


从系统架构上来讲,我们之所以要在自己的系统中引入MQ,无非就是三个目的:解耦、异步、削峰。本章我们会先引入一个系统示例,以此为背景,展开我们对消息中间件-RocketMq使用的讨论,后续我们会分章节对一些核心问题进行分析。
这里补充一句,在使用各种分布式技术的过程中,我们脑子里一定要有四个概念:高性能、高可用、可扩展、数据一致性。如果你对一些常用的分布式框架很熟悉,就会明白,无论是哪一种分布式框架,其底层所有核心功能的实现一定是围绕上述四个基本概念来展开的。
一、系统背景
我们先来看一下业务系统的背景,这个系统将要贯穿本系列。这是一个普通的订单系统,用户浏览商品并通过订单系统进行下单:
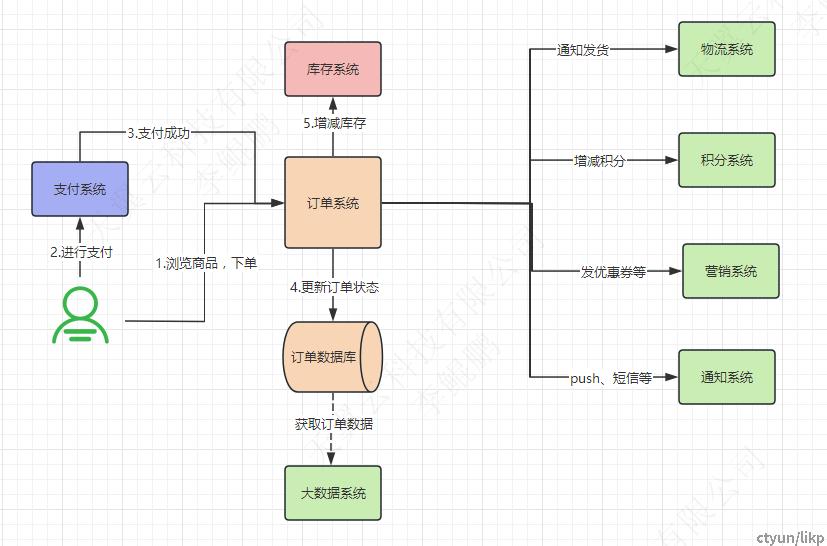
- 用户下单成功并确认完订单信息后,会调用支付系统的接口进行支付;
- 支付成功后,支付系统调用订单系统接口,通知“支付成功”;
- 订单系统更新数据库中订单的状态为“支付成功”;
- 订单系统调用库存系统的接口,进行扣减库存;
- 订单系统依次调用“物流系统”、“积分系统”、“促销系统”、“通知系统”的接口,进行发货通知、增加积分、发优惠券、短信通知操作;
- “大数据系统”会从订单数据库里查询订单数据,用于生成一些业务报表供运营使用。
上述就是整个业务的主体流程,我们本章先来分析下在这样一个系统架构下,订单系统会出现哪些问题,后续章节再来看看MQ是如何解决这些问题的。
1.1 同步调用问题
首先,最明显的,每次用户支付完一笔订单,订单系统就要同步执行一系列动作:
- 更新订单状态
- 增减库存
- 增加积分
- 发优惠券
- 短信通知
- 通知发货
这样一连串的接口同步调用,可能长达好几秒钟,对于用户来说,其直观感受就是支付完成后界面假死,几秒之后才响应支付结果,非常不友好。
1.2 性能问题
这样的一个系统架构,在“订单系统”水平扩展N个的情况下,虽然能扛下基本的峰值流量,但应付不了一些大型促销的业务场景(比如秒杀活动),因为瓶颈主要在数据库。我们假设正常的峰值流量是2000QPS,由于订单系统还涉及其它一些数据库访问操作,根据经验我们将数据库操作的此时放大2-3倍,也就是峰值情况下每秒大约有4000~5000的请求打到数据库:
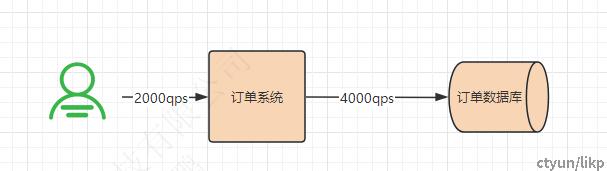
以MySQL数据库来说,16核32G的机器,优化后大约能抗个4000~5000TPS,所以在上述峰值流量下,虽然CPU和内存使用都会飚得很高,但也差不多能应付。但是在大促场景下,峰值流量会放大好几倍,所以这种架构下,数据库是根本扛不住的。
1.3 耦合问题
上述有一个流程是“通知发货”,物流系统一般会对接外部的第三方公司,当我们的系统对外产生依赖时,我们应该做最坏的打算,考虑依赖方的接口不可用了该怎么办?事实上,除了“扣减库存”属于核心交易链路外,其它的“通知发货”、“增加积分”、“发优惠券”、“短信通知”都属于非核心交易链路,我们应该将它们从核心链路中解耦出去。
1.4 大数据传输问题
“大数据系统”会从订单数据库里查询订单数据,由于数据库中每日的订单数据通常是比较多的,频繁让外部系统直接通过数据库查数会影响订单系统本身的性能。试想以下,在高峰场景下,订单数据库本身去支撑正常业务流量就很吃力了,此时CPU和内存都比较吃紧,这时再来个“大数据系统”从我这里大量查数,简直是添乱。
1.5 状态补偿问题
做过支付系统的童鞋应该都知道,对于依赖“支付通知”来确认订单状态的业务,必须要考虑“补偿”机制,也就是说:万一因为网络等原因,订单系统没收到“成功”的支付通知怎么办?除此之外,用户也很可能下完订单之后就把页面关闭掉了,最终并没有去支付。
所以对于这些”中间状态“的订单,我们必须要有一种补偿机制去确认它的最终状态。一种常见的思路是:订单系统后台起一个定时任务,每隔一段时间扫描下所有”中间状态“的订单,确认下是否要关闭它。但是这种方案在订单量小的情况下还好说,一旦订单量大了,就会出现性能瓶颈,而且重复扫描的效率也太低。
二、技术选型
了解完了业务系统的背景和存在的问题,我们就要通过MQ来解决上述的问题,目前常用的开源分布式消息中间件主要有四种:ActiveMQ、RabbitMQ、RocketMQ、Kafka。因为订单系统对性能要求通常是比较高的,所以我们主要在RocketMQ和Kafka中选择。事实上,两种MQ都可以作为我们最后的选择,但是本系列还是先以RocketMQ来讲解学习。
