本就仅限label为0的数据。而在真正的训练中,除了标注为1的正样本以外,同一批次内其他所有其他正样本也可以视为该正样本的负样本,因此In-batch Negative loss被提出。In-batch Negatives 策略的训练数据为语义相似的 Pair 对,策略核心是在 1 个 Batch 内同时基于 N 个负例进行梯度更新,将Batch 内除自身之外其它所有 Source Text的相似文本 Target Text 作为负例,以此来对训练数据进行增强,其表达式如下:
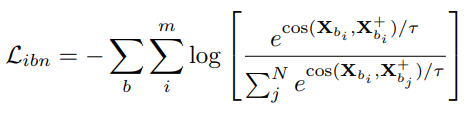
In-batch Negative loss由于不需要额外标注大量的数据,且可以充分利用训练数据,因此较为常用,在我们的业务场景中使用较多。
(4)IFM(隐式特征修改)
在真实产品场景的模型微调中,我们发现使用In-batch Negative loss容易造成模型对批内出现频率较高的词汇学习权重较低,如大部分相似问都存在“弹性云主机”或“云电脑”的产品名称时,模型训练时就会认为这些是简单特征从而对产品名称的关注度降低,更多的去学习意图,这会导致模型倾向于给“如何开通弹性云主机”和“如何开通云电脑”打较高的相似度分数(这在业务上是非常严重的bad case)。有学者将这种情况称为“特征抑制”,并提出了一种隐式特征修改的改进策略,即在infoNCELoss的基础上增加一个对抗性扰动损失Epstein,增加后的新的损失函数如下:
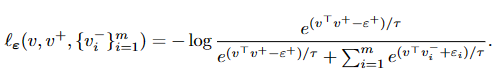
通过让正样例减Epstein,负样例增加Epstein,让模型更多的去学习和关注简单特征。
三、对比试验结果
基于上文提到的四种不同的损失函数,我完成了代码的适配,并在内部的37w条相似问数据集上,以bge-large-v1.5为基座进行了一系列的实验,实验结果如下:
|
loss |
top1 |
top2 |
top3 |
top4 |
top5 |
nomatch |
|
IBN-Loss-128*2 |
1604 |
160 |
56 |
27 |
17 |
160 |
|
Angle-Loss-128*2 |
984 |
140 |
57 |
58 |
36 |
749 |
|
CoSENT-Loss-128*2 |
1597 |
130 |
63 |
37 |
19 |
178 |
|
IBN+Angle-128*2 |
1587 |
153 |
60 |
30 |
22 |
172 |
|
CoSENT+Angle-128*2 |
1597 |
132 |
59 |
37 |
22 |
177 |
|
IBN+CoSENT-128*2 |
1593 |
136 |
69 |
29 |
24 |
173 |
|
IBN+CoSENT+Angle-128*2 |
1596 |
136 |
65 |
32 |
22 |
173 |
|
IBN-Loss-256*2 |
1629 |
138 |
46 |
18 |
21 |
172 |
|
IBN+增加Epstein-256*2 |
1620 |
140 |
60 |
25 |
17 |
162 |
从实验结果可以看出:
1、 In-batch Negative loss的效果最佳,其次是CoSENT-Loss,Angle-Loss单独使用的效果较差,但和CoSENT-Loss组合使用时效果有所提升;由于此处未对组合loss各自的权重值进行超参搜索,只采用了论文里提供的权重,因此有可能组合loss在进行超参搜索之后会获得更优效果;
2、 在In-batch Negative loss的基础上增加Epstein后在top1的召回上效果反而下降,但是top5的召回率有所提升;(后续发现了一个更优的方案——对数据做block shuffle,降低同一个产品名称在同一批次出现的频率,也可以使模型获得更好的能力)。
3、 同样使用In-batch Negative loss,增大了训练的batchsize后可以获得更好的效果(batchsize对训练结果的影响较大,在数据集量级较少的情况下,建议选择较小的batchsize,可以使模型学习更多的step,且不容易碰见错误负样本,在数据集量级较大的情况下,更大的batchsize+In-batch Negative loss可以使得模型见过更多的负样本,从而获得更好的能力)。
