


1 DeepSpeed-Chat
概述
DeepSpeed-Chat是微软最新公布的一套工具,用于训练类ChatGPT模型。该工具基于微软的大模型训练工具DeepSpeed,使用它可以非常简单高效地训练自己的ChatGPT。该工具具有以下特点:
- 完整的训练类ChatGPT的代码:包括预训练模型下载、数据下载、InstructGPT训练过程和测试。
- 多种规模的模型:模型参数从1.3B到66B,即适合新手学习也可用于商用部署。
- 高效的训练:通过使用最新技术,如ZeRO和LoRA等技术改善训练过程,让训练过程更高效。例如,一个67亿(6.7B)参数的模型,使用8块A00只需要约5个小时就可以完成训练。
- 推理API:提供易于使用的推理API,方便进行对话式的交互测试。
框架优势
- 高效性和经济性:DeepSpeed-HE 比现有系统快 15 倍以上,使 RLHF 训练快速且经济实惠。例如,DeepSpeed-HE 在 Azure 云上只需 9 小时即可训练一个 OPT-13B模型,只需 18 小时即可训练一个 OPT-30B模型。这两种训练分别花费不到 300 美元和 600 美元。
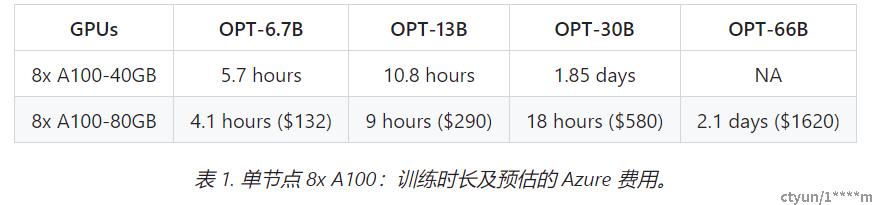
- 卓越的扩展性:DeepSpeed-HE 能够支持训练拥有数千亿参数的模型,并在多节点多 GPU 系统上展现出卓越的扩展性。因此,即使是一个拥有 130 亿参数的模型,也只需 1.25 小时就能完成训练。而对于庞大的 拥有1750 亿参数的模型,使用 DeepSpeed-HE 进行训练也只需不到一天的时间。

非常重要的细节: 上述两个表格(即表一和表二)中的数据均针对 RLHF 训练的第 3 步,基于实际数据集和 DeepSpeed-RLHF 训练吞吐量的测试。该训练在总共 1.35 亿(135M)个字符(token)上进行一个时期(epoch)的训练。我们总共有 6750 万个查询(query)字符(131.9k 个 query,每个序列长度为 256)和 6750 万个生成/回答字符(131.9k 个答案,每个序列长度为 256),每步的最大全局字符批量大小约为 500 万个字符(1024 个查询-答案对)。- 实现 RLHF 训练的普及化:仅凭单个 GPU,DeepSpeed-HE 就能支持训练超过 130 亿参数的模型。这使得那些无法使用多 GPU 系统的数据科学家和研究者不仅能够轻松创建轻量级的 RLHF 模型,还能创建大型且功能强大的模型,以应对不同的使用场景。
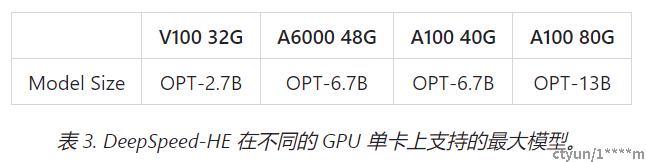
完整流程图
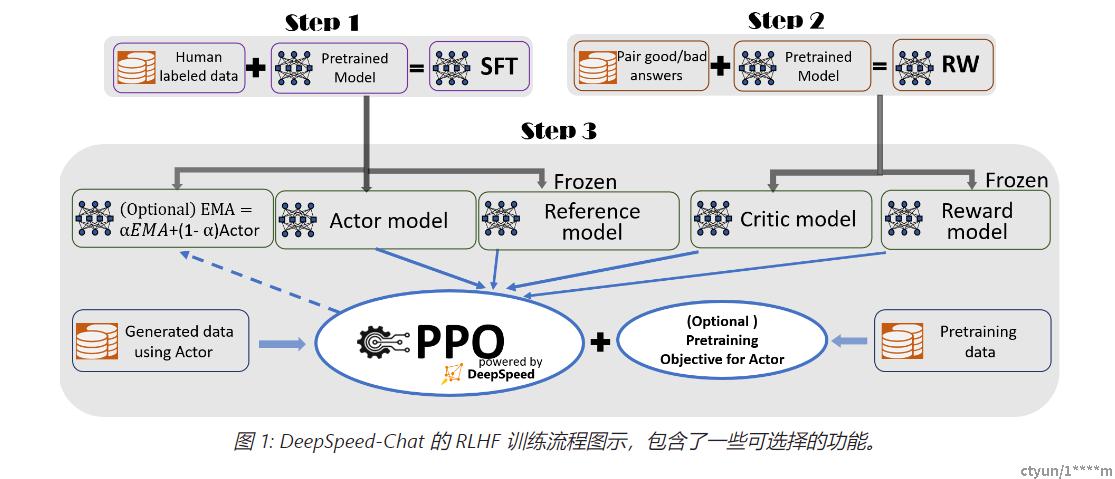
2 开发环境安装
机器准备:
- 使用一台4卡v100机器,linux操作系统,显存32G,CUDA版本11.7
环境配置
- 新建conda环境
创建新的conde环境来运行DS-Chat。
conda create -n Test01 python=3.10
conda activate Test01
# 将conda环境加入PATH和LD_LIBRARY_PATH中,从而可以优先利用conda安装的程序
export LD_LIBRARY_PATH=/data/chenshuo/anaconda3/envs/Test01/lib/:$LD_LIBRARY_PATH
export PATH=/data/chenshuo/anaconda3/envs/Test01/bin:$PATH- 安装pytorch-gpu
conda install pytorch torchvision torchaudio pytorch-cuda=11.7 -c pytorch -c nvidia- 检查命令
python
>>> import torch
>>> torch.cuda.is_available()
True
>>> torch.cuda.device_count()
4
>>> torch.cuda.current_device()
0
>>> torch.cuda.device(0)
<torch.cuda.device object at 0x7fc9336c2c80>
>>> torch.cuda.get_device_name(0)
'Tesla V100-PCIE-32GB'
```
- 下载DeepSpeedExamples的代码
```
git clone https://github.com/microsoft/DeepSpeedExamples.git
cd DeepSpeedExamples/applications/DeepSpeed-Chat/
# 安装依赖
pip install --index-url https://pypi.douban.com/simple -r requirements.txt#注释其中的torch
#其中的transformers安装包可以换成国内的gitee的镜像,在requirements.txt的第7行
git+https://gitee.com/michael7736_admin/transformers.git docker环境配置
- 拉取docker镜像
docker pull deepspeed/deepspeed:v072_torch112_cu117- 按照上述安装安装依赖包,其他环境docker中已经配置完成。
3 ChatGPT模型训练的基本流程
ChatGPT 的训练过程共分为四个步骤:
- a) 训练预训练模型,如 GPT-3.5 或 GPT-4;
- b) 监督微调(SFT:supervised finetuning)(对应 DS-Chat 中的 Step1);
- c) 奖励模型微调(RM:Reward model finetuning)(对应 DS-Chat 中的 Step2);
- d) 基于人类反馈的强化学习(RLHF:Reinforcement learning with human feedback)(对应 DS-Chat 中的 Step3)。
其中,阶段(a)的 GPT-3.5 或 GPT-4 预训练部分是计算量最大的阶段。这不仅需要大量的 GPU(几十到数百个),而且训练时间非常长(数月),因此通常只有大型企业才能进行训练。在本实例中,我们使用了 Facebook 公开的 opt 系列预训练模型,并主要针对 b、c、d 三个步骤进行训练。这三个步骤分别对应案例中的 Step 1、2、3。
4 代码以及训练基本流程
其中代码主要位于applications/DeepSpeed-Chat下面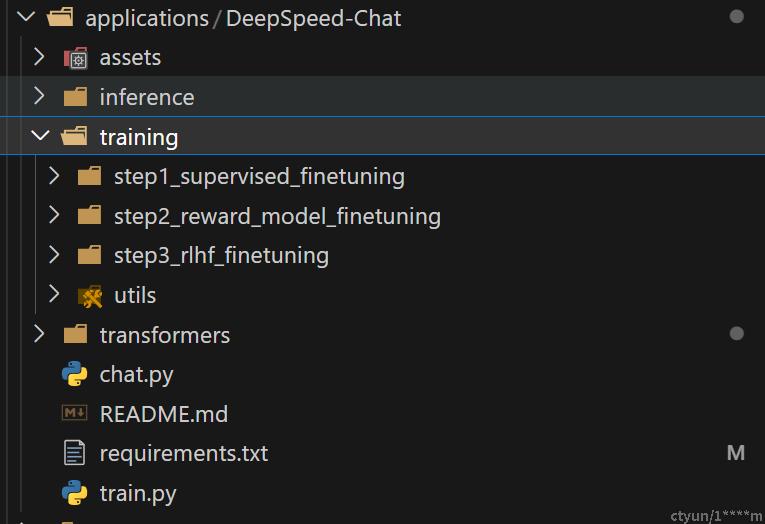
模型训练以及调用过程
- 入口程序: train.py
- 主要参数
--step 1 2 3
--deployment-type single_gpu single_node multi_node 不同的type主要是参数的设置不同
--actor-model: "1.3b", "6.7b", "13b", "66b" 预训练模型,默认是1.3b的模型
--reward-model:使用的是 350m 的模型
其他参数,可以去参考train.py中的说明
- 主要参数
- 配置脚本:training/step1_supervised_finetuning/training_scripts/single_node/run_1.3b.sh
train.py 程序会调用 run_1.3b.sh 来执行模型训练
un_1.3b.sh 中可以设置参数,并调用对应的 main.py 来开始模型训练
-
训练程序:training/step1_supervised_finetuning/main.py
核心训练脚本,主要功能如下:- 数据,模型的下载
- 模型的训练
-
评价与测试用程序:prompt_eval.py
用于测试训练后的模型,并提供了微调前后的对比。
Facebook opt系列模型
本实例中使用的预训练模型是 facebook opt系列模型,根据OPT论文介绍,OPT-175B模型与GPT-3有类似的性能。
OPT:Open Pre-trained Transformer Language Models
论文地址:https://arxiv.org/abs/2205.01068
模型在Huggingface上的地址:
https://huggingface.co/facebook/opt-125m
https://huggingface.co/facebook/opt-350m
https://huggingface.co/facebook/opt-1.3b
https://huggingface.co/facebook/opt-6.7b
https://huggingface.co/facebook/opt-13b
https://huggingface.co/facebook/opt-30b
https://huggingface.co/facebook/opt-66b
如果要使用最大的175B的模型,需要申请,获得授权后才能使用。
申请地址:https://forms.gle/dag8g7nKiR4o4VZq5
5 Step1:监督微调
任务说明:
第一阶段:监督微调(SFT,Supervised FineTune) —— 使用精选的人类回答来微调预训练的语言模型以应对各种查询(query)。有监督微调 (SFT) 非常类似于针对因果语言任务(例如:WikiText-103)的标准语言模型微调。 主要区别在于数据集资源,SFT 用高质量的查询-答案对来微调模型以实现人类偏好的生成。
数据和模型准备
由于服务器无法访问外网,因此需要本地下载数据集和模型。
下载地址在:https://huggingface.co/
- 数据集下载:
可以选择使用git的方式下载,同样可以使用离线下载在保存至百度云盘,在服务器上使用bypy在云盘进行下载。推荐使用云盘下载方式。
下面是使用到的数据集。
Dahoas/rm-static # 对话(prompt,response,chosen,rejected)
Dahoas/full-hh-rlhf # 对话(prompt,response,chosen,rejected)
Dahoas/synthetic-instruct-gptj-pairwise #对话(prompt,chosen,rejected)
yitingxie/rlhf-reward-datasets # 对话(prompt,chosen,rejected)
openai/webgpt_comparisons # 带人工打分的数据,comparisons with human feedback,19,578 comparisons)
stanfordnlp/SHP # 18个领域的385k 人类标注数据- 数据详细示例
Dahoas/rm-static数据集格式: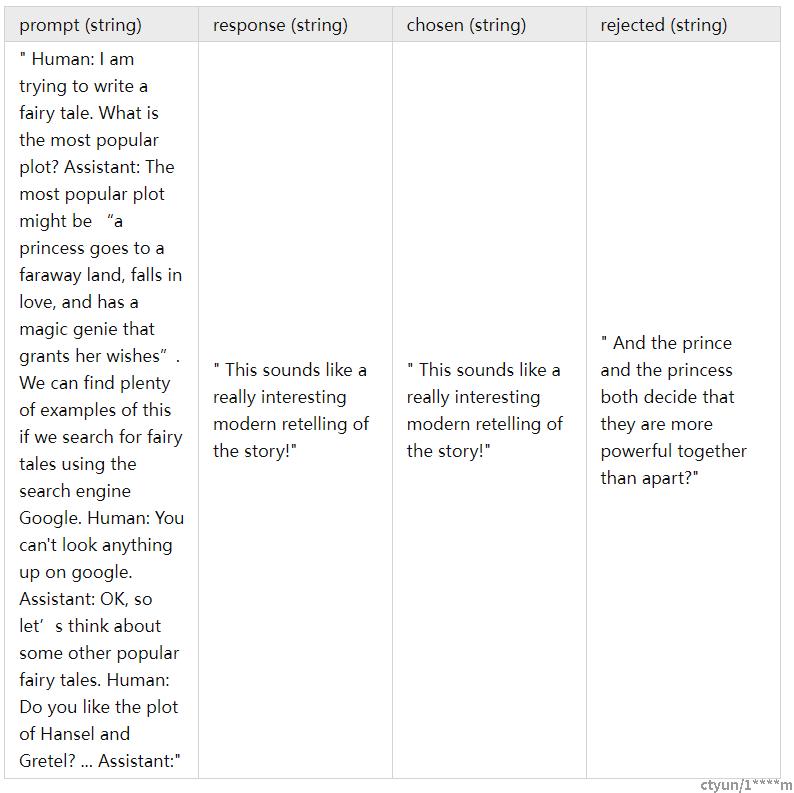
- 数据集加载代码修改
修改training/utils/data/raw_datasets.py文件,将数据集改为本地加载。以Dahoas_rm_static为例:
class PromptRawDataset(object):
def __init__(self, output_path, seed, local_rank, dataset_name):
self.output_path = output_path
self.seed = seed
self.local_rank = local_rank
if not ("Dahoas/rm-static" == dataset_name or "Dahoas/full-hh-rlhf" == dataset_name or "Dahoas/synthetic-instruct-gptj-pairwise" == dataset_name or "yitingxie/rlhf-reward-datasets" == dataset_name):
self.raw_datasets = load_dataset(dataset_name)
# English dataset
class DahoasRmstaticDataset(PromptRawDataset):
def __init__(self, output_path, seed, local_rank, dataset_name):
super().__init__(output_path, seed, local_rank, dataset_name)
self.dataset_name = "Dahoas/rm-static"
self.dataset_name_clean = "Dahoas_rm_static"
data_files = {"train":"train-00000-of-00001-2a1df75c6bce91ab.parquet","test":"test-00000-of-00001-8c7c51afc6d45980.parquet"}
self.raw_datasets = load_dataset("parquet", data_dir='/workspace/applications/DeepSpeed-Chat/training/Dahoas/rm-static/data', data_files=data_files)
def get_train_data(self):
return self.raw_datasets["train"]
def get_eval_data(self):
return self.raw_datasets["test"]
def get_prompt(self, sample):
return sample['prompt']
def get_chosen(self, sample):
return sample['chosen']
def get_rejected(self, sample):
return sample['rejected']
def get_prompt_and_chosen(self, sample):
return sample['prompt'] + sample['chosen']
def get_prompt_and_rejected(self, sample):
return sample['prompt'] + sample['rejected']- 模型下载
模型下载:代码会自动的下载对应的模型,默认情况下模型被存放在
~/.cache/huggingface/hub/models--facebook--opt-1.3b,本地加载可以在training/step1_supervised_finetuning/training_scripts/single_gpu/run_1.3b.sh中修改--model_name_or_path /workspace/applications/DeepSpeed-Chat/training/facebook/opt-1.3b来修改预训练模型的存放位置。
启动训练:
- 执行命令
通过执行下面的命令,就可以开启模型的训练。
python3 train.py --step 1 --deployment-type single_gpu #单GPU训练
python3 train.py --step 1 --deployment-type single_node #多GPU训练
python3 train.py --step 1 --deployment-type multi_node #多Node训练在上述三种方式中,single_gpu 只适合训练较小的模型,而 single_node 和 multi_node 更适合训练较大的模型。第一次运行时,建议使用 single_gpu,因为在这种模式下,输出的错误信息会更详细。如果遇到 GPU 内存不足的问题,可以尝试使用 single_node 和 multi_node 来训练。如果问题仍然存在,需要手动调整 batch-size。输出的log信息会保存在applications/DeepSpeed-Chat/output/actor-models/1.3b/training.log处。
- 训练详情
使用promt和chosen的数据拼接后对模型进行SFT训练。单gpu监督微调1.3b模型的内存占用情况: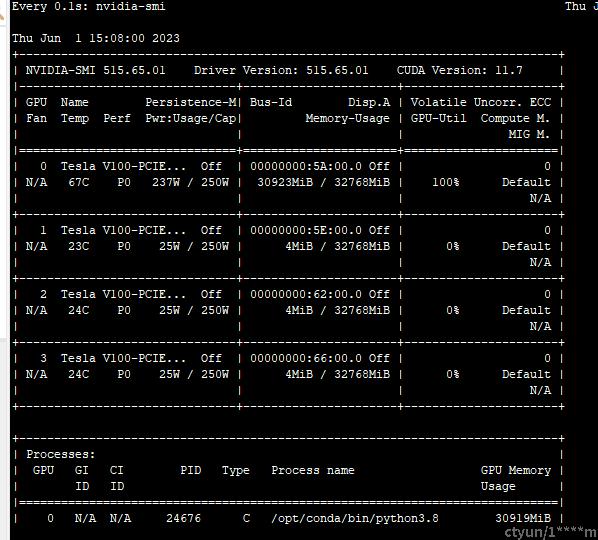
使用Dahoas/rm-static数据集单GPU需要56分钟完成训练
模型训练完成之后会被存储在 output/actor-models/1.3b 下面。你可以通过 training.log 文件来查看训练的进度。 - 评价与测试:
打开文件 run_prompt.sh 添加 baseline 模型,和 finetune 后的模型:
export CUDA_VISIBLE_DEVICES=0
python prompt_eval.py \
--model_name_or_path_baseline facebook/opt-1.3b \
--model_name_or_path_finetune ../../output/actor-models/1.3b评价程序会调用 prompt_eval.py 来分别输出 baseline 和 finetune 后模型的结果。要执行此代码,需要切换到 step1_supervised_finetuning 目录下。
cd training/step1_supervised_finetuning
bash evaluation_scripts/run_prompt.sh- 出现问题,评价过程, 出现模型参数不匹配问题:
model.decoder.embed_tokens.weight: found shape torch.Size([50272, 2048]) in the checkpoint and torch.Size([50265, 2048]) in the model 原因是由于模型被finetune以后,Token对应的词典数量发生了变化,导致输入数据维度变化了(这应该是个bug,在输入端应尽量保持与预训练模型一致)。应对方法,打开文件 prompt_eval.py,增加新的 config 读取脚本,并把来源模型从 baseline 模型中修改为finerune后的模型:
config = AutoConfig.from_pretrained(args.model_name_or_path_finetune) # 新增
model_fintuned = get_model(config, args.model_name_or_path_finetune, tokenizer)- 测试结果
Step2 :奖励模型微调
任务介绍
奖励模型 (RM) 微调类似于第一阶段有监督微调 (SFT) 。 但是,RM 和 SFT 微调之间存在几个关键差异:
- 训练数据差异:对于 SFT 微调,数据是查询(query)和答案(answer)拼接在一起。 然而,对于 RM 微调,每批数据由两个查询-答案对组成,即具有高分答案和低分答案的相同查询。 这也导致了如下所述的第二个差异。
- 训练目标差异: 对于 RW,训练目标是 pairwise ranking score,即对于两个查询-答案对,RM 应该给更好的答案更高的分数。 有多种方法可以实现这一目标。 在DeepSpeed Chat的实现中,使用序列的结束标记或第一个填充标记作为聚合分数并比较它们。 当然,也可以使用整个答案的平均分数作为替代。
- --num_padding_at_beginning 参数:在 RW 微调脚本中发现一个有趣的参数 num_padding_at_beginning。 添加此参数是因为注意到不同的模型可能具有不同的填充或分词器行为。 具体来说,OPT 模型族中的 tokenizer 总是在开头添加一个 padding token,这会影响我们对评分 token 的选择。 因此,我们需要考虑到这一点。
- RW 评估:提供了一个评估脚本 rw_eval.py,供用户执行简单的提示回答测试。
这里我使用单机多卡基于opt-350m进行奖励模型的微调。当然,你也可以通过简单地将候选模型替换为您喜欢的模型并启用其他高效训练方法来训练更大的模型,如:SFT 微调过程中所述方法。
启动训练
启动方法类似:
python3 train.py --step 2 --deployment-type single_gpu #单GPU训练
python3 train.py --step 2 --deployment-type single_node #多GPU训练
python3 train.py --step 2 --deployment-type multi_node #多Node训练训练数据:
- 单GPU训练时只使用了 Dahoas/rm-static 数据
- 多GPU训练使用了更多的数据:
Dahoas/rm-static
Dahoas/full-hh-rlhf
Dahoas/synthetic-instruct-gptj-pairwise
yitingxie/rlhf-reward-datasets
openai/webgpt_comparisons
stanfordnlp/SHP训练过程
单卡,batch-size=16,内存的占用情况。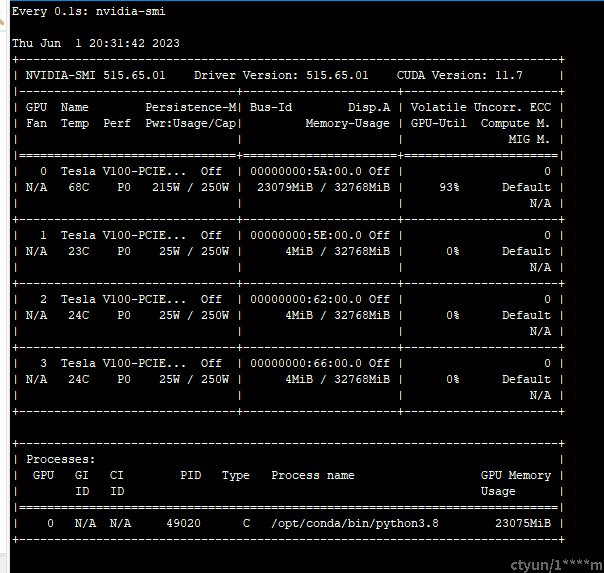
单卡13分钟完成训练。
模型评估

Step3 : RLHF训练
任务介绍
RLHF (Reinforcement Learning from Human Feedback) ,即以强化学习方式依据人类反馈优化语言模型。用生成文本的人工反馈作为性能衡量标准,或者更进一步用该反馈作为损失来优化模型,RLHF 的思想:使用强化学习的方式直接优化带有人类反馈的语言模型。RLHF 使得在一般文本数据语料库上训练的语言模型能和复杂的人类价值观对齐。
同时使用多个模型的内存消耗问题:此步训练不仅使用被训练的主模型,还使用奖励模型进行评分,因此会占用更多的 GPU 内存。
如何有效地生成答案:在 RLHF 训练过程中,需要生成多个备选答案。由于模型一次推理只能生成一个答案,因此需要进行多次模型推理,这种操作会大幅度增加训练时间。
启动训练:
前面两步已经有了微调的actor模型和reward模型的checkpoint,下面您只需运行以下脚本即可启用 PPO 训练。
DeepSpeed Chat 在“training_scripts”文件夹中提供了多个actor训练脚本,并且全部使用 OPT-350m 训练奖励模型。 但是,你可以根据自己的喜好尝试不同的奖励模型大小。
python3 train.py --step 3 --deployment-type single_gpu #单GPU训练
python3 train.py --step 3 --deployment-type single_node #多GPU训练
python3 train.py --step 3 --deployment-type multi_node #多Node训练此步训练后的模型被存储在 output/step3-models/1.3b/ 下。
训练情况
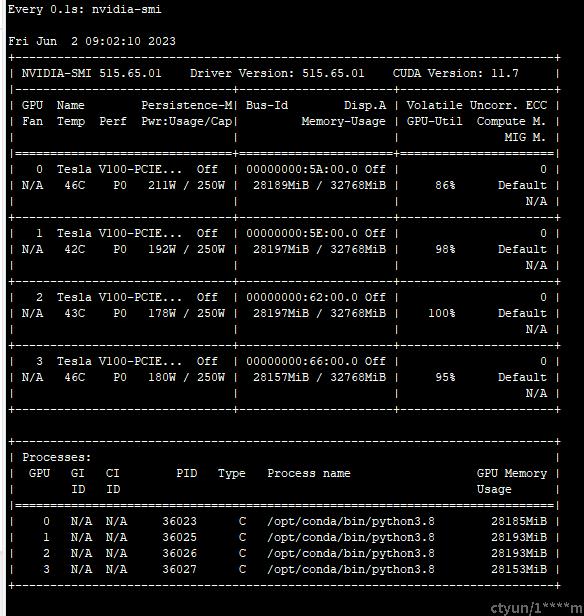
一键式RLHF训练
DeepSpeed Chat提供了一个脚本即可完成 RLHF 训练的所有三个步骤并生成您的 类ChatGPT 模型。
python train.py --actor-model facebook/opt-1.3b --reward-model facebook/opt-350m --deployment-type single_gpu评价与测试
使用 chat.py 命令(需要移动到 DeepSpeed-Chat 目录下)进行评价与测试。 执行方式如下:
python chat.py --path output/step3-models/1.3b/actor- 运行过程
参考文献
[1] https://github.com/microsoft/DeepSpeedExamples
[2] https://github.com/microsoft/DeepSpeed/tree/master/blogs/deepspeed-chat/chinese
[3] OPT论文: https://arxiv.org/abs/2205.01068
[4] https://techdiylife.github.io/big-model-training/deepspeed/deepspeed-chat.html
[5] https://zhuanlan.zhihu.com/p/626214655
