


llama2-70b模型spike问题验证
1.方法调研
1.1 loss spike
loss spike指的是预训练过程中,尤其容易在大模型(100B以上)预训练过程中出现的loss突然暴涨的情况。
1.2 Adam优化器导致尖刺问题出现
在理论层面上,本文对随机事件的叠加进入单峰的正态分布的必要条件进行了研究和解释。可以通过道尔顿板实验来更好地理解这一点。文章指出,要满足这一条件,各个随机事件之间应该是相互独立的。然而,梯度变化和参数更新的变化并不能很好地满足独立性条件。事实上,这正是导致参数更新振荡、出现loss spike以及loss不收敛的重要原因之一。在训练过程中,loss spike的出现与梯度更新幅度、ε的大小以及批处理大小这三个条件密切相关。
1.3 论文结论
浅层网络的梯度更新幅度和ε的大小与loss spike的出现密切相关,而与batch大小的相关性问题则不太明显。实际上,当浅层网络的参数突然进入之前长时间未达到的状态时,与当前深层参数的状态相互作用会导致连锁反应,使得模型进入非稳态。通常情况下,即使出现loss spike,模型也会自动恢复到正常状态,但也有可能永远无法恢复。
2.进行实验
128机,1024卡完成复现以及问题解决。
2.1 系统配置
- 机器:昇腾910B
- cann版本:7.0.1
- torch版本:2.1.0
- python版本:3.8
- driver版本:23.0.1
2.2 训练参数配置
AdamW参数设置
|
实验组数 |
LR |
beta1 |
beta2 |
eps |
|
论文参数 |
1.5e-4 |
0.9 |
0.95 |
1e-5 |
|
lossspike复现参数 |
1.5e-4 |
0.9 |
0.999 |
1e-8 |
2.3数据集使用
选取部分Wanjuan的EN数据集,转换后共144G
2.4 论文参数结果(未发现尖刺)
完整训练参数:
----------------------- arguments ------------------------
accumulate_allreduce_grads_in_fp32 .............. True
adam_beta1 ...................................... 0.9
adam_beta2 ...................................... 0.95
adam_eps ........................................ 1e-05
add_bias_linear ................................. False
add_gate ........................................ True
adlr_autoresume ................................. False
adlr_autoresume_interval ........................ 1000
aml_data_download_path .......................... None
apply_layernorm_1p .............................. False
apply_query_key_layer_scaling ................... False
apply_residual_connection_post_layernorm ........ False
async_tensor_model_parallel_allreduce ........... False
attention_dropout ............................... 0.0
attention_softmax_in_fp32 ....................... True
auto_recompute_device_size ...................... -1
auto_recompute_profiling_step ................... 10
barrier_with_L1_time ............................ True
bert_binary_head ................................ True
bert_load ....................................... None
bf16 ............................................ True
bias_dropout_fusion ............................. True
bias_gelu_fusion ................................ False
biencoder_projection_dim ........................ 0
biencoder_shared_query_context_model ............ False
block_data_path ................................. None
checkpoint_activations .......................... False
checkpoint_block_layer .......................... 25
checkpoint_in_cpu ............................... False
checkpoint_num_layers ........................... 1使用论文参数进行训练,进行到1543个step,训练因为hccl通信问题出现中断,其中的loss曲线如图所示:
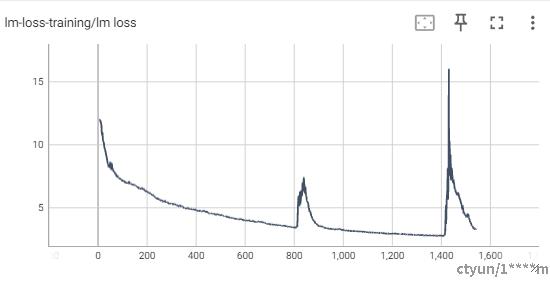
可以看到出现两个较为明显的尖刺。
梯度曲线如图所示:
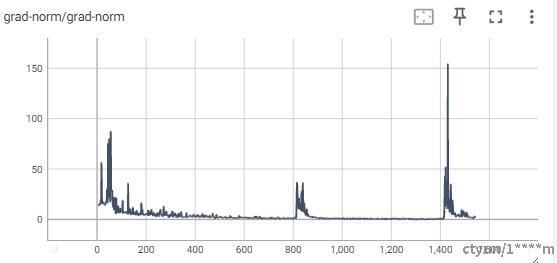
总结分析
根据实验复现了相应的结果并进行了解决。
- 现阶段进行的训练如果出现尖刺后loss恢复正常,那么对模型最终结果不会产生较大影响。
- 修改AdamW优化器参数,单独降低eps,或者适当调整eps以及减小beta2参数,会避免产生loss spike。
- 其他解决方法还包括:
- PaLM和GLM130B提到的出现loss spike后更换batch样本的方法(常规方法,但是成本比较高)
- 减小learning rate,这是个治标不治本的办法,对更新参数的非稳态没有做改进。
- GLM130B采取的是把浅层梯度直接乘以缩放系数 alph来减小浅层梯度更新值。
