


Rust过程宏解决的问题
在前一篇 Rust入门(六) —— rust宏编程(模式宏 macro_rules!),我们讲述了Rust的模式宏编程;它接近于C语言的宏,属于符号替换。本节我们来讲解Rust另一类不一样的宏编程:过程宏(procedural macros)。
过程宏,更像函数(一种过程类型)。过程宏接收 Rust 代码作为输入,在这些代码上进行操作,然后产生另一些代码作为输出,而非像声明式宏那样匹配对应模式然后以另一部分代码替换当前代码。
有三种类型的过程宏(自定义派生(derive),类属性和类函数),不过它们的工作方式都类似。
首先,考虑这样一个场景:
某个任务调度执行系统中,有很多中Action;我们希望,每个Action都提供一个explain方法来显示该命令的一些说明信息。
由于涉及到多个Action,那么一种通用做法是定义一个trait,声明explain方法;每个Action实现时都实现该trait。示意如下:
trait Explanation {
fn explain(&self);
}实现一个List命令:
pub struct ActionList {
name:String,
// 该命令的其他成员
}
impl Explanation for ActionList {
fn explain(&self) {
println!("Action name is {}", self.name)
}
}当添加另外一个命令ActionConnect时,同样我们需要为其实现Explaination 特性:
pub struct ActionConnect {
name: String
// 该命令的其他成员
}
impl Explanation for ActionConnect {
fn explain(&self) {
println!("Action name is {}", self.name)
}
}对比发现,该模型下,ActionList和ActionConnect实现Explaination特性的接口几乎是一样的(差异指在于self的内容)。进一步,当这样的Action还存在的更多时,我们不得不重复的写着相同的代码!
于是,我们希望有一种更简单的方法,可以自动为Action添加Explanation实现,从而避免写重复代码。
Rust derive 宏就是在这样的需求下被设计出来的!
基于Rust derive 宏,Action实现Explanation只需要在声明上添加derive宏标注即可:
#[derive(Explanation)]
pub struct ActionConnect {
name: String
// 该命令的其他成员
}当然,能够使用上述的derive标注是有条件的,那就是我们必须实现Explanation的派生宏!
自定义derive宏
参考rust程序设计语言 对宏章节的描述,我们可以自定义derive宏。
为方便演示,我们先创建一个actions工程,并添加传统基于trait的Action实现。
cargo new actions
然后在actions 目录下,创建explanation库crate
cd actions
cargo new explanation --lib
完成后,actions目录结构如下:

在actions/explanation/src/lib.rs中添加 Explanation trait定义:
pub trait Explanation {
fn explain(&self);
}在actions/src/main.rs中添加使用 Explanation的:
use explanation::Explanation;
struct ActionList {
name: String
}
impl Explanation for ActionList {
fn explain(&self) {
println!("Action name is {}", self.name)
}
}
fn main() {
let act = ActionList{
name: "List".to_string(),
};
act.explain()
}
由于我们独立定义了explanation 包,因此main包需要在Cargo.toml中声明依赖:
[package]
name = "actions"
version = "0.1.0"
edition = "2021"
[dependencies]
explanation = { path = "./explanation" }
然后,尝试运行该工程:
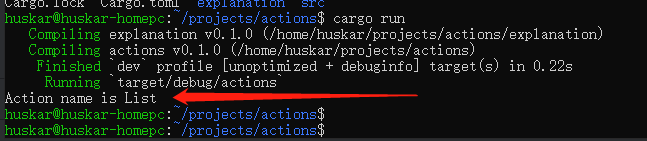
通过传统方式,对struct实现trait,已经可以正常运行!
接下来,我们在actions目录下,创建Expaination的derive宏的crate:
cargo new explanation_derive --lib
创建完成后,action目录结构为:

注意:创建过程宏时,其定义必须驻留在它们自己的具有特殊 crate 类型的 crate 中。Rust这么做,是出于复杂的技术原因,或许未来的版本中会消除这些限制。
derive包创建和内容要求如下:
(1)derive的crate命名必须与trait 定于的crate包名称呼应,规则为“【trait包名】_derive”。
(2)derive包需要引入syn和quote依赖,它们是处理过程宏的必要工具;同时,需要对包使能‘proc-macro’功能。这些配置需要配置在derive 包的Cargo.toml中,内容如下:
[package]
name = "explanation_derive"
version = "0.1.0"
edition = "2021"
[lib]
proc-macro = true
[dependencies]
syn = "2.0.66"
quote = "1.0"(3)derive包需要实现一个类型为公开的xxx_derive函数,接受TokenStream类型,返回为TokenStream类型,函数原型为:pub fn xxx_derive(input: TokenStream) -> TokenStream 。同时需要对该函数通过#[proc_macro_derive(...)] 标注,制定该派生宏的名字(通常与trait名字一样,但不是强制的)。
下面是actions/explanation_derive/src/lib.rs内容:
extern crate proc_macro;
use proc_macro::TokenStream;
use quote::quote;
use syn;
use syn::DeriveInput;
#[proc_macro_derive(Explanation)]
pub fn explanation_derive(input: TokenStream) -> TokenStream {
// 基于 input 构建 AST 语法树
let ast: DeriveInput = syn::parse(input).unwrap();
// 构建特征实现代码
impl_explanation(&ast)
}
fn impl_explanation(ast: &syn::DeriveInput) -> TokenStream {
let name = &ast.ident;
let gen = quote! {
impl Explanation for #name {
fn explain(&self) {
println!("Action name is {}", self.name)
}
}
};
gen.into()
}关于TokenStream与DeriveInput是编译过程中的源码中间状态。xxx_derive()函数的核心功能就是,通关宏定义的方式,通过修改源码的抽象语法树,达到修改源码的目的!
要理解TokenStream和DeriveInput(AST)可能需要一些编译知识,我们在下一章也会简要介绍。所幸的是,得益于syn和quote库的支持,大部分情况下我们只需要按照上述的过程实现impl_xxx核心业务逻辑即可!
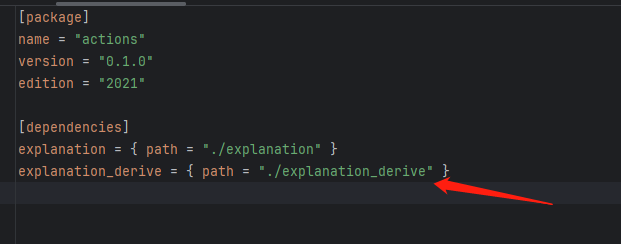
完成上述explanation_derive 包后,我们在main包进行引用测试:
(1)修改main包的Cargo.toml,引入explanation_derive依赖
(2)修改actions/src/main.rs,增加Connect命令,但采用derive宏的方式,实现Explanation 特性:
use explanation::Explanation;
use explanation_derive::Explanation;
struct ActionList {
name: String,
}
impl Explanation for ActionList {
fn explain(&self) {
println!("Action name is {}", self.name)
}
}
#[derive(Explanation)]
struct ActionConnect {
name: String,
}
fn main() {
let act = ActionList {
name: "List".to_string(),
};
act.explain();
let conn_act = ActionConnect {
name: "Connect".to_string(),
};
conn_act.explain();
}
执行效果:

bingo! 我们第一个自定义过程宏成功运行!
理解derive宏展开原理
从Rust编译说起
Rust derive宏基于现代编程语言常用的语法扩展这一机制,提供了安全可靠的宏编程方法(卫生宏)。讨论Rust的过程宏之前,我们先简单了解一下Rust源码的编译过程。概括性的,Rust编译大致可以分为以下步骤:
第一步:解析(Parsing)
Rust 编译器首先会读取源代码,并将其转换为抽象语法树(AST)。AST 是源代码的结构化表示,它捕获了代码的语法结构。
第二步:宏展开(Macro Expansion)
Rust 支持宏系统,允许用户定义代码生成器。在这一步,编译器会扩展所有的宏调用,将它们转换为具体的代码。
第三步:名称解析(Name Resolution)
编译器会解析代码中的名称(变量、函数等),并确定它们的作用域。这一步确保每个名称都能在其上下文中被正确解析。
第四步:类型检查(Type Checking)
Rust 是静态类型语言,编译器会检查所有表达式和变量的类型是否一致。这一步会验证类型的正确性,并确保类型安全。
第五步: 中间表示(HIR 和 MIR)
Rust 使用高层中间表示(HIR)和中层中间表示(MIR)来优化代码。在这一步,编译器会将 AST 转换为 HIR,然后进一步转换为 MIR。MIR 是一种简化的中间表示,便于进行各种优化。
第六步:优化(Optimization)
编译器对 MIR 进行一系列的优化,包括常量折叠、循环展开、内联等。这些优化旨在提高代码的性能和减少二进制文件的大小。
第七步:代码生成(Code Generation)
经过优化的 MIR 被转换为 LLVM IR(一种低层中间表示)。Rust 编译器使用 LLVM 库来进行底层优化和生成机器代码。
第八步:链接(Linking)
最终的机器代码被链接为可执行文件或库。链接器会将所有需要的代码片段和库依赖项结合在一起,生成最终的二进制文件。
从上述编译过程,可以看到,Rust的宏展开过程发生在源码解析为抽象语法树(AST)之后。
抽象语法树,是源代码编一个时的早期的中间状态,它是源代码的一种等价表达方式。如果提供某种机制,在编译过程中,对源码的AST进行合理修改(替换,增加等),而后进行后续的编译处理;只要对AST的更改符合语法规范、适配程序环境(变量、函数等定义和调用与源码匹配),那么后续编译过程会顺利进行,并且更改的内容也会被编译到最终二进制产出中;从结果上看,对AST修改这部分内容,就像是从源码来的一样!
上述过程,就是语法扩展的一种直观理解!
Rust的过程宏处理正是基于这一原理,过程为:
(1)源代码在第一阶段解析为常规的Token流,其中包括过程宏的标注信息;
(2)Rust编译过程中,设计了一个宏展开阶段,该阶段会处理AST,并根据AST中过程宏标注信息,对AST进行修改,生成新的AST(这里说法不严谨,rust过程宏处理的对象其实是TokenStream,但TokenStream不如AST直观,我们这里将TokenStream和AST看着一个东西,这样便于理解);
(3)基于更新后的AST继续执行后续的编译过程,从而实现通过定义过程宏实现对源码的更改!
从源码到AST
虽然,上一节我们将Parsing定义为一个编译步骤实现源码到AST的过程。但细致分来,还可以划分为词法分析、语法分析。
词法分析(Lexical Analysis)
词法分析的核心是将源码划分成一个Token流。每一个Token,代表一个不可分割的词法单元:一个关键字,一个标识符,一个字符串,一个操作符等等。Rust中的Token有很多种,比如:
- 关键字(keywords):
_,fn,self,match,if,macro, … - 标识符(identifiers):
get_xxx,set_xxx,is_enable,self, … - 整数(integers):
42,72u32,0_______0, … - 生命周期(lifetimes):
'a,'b,'a_rare_long_lifetime_name, … - 字符串(strings):
"","Leicester",r##"venezuelan beaver"##, … - 符号(symbols):
[,:,::,->,@,<-, … - 等等
Rust 编译器的词法分析器(lexer)读取源码并识别出这些标记;词法分析过程中,会清理掉注释,空格等。
例如,下面的rust代码:
let x = 27;
词法分析器可能生成以下标记序列:
- let
- x
- =
- 42
- ;
词法分析完毕后,源码被解析为Token流(上文提到的TokenStream可以看着这个阶段的产出,实际上可能会有些更进一步的处理)。
语法分析(Parsing)
语法分析是将标记序列转换为抽象语法树(AST)的过程。AST 是源代码结构的一种树形表示,它捕捉了代码的层次结构和语法关系。
Rust 编译器的语法分析器(parser)使用一种称为递归下降解析的技术来构建 AST。解析器会根据 Rust 语言的语法规则,递归地将标记序列解析为不同的语法构造(如表达式、语句、函数定义等)。
例如,对于以下 Rust 代码:
fn main() {
let x = 27;
println!("x is {}", x);
}
解析器会生成类似于以下结构的 AST:
Crate
└── Item
├── Function
│ ├── Name: main
│ ├── Parameters: ()
│ └── Body
│ ├── Statement: let x = 42;
│ └── Expression: println!("x is {}", x);
AST示例
上面的过程还是有些笼统,大家还不能构建出直观的理解和过程(如果要深入的理解这个过程,可能需要更细致的讲一下编译原理相关的内容,已经跳出本文的范畴,读者大大们自行补充吧)。
所幸的是,网络上有一些在线工具,可以直接翻译源码为AST。我们以 AST explorer 演示:
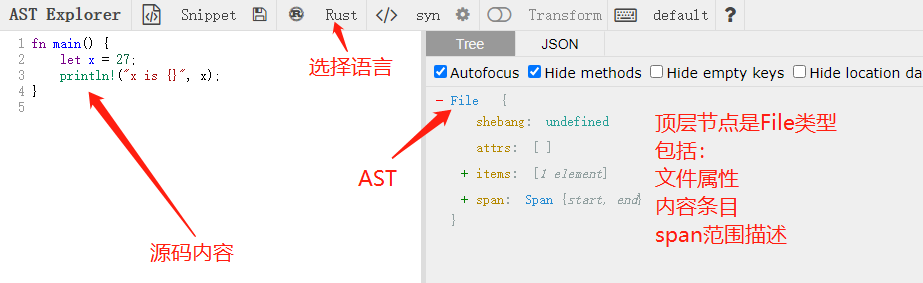
见截图,上述示意源代码在AST中根节点为File;可能存在文件相关的特殊内容(shebang:特殊行);可能存在多个文件属性attrs条目;可能包括多个Items类型;一个span用于描述内容范围(这个是每一级、每一个Token都会带的,用于标识节点的位置)。
进一步展开如下:
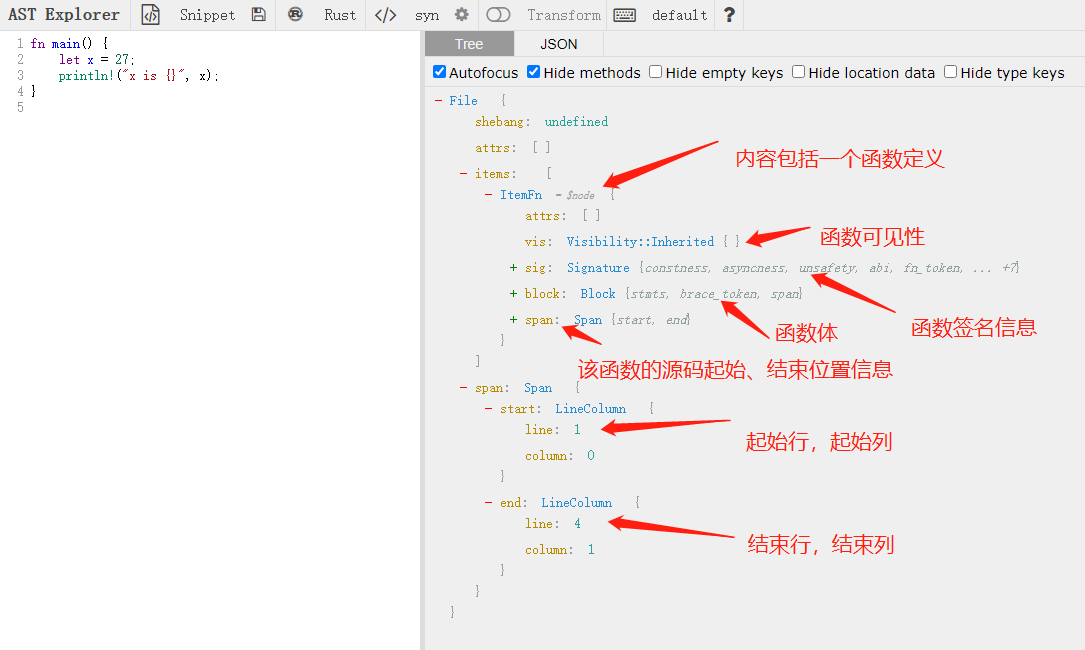
其中,Span是每一个节点都具备的成员,描述了节点的起始、结束位置信息,在后续实际编译过程中,用于内容检索,范围确定等。节点有隶属层级关系,它们的Span范围也存在包含关系。每一种Token,都可能有其独特的成员,这些成员大多遵循统一的编程范式,但不同语言中可能有不同的命名或不同成员类型。
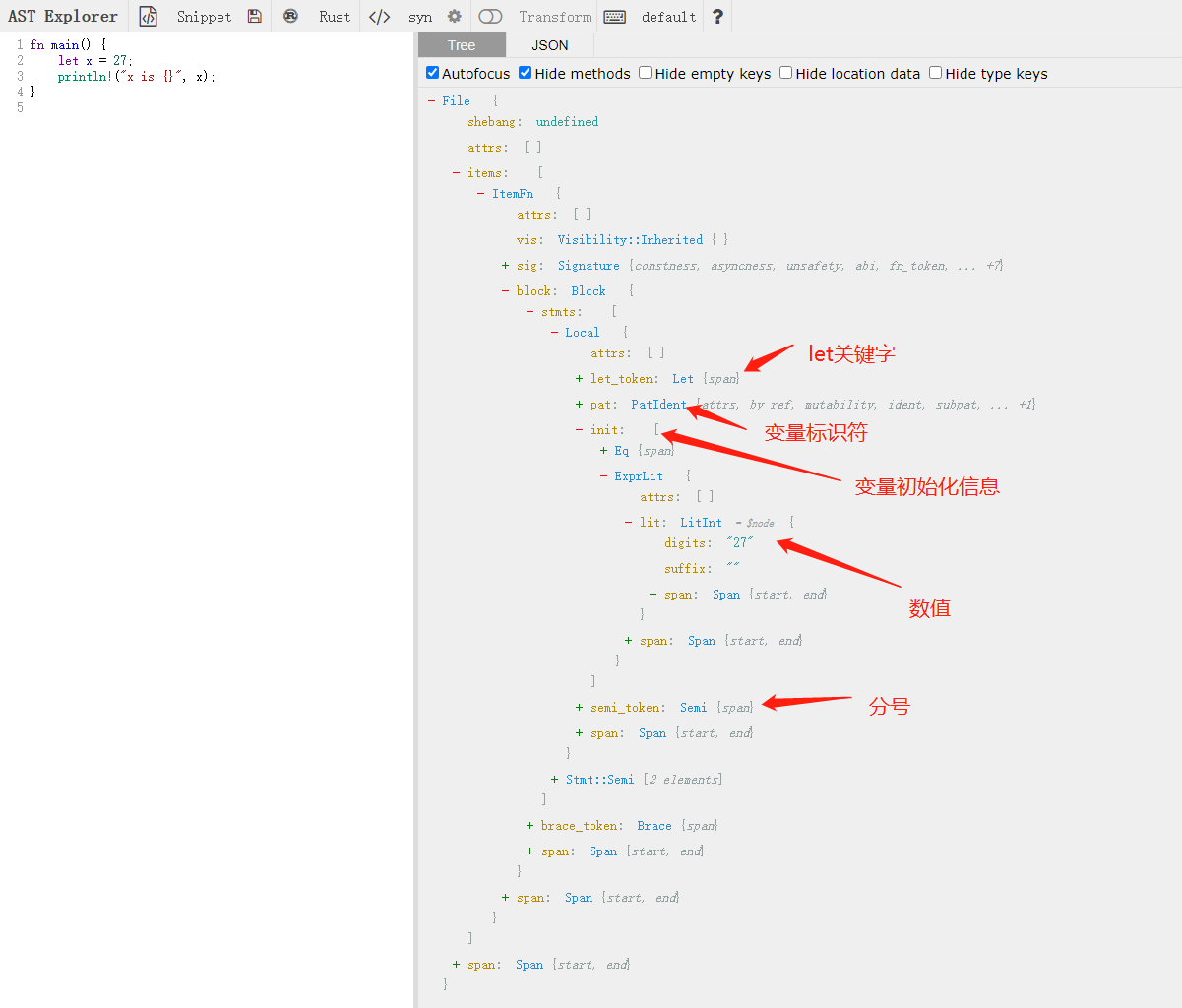
进一步展开,可以看到关键字,变量标识符,赋值符号,初始化信息等等,这样基本上能够和源码联系起来了!
结构体的AST
首先看一个原始ActionList节点的AST:
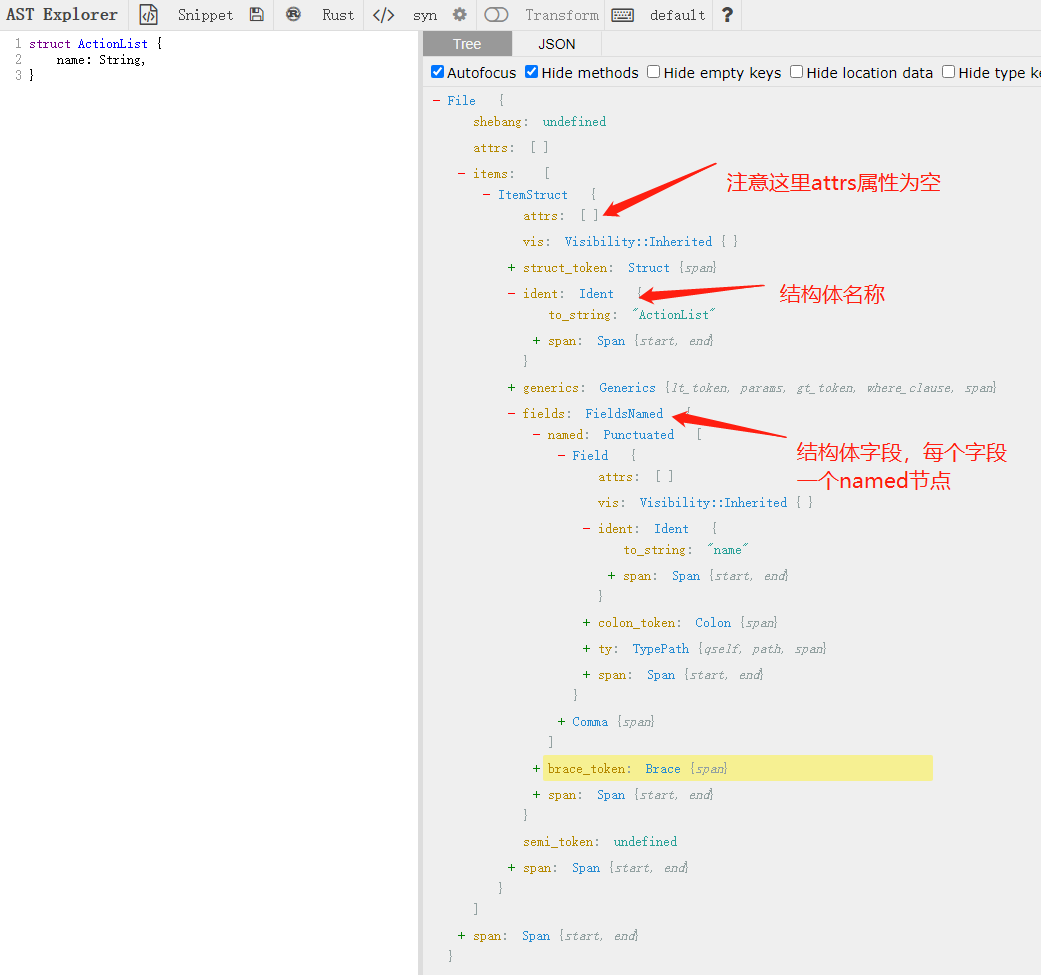
其次,当结构体存在trait实现时,其AST:
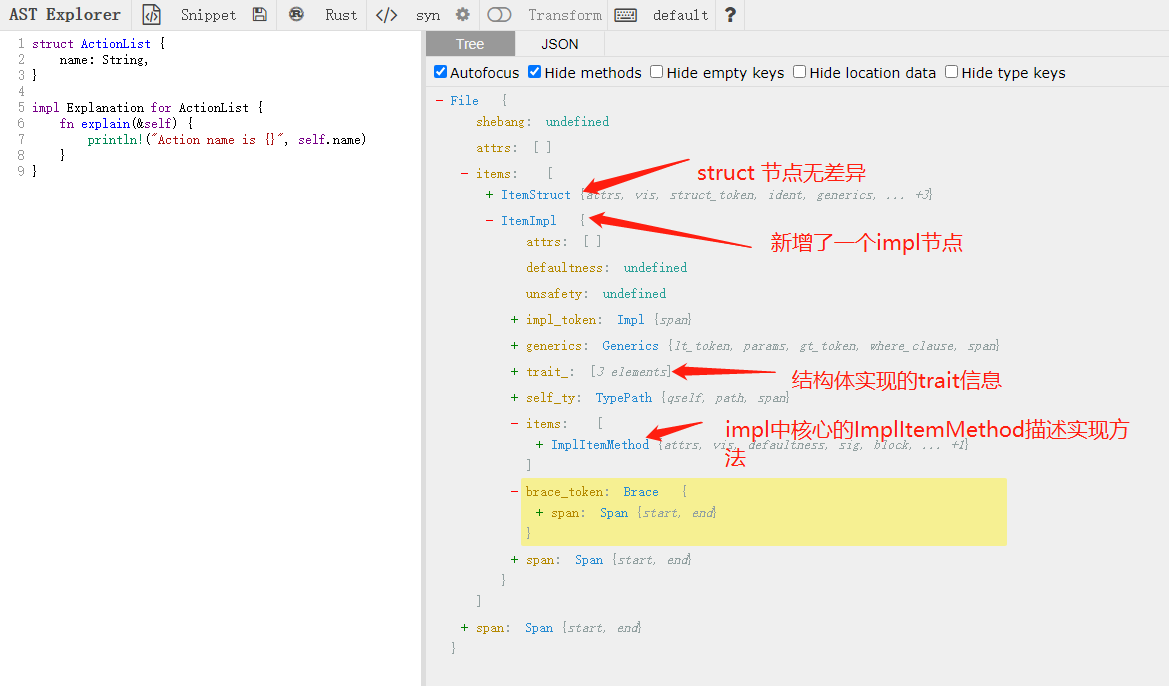
对比发现,整体上多了一个impl节点,其中描述了结构体所实现trait信息和方法信息。
第三,对结构体增加derive宏标注后的AST:
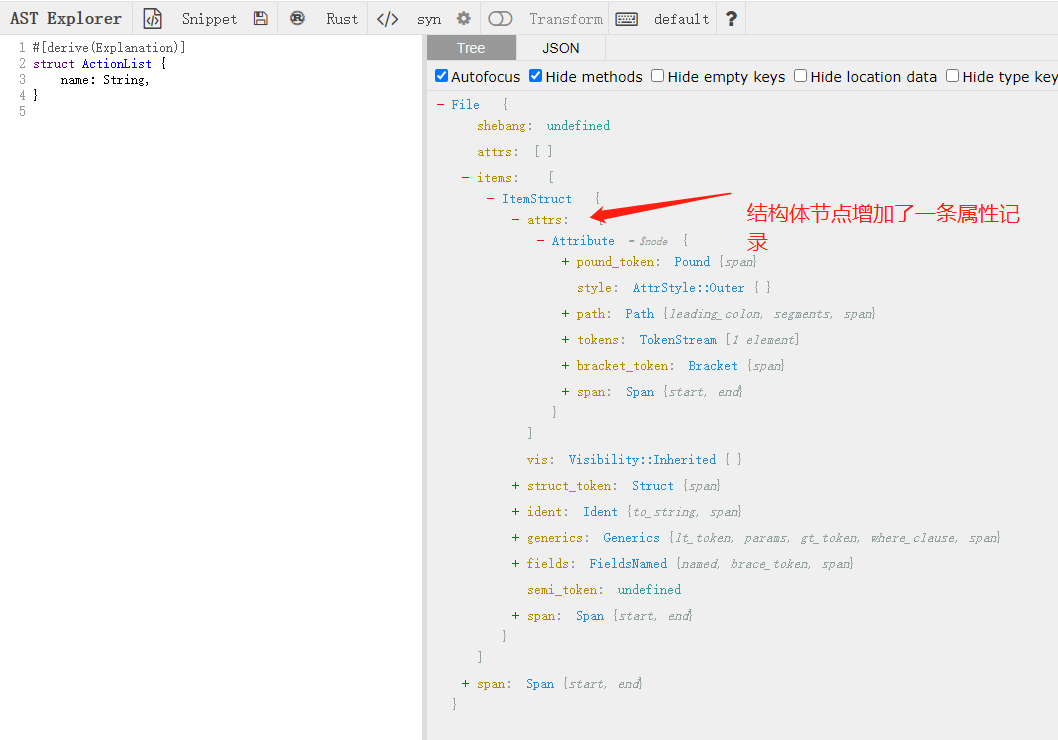
增加derive宏标注后,结构体的AST增加了一条属性记录,该记录标明该结构体存在一个derive宏声明!
此时,对比derive宏实现代码,可以明确结构体的AST与derive实现中操作对象的对应关系:
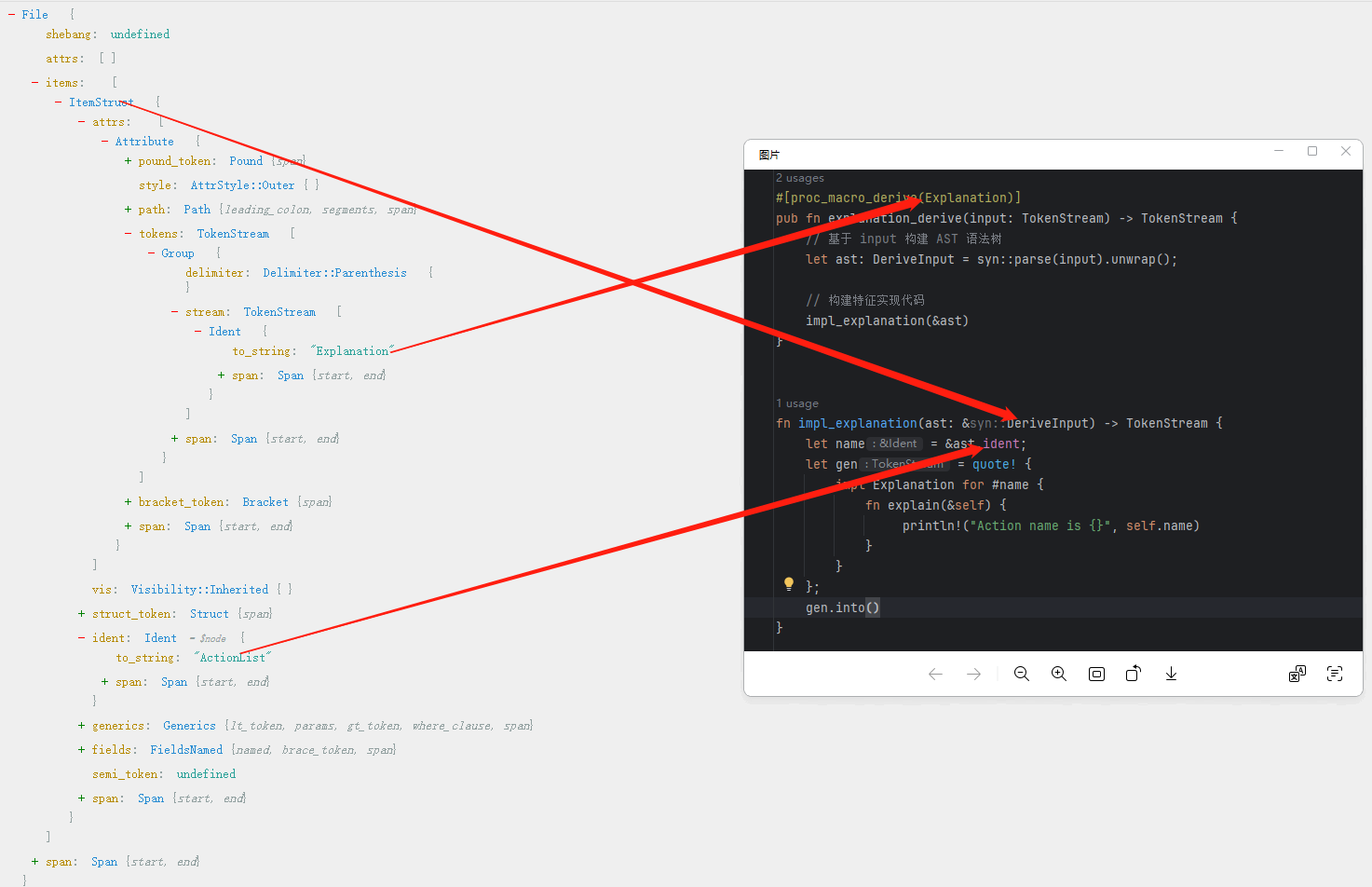
注意:impl_explanation函数,只是用了输入ast(对应ActionList的AST)ident获取结构体名称;并通过quote!生成了一个基于源代码的impl块的全新TokenStream,并将该TokenStream返回;rust编译器会处理该返回的TokenStream,与结构体的TokenStream进行整合,从而实现结构体的TokenStream与impl块的TokenStream进行合并,达到效果与在源码中对结构体编写trait impl效果一致(最终生成的AST一样)!
行文至此,rust的派生宏的基本编写方式以及宏展开基本原理 就算粗略地交代完毕了。其中还涉及到一些细节和使用方式(比如更多操作TokenStream的接口和方法)就留给感兴趣的读者自己去探索了。也欢迎大家将探索的成功发表到评论区,与大家分享、探讨......
另外,过程宏的另外两种类型:属性宏、函数宏的实现方式与派生宏基本一致,就简要介绍了!
类属性宏(Atrribute-like macros)
类属性过程宏跟 derive 宏类似,但是前者允许我们定义自己的属性。除此之外,derive 只能用于结构体和枚举,而类属性宏可以用于其它类型项,例如函数。
假设我们有个WEB服务,其中对所有相应函数,都可以应用中间件;中间件执行的过程为,在正常的调用过程之前,先调用中间件方法,以实现一些公共的操作。比如:进行JWT认证,如果认证失败就拒绝后续操作;比如敏感操作进行动作记录等。
我们预先实现一系列中间操作,在相应的函数,进行属性标注,标识启用中间件功能:
#[middleware("RecorderAction")]
fn delete_action() {
println!("done delete items....");
}
#[middleware("JWT")]
fn login() {
println!("done login....");
}如上所示,代码功能非常清晰、简洁。其表意为,对delete_action 方法,启用中间件“RecorderAction”,对login方法启用“JWT”认证!
下面演示实现:cargo new dmwebcd dmwebcargo new middleware_macro --lib
完成后,dmweb 目录结构如下:
同派生宏一样,middleware_macro包需要声明对syn,quote的依赖(dmweb/middleware_macro/src/lib.rs 内容):
[package]
name = "middleware_macro"
version = "0.1.0"
edition = "2021"
[dependencies]
syn = { version="1.0" , features = ["full"]}
quote = "1.0"
proc-macro2 = "1.0"
[lib]
proc-macro = true
#[proc_macro_attribute]
pub fn route(attr: TokenStream, item: TokenStream) -> TokenStream {注意:syn需要添加fullfeature 支持,以变获取函数信息。
middleware_macro/src/lib.rs 内容:
use proc_macro::TokenStream;
use quote::quote;
use syn::{parse_macro_input, ItemFn};
#[proc_macro_attribute]
pub fn middleware(args: TokenStream, input: TokenStream) -> TokenStream {
// 解析属性参数
let middleware_name = args.to_string();
// 解析输入的函数
let mut input_fn = parse_macro_input!(input as ItemFn);
let fn_block = &mut input_fn.block;
// 构造 middleware 函数调用的代码
let middleware_call = quote! {
middleware_run(#middleware_name);
};
// 在函数体前插入 middleware 函数调用
fn_block.stmts.insert(0, syn::parse2::<syn::Stmt>(middleware_call).unwrap());
// 返回修改后的函数
TokenStream::from(quote! {
#input_fn
})
}
与derive宏不同,类属性宏的定义函数有两个参数:
- 第一个参数时用于说明属性包含的内容:
"RecorderAction"部分 - 第二个是属性所标注的类型项,在这里是
fn delete_action() {...},注意,函数体也被包含其中
除此之外,类属性宏跟 derive 宏的工作方式并无区别:创建一个包,类型是 proc-macro,接着实现一个函数用于生成想要的代码。
main.rs内容
use middleware_macro::middleware;
// 中间件执行函数
fn middleware_run(md_name: &str) {
println!("Middleware run: {}", md_name);
}
#[middleware("RecorderAction")]
fn delete_action() {
println!("done delete items....");
}
#[middleware("JWT")]
fn login() {
println!("done login....");
}
fn main() {
delete_action();
login();
}
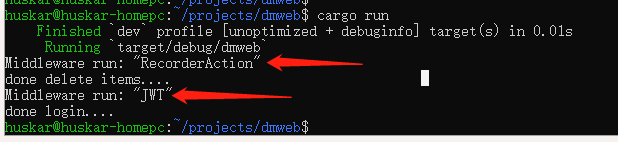
这里,我们简化middleware_run,模拟中间件派发(简单的打印派发对象),运行效果:
类函数宏(Function-like marcos)
类函数宏可以让我们定义像函数那样调用的宏,从这个角度来看,它跟声明宏 macro_rules 较为类似。
区别在于,macro_rules 的定义形式与 match 匹配非常相像,而类函数宏的定义形式则类似于之前讲过的两种过程宏:
#[proc_macro]
pub fn sql(input: TokenStream) -> TokenStream {而使用形式则类似于函数调用:
let sql = sql!(SELECT * FROM posts WHERE id=1);大家可能会好奇,为何我们不使用声明宏macro_rules来定义呢?原因是这里需要对SQL语句进行解析并检查其正确性,这个复杂的过程是macro_rules难以对付的,而过程宏相比起来就会灵活的多。
类函数宏的示例demo就留给大家当作业了
