


一、DLedger机制
RocketMQ4.5版本以后,引入了DLedger机制,DLedger是利用了Raft算法实现Broker主从节点的故障自动转移以及数据同步。
比如下图中,Broker集群中有一个Master-Broker节点,2个Slave-Broker节点,那么一份数据就会有三个副本,在DLedger机制中,我们通常把Master-Broker节点叫做Leader,Slave-Broker节点叫做Follower:
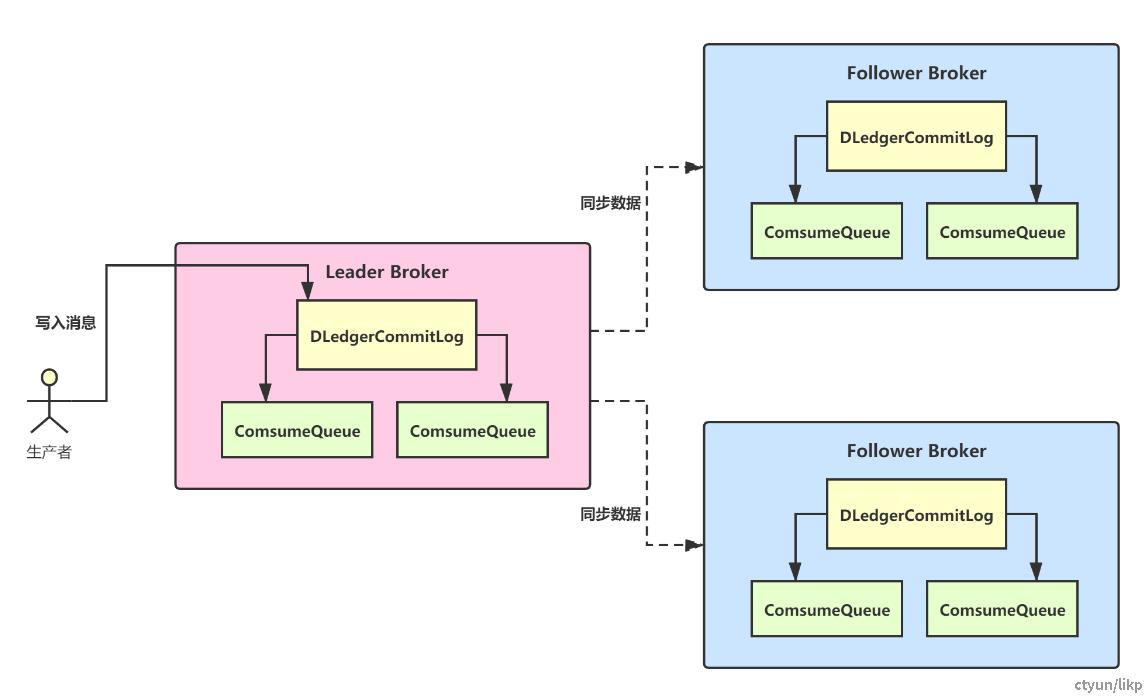
生产者只能往Leader Broker,也就是Master-Broker写入消息,如果Leader Broker宕机,DLedger会从其它两个Follower Broker中选举出一个新Leader,继续接受客户端的数据写入。
上图可以看到,DLedger有自己的CommitLog机制——DLedgerCommitLog,实际上DLedger替换掉了原来Broker管理的CommitLog,相当于现在CommitLog文件由DLedger来接管了。
1.1 Leader Broker选举
DLedger机制基于Raft协议来进行多台机器的Leader Broker选举。简单来说,上述三台Broker机器启动的时候,他们都会先投票给自己作为Leader,然后告诉其它Broker也来选自己,每个Broker如果收到其它人的请求并且自己还没投过票,就要接受别人的投票请求。
举个例子,刚开始,Broker01投票给自己,Broker02投票给自己,Broker03也投票给自己,然后他们各自发消息给别人说:“快来投我,快来投我”。但是每人只有一票,所以第一轮选举是失败的。
然后各个Broker进入休眠,休眠是时间是随机的,比如Broker01休眠3秒,Broker02休眠5秒,Broker03休眠4秒。当Broker01率先苏醒后,依然先给自己投票,然后发消息给别人让别人投自己,此时Broker03苏醒,还没来得及投自己就收到了Broker01的请求,所以必须投票给Broker01,同时也会告诉Broker02投票给Broker01。最后,Broker02苏醒,发现Broker01已经拥有了半数选票,并且也收到了Broker01和Broker03的请求,所以也会投票给Broker01,最终,Broker01当选Leader。
上述就是Raft算法“选举过程”的简单描述,只要有某个节点得到超过半数(3/2+1=2)的选票,就成为了Leader。
1.2 数据同步
Leader Broker需要将数据同步给Follower Broker。在Raft算法中,这一过程叫做“Log Replication”。简单来说,数据同步分为两个阶段:uncommitted阶段、commited阶段。
首先,Leader Broker接受到一条消息后,会标记为uncommitted状态,然后他会通过自己的DLedgerServer组件将这个uncommitted的消息数据发送给Follower Broker的DLedgerServer。
接着,Follower Broker的DLedgerServer收到uncommitted消息之后,必须返回一个ack给Leader Broker的DLedgerServer,如果Leader Broker收到了超过半数Follower Broker返回的ack,就会将消息标记为committed状态。
最后,Leader Broker上的DLedgerServer就会发送commited消息给Follower Broker机器的DLedgerServer,让他们也把消息标记为comitted状态。
这个其实就是基于Raft协议实现的两阶段数据同步机制。
二、总结
RocketMQ中Broker的高可用机制,整体还是比较容易理解的,很多开源框架都利用了Raft算法的思想来实现高可用,比如Redis、Zookeeper,都是Raft算法或其变种。
这里,有童鞋可能要问了,万一整个Broker集群都挂了怎么办?这种情况事实上就相当于MQ彻底崩溃了,这个时候其实就需要另一种高可用的架构思路了,即业务系统自身的高可用。
通常这时要用到降级方案,将MQ的依赖暂时从业务系统中排除出去,比如将原先发送到MQ里的消息发送到缓存中,或者暂时存储到本地磁盘。之后一旦发现MQ恢复了,就用一个后台线程把之前持久化存储的消息都查询出来,然后依次按照顺序发送到MQ集群里去,这样才能保证你的消息不会因为MQ彻底崩溃会丢失。
