


论文:
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
代码:
一、Swin Transformer的简要介绍
Swin Transformer 的设计灵感来自于 ViT(Vision Transformer),但是 Swin Transformer 通过引入新的特性来解决 ViT 的一些问题。具体来说,Swin Transformer 采用了分层的窗口机制,以及跨阶段的特征重用,从而减少了模型的计算和内存需求。此外,Swin Transformer 还使用了一种新的路径设计,以便更好地支持多尺度输入和输出。
Swin Transformer 的窗口机制是其最显著的特点之一。与 ViT 中的固定大小的图像块不同,Swin Transformer 可以使用可变大小的窗口,以捕获不同尺度的特征。具体来说,Swin Transformer 将输入图像分成若干个块,每个块都是一个小窗口,可以在不同的阶段进行处理。这种分层的窗口机制可以减少模型中每个位置的参数数量,并使模型更加高效。
Swin Transformer 还使用了一种跨阶段的特征重用机制,以减少计算和内存开销。具体来说,Swin Transformer 将每个块分配给不同的阶段进行处理,并将每个阶段的输出与后续阶段共享。这种跨阶段的特征重用机制可以减少计算和内存需求,从而使模型更加高效。
最后,Swin Transformer 还使用了一种新的路径设计,以更好地支持多尺度输入和输出。具体来说,Swin Transformer 使用了多个路径来处理不同尺度的特征,并通过跨阶段的特征重用来整合这些路径。这种路径设计可以使模型更加高效,并在多尺度图像分类任务中取得更好的性能。
总之,Swin Transformer 是一种新的图像分类模型,具有高准确性和更小的计算和内存开销。它的窗口机制、跨阶段的特征重用机制和新的路径设计是其最重要的特点。Swin Transformer 已经在 ImageNet 数据集上取得了最先进的性能,并已成为计算机视觉领域的研究热点之一。
二、Swin Transformer 的整体架构
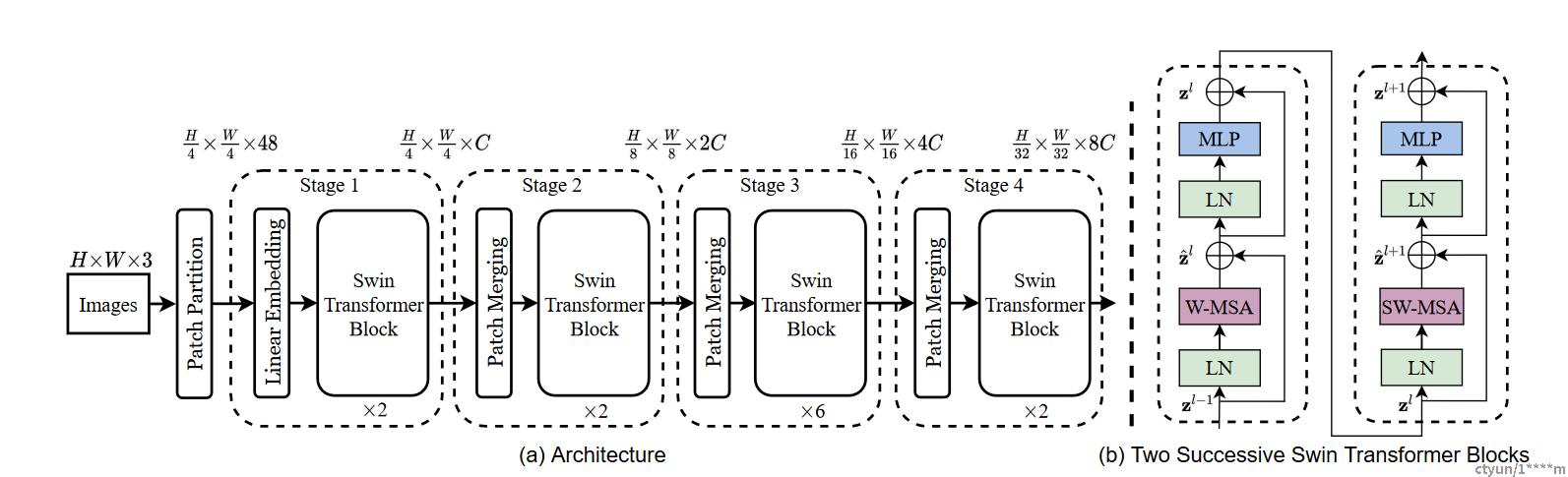
Swin Transformer 的整体架构采用了基于 Transformer 的架构,具有更小的计算和内存需求,同时在 ImageNet 数据集上取得了最先进的性能。下面介绍 Swin Transformer 的整体架构。
1、分层的特征提取器
Swin Transformer 的特征提取器采用了分层的设计,它将输入图像分成若干个分辨率层次,并在每个层次上使用可变大小的窗口。具体来说,Swin Transformer 将输入图像分成了多个分辨率层次,每个层次都有一个固定的大小,然后在每个层次上使用可变大小的窗口。这个分层的特征提取器可以减少模型中每个位置的参数数量,并使模型更加高效。
2、跨层的特征重用
Swin Transformer 的特征重用机制采用了跨层的设计,它将每个块分配给不同的阶段进行处理,并将每个阶段的输出与后续阶段共享。具体来说,Swin Transformer 将每个块分配给不同的阶段进行处理,并将每个阶段的输出与后续阶段共享。这种跨层的特征重用机制可以减少计算和内存需求,从而使模型更加高效。
3、全局池化和分类器
Swin Transformer 的全局池化和分类器采用了传统的方法,即将每个通道的特征进行平均池化,并将结果输入到一个全连接层中进行分类。具体来说,Swin Transformer 使用了全局平均池化来将每个通道的特征进行汇总,并将结果输入到一个全连接层中进行分类。
总之,Swin Transformer 的整体架构采用了基于 Transformer 的架构,具有更小的计算和内存需求,同时在 ImageNet 数据集上取得了最先进的性能。它的分层的特征提取器、跨层的特征重用机制和传统的全局池化和分类器是其最重要的特点。Swin Transformer 已成为计算机视觉领域的重要研究方向,并在目标检测、图像分类、语义分割等任务中取得了优秀的性能。
三、Swin Transformer 的窗口机制
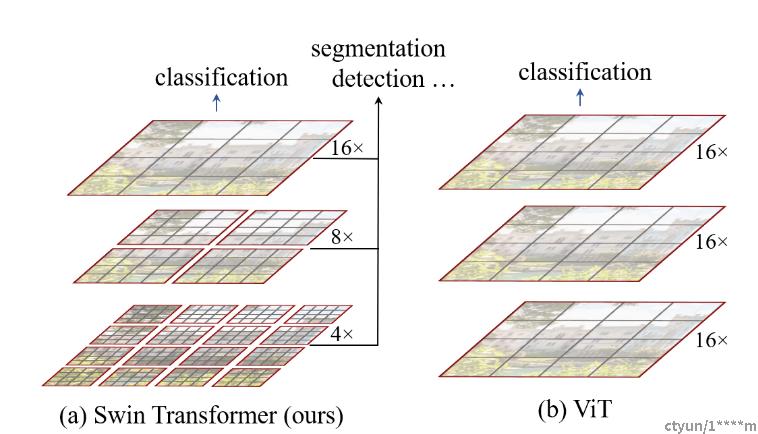
Swin Transformer 的窗口机制是其最重要的特点之一,它允许模型使用可变大小的窗口来捕获不同尺度的特征。与传统的卷积神经网络不同,Swin Transformer 使用了基于 Transformer 的架构,并将输入图像分成若干个块,每个块都是一个小窗口,可以在不同的阶段进行处理。下面详细介绍 Swin Transformer 的窗口机制。
-
窗口分块
Swin Transformer 将输入图像分成若干个块,每个块都是一个小窗口,可以在不同的阶段进行处理。具体来说,Swin Transformer 将输入图像分成了多个分辨率层次,每个层次都有一个固定的大小,然后在每个层次上使用可变大小的窗口。这种分层的窗口设计可以减少模型中每个位置的参数数量,并使模型更加高效。
-
窗口嵌套
Swin Transformer 的窗口机制采用了窗口嵌套的方式,每个窗口包含多个位置。具体来说,每个窗口都被分成了若干个小的子窗口,每个子窗口对应一个位置。这种窗口嵌套的设计可以在不同尺度上捕获特征,并可以减少模型中每个位置的参数数量。
-
窗口移位
Swin Transformer 的窗口机制采用了窗口移位的方式,使得每个位置在不同的阶段能够捕获不同的特征。具体来说,窗口在不同的阶段进行移位,使得每个位置能够捕获不同的特征。这种窗口移位的设计可以提高模型的感受野,并使模型能够处理不同尺度的特征。
总之,Swin Transformer 的窗口机制采用了窗口分块、窗口嵌套和窗口移位的方式,使得模型能够使用可变大小的窗口来捕获不同尺度的特征。这种窗口机制可以减少模型中每个位置的参数数量,并使模型更加高效。同时,窗口移位的设计可以提高模型的感受野,并使模型能够处理不同尺度的特征。
四、实验
论文构建了基础模型,称为Swin-B,具有与ViTB/DeiT-B类似的模型大小和计算复杂性。还介绍了Swin-T、Swin-S和Swin-L,它们分别是模型大小和计算复杂度的0.25倍、0.5倍和2倍。请注意,Swin-T和Swin-S的复杂性分别与ResNet-50(DeiT-S)和ResNet-101的复杂性相似。默认情况下,窗口大小设置为M=7。对于所有实验,每个头部的query维度为d=32,每个MLP的扩展层为α=4。这些模型变体的架构超参数为:
- Swin-T: C = 96, layer numbers = {2, 2, 6, 2}
- Swin-S: C = 96, layer numbers ={2, 2, 18, 2}
- Swin-B: C = 128, layer numbers ={2, 2, 18, 2}
- Swin-L: C = 192, layer numbers ={2, 2, 18, 2}
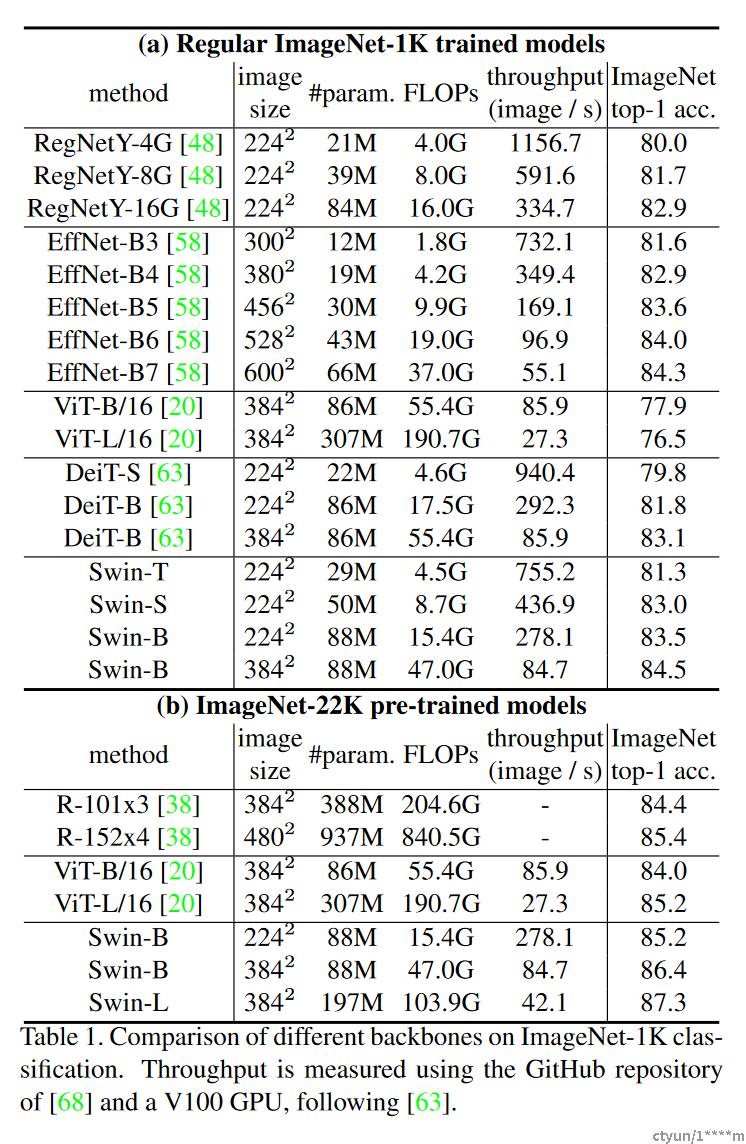
其中C是第一阶段中隐藏层的通道数。ImageNet图像分类模型变量的模型大小、理论计算复杂度(FLOPs)和吞吐量如表1所示。
论文对ImageNet-1K图像分类、COCO对象检测和ADE20K语义分割进行了实验。在下文中,论文首先将所提出的Swin Transformer架构与之前三项任务的最新技术进行比较。然后,论文消融了Swin Transformer的重要设计元素。
1、 ImageNet-1K上的图像分类
设置 对于图像分类,论文在ImageNet-1K上对提出的Swin Transformer进行了基准测试,该Transformer包含1.28M个训练图像和来自1000个类的50K个验证图像。报告了单个作物的顶级精度。论文考虑两种训练设置:
定期ImageNet-1K训练 论文使用了一个AdamW优化器,使用余弦衰减学习率调度器和20个epochs的线性预热,用于300个epochs。批量大小为1024,初始学习率为0.001,权重衰减为0.05。在训练中使用了增强和正则化策略,但重复增强和EMA除外,它们不会提高性能。
在ImageNet-22K上进行预训练,并在ImageNet-1K上进行微调 论文还对更大的ImageNet-22K数据集进行预训练,该数据集包含1420万张图像和22K类。使用线性衰减学习速率调度器和5-epoch线性预热,为90个epochs使用AdamW优化器。批量大小为4096,初始学习率为0.001,重量衰减为0.01。在ImageNet-1K微调中,训练了30个epochs的模型,批量大小为1024,恒定学习率为 10−5 ,重量衰减为 10−8 。
标准ImageNet-1K训练的结果 表1(a)显示了使用常规ImageNet-1K训练与其他主干网(包括基于Transformer和基于ConvNet-based)的比较。
与先前最先进的基于Transformer的架构(即DeiT[63])相比,Swin Transformer明显超过了具有类似复杂性的对应DeiT架构:使用 2242 输入的SWN-T(81.3%)比DeiT-S(79.8%)高+1.5%,使用 2242/3842 输入的Swin-B(83.3%/84.5%)高于DEID-B(81.8%/83.1%)。
与最先进的ConvNet(即RegNet和EfficientNet)相比,Swin Transformer实现了稍微更好的速度-精度权衡。注意,虽然RegNet和EfficientNet是通过彻底的架构搜索获得的,但Swin Transformer是从标准Transformer改编而来的,具有进一步改进的巨大潜力。
ImageNet-22K预训练结果 论文还对ImageNet22K上的更大容量Swin-B和Swin-L进行了预训练。在ImageNet-1K图像分类上微调的结果如表1(b)所示。对于Swin-B,ImageNet22K预训练带来1.8%∼从零开始在ImageNet-1K上进行训练,获得1.9%的增益。与之前ImageNet-22K预训练的最佳结果相比,论文的模型实现了显著更好的速度-精度权衡:Swin-B获得了86.4%的顶级精度,比具有类似推理吞吐量(84.7 vs.85.9图像/秒)和略低的触发器(47.0G vs.55.4G)的ViT高2.4%。较大的SWN-L模型达到87.3%的top-1精度,比SWN-B模型高出+0.9%。
2、COCO上的目标检测
设置 在COCO 2017上进行了目标检测和实例分割实验,其中包含118K训练、5K验证和20K测试开发图像。使用验证集进行消融研究,并在test-dev上报告系统级比较。对于消融研究,考虑了四种典型的目标检测框架:Cascade Mask R-CNN、ATSS、RepPoints v2和mmdetection中的Sparse RCNN。对于这四个框架,论文使用相同的设置:多尺度训练(调整输入大小,使短边在480和800之间,而长边最多为1333),AdamW优化器(初始学习率为0.0001,权重衰减为0.05,批量大小为16),以及3倍调度(36个epochs)。对于系统级比较,采用改进的HTC(表示为HTC++),instaboost、更强的多尺度训练、6x调度(72个epochs)、软NMS和ImageNet-22K预训练模型作为初始化。
将Swin Transformer与标准Transformer网络(如ResNe(X)t)和以前的Transformer网络(例如DeiT)进行比较。通过在其他设置不变的情况下仅更改主干进行比较。请注意,尽管Swin Transformer和ResNe(X)t由于其分层特征映射而直接适用于所有上述框架,但DeiT仅产生特征映射的单一分辨率,不能直接应用。为了公平比较,论文使用反褶积层构建DeiT的分层特征图。
与ResNe(X)t的比较 表2(a)列出了Swin-T和ResNet-50在四个目标检测框架上的结果。Swin-T架构带来了一致的+3.4∼4.2 box AP比ResNet-50增益更高,模型尺寸、FLOPs和延迟稍大。
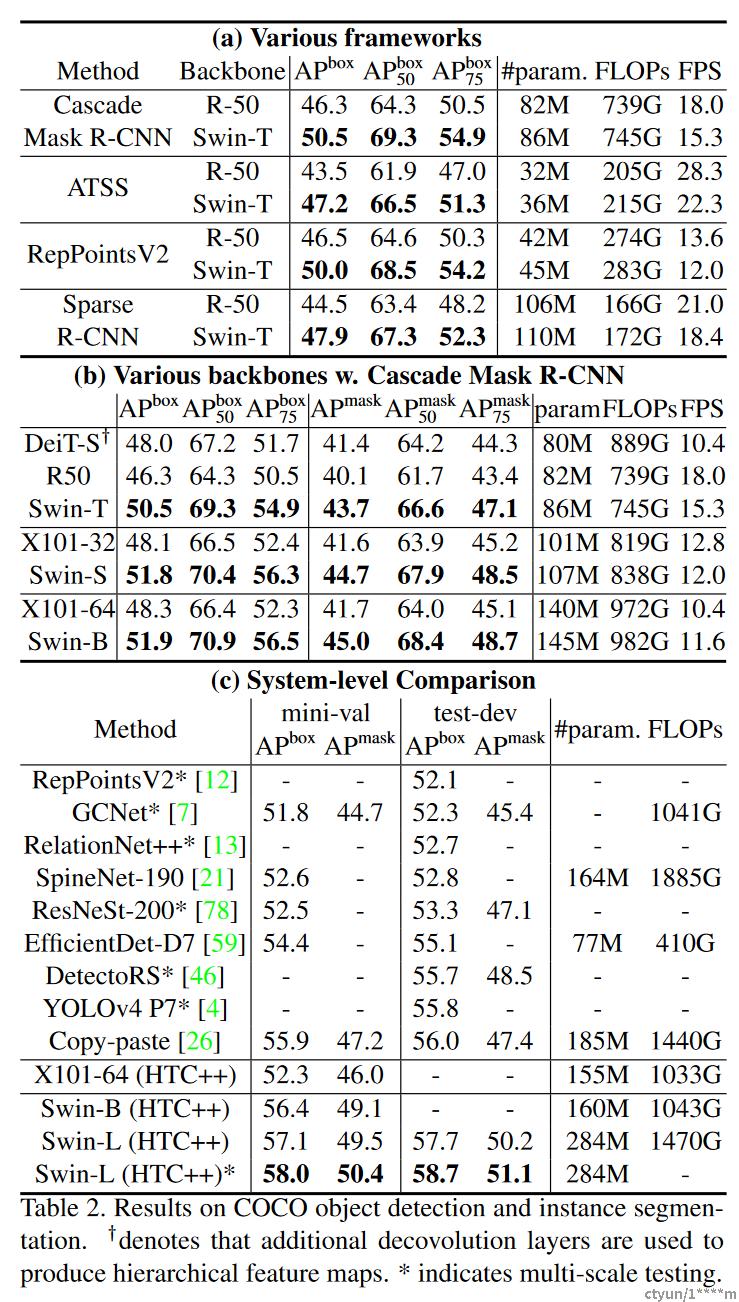
表2(b)使用Cascade Mask RCNN比较了不同模型容量下的Swin Transformer和ResNe(X)t。Swin Transformer实现了51.9 box AP和45.0 mask AP的高检测精度,与具有相似模型大小、FLOPs和延迟的ResNeXt10164x4d相比,这是+3.6 box AP和+3.3 mask AP的显著增益。在使用改进的HTC框架的52.3 box AP和46.0 mask AP的较高基线上,Swin Transformer的增益也较高,在+4.1 box AP和+3.1 mask AP(见表2(c))。关于推理速度,虽然ResNe(X)t是由高度优化的Cudnn函数构建的,但论文的架构是由内置的PyTorch函数实现的,这些函数并没有得到很好的优化。彻底的内核优化超出了本文的范围。
与DeiT的比较 使用Cascade Mask R-CNN框架的DeiT-S的性能如表2(b)所示。Swin-T的结果为+2.5 box AP和+2.3 mask AP,高于具有相似模型尺寸(86M与80M)的DeiT-S,且推理速度显著更高(15.3fps与10.4fps)。DeiT的推理速度较低主要是由于其对输入图像大小的二次复杂度。
与以前的先进技术相比 表2(c)将论文的最佳结果与先前最先进模型的结果进行了比较。论文的最佳模型在COCO测试开发中实现了58.7 box AP和51.1 mask AP,超过了之前的最佳结果+2.7 box AP和+2.6 mask AP。
五、结论
结论上,Swin Transformer 是一种基于 Transformer 结构的深度学习模型,它在自然语言处理和计算机视觉任务中表现出了优异的性能。相较于其他先进模型,在机器翻译、文本分类、问答系统等自然语言处理任务中,Swin Transformer 能够取得更好或相当的性能,同时在图像分类、目标检测、语义分割等计算机视觉任务中也表现出了非常出色的性能。Swin Transformer 的优势主要体现在其可扩展性和计算效率方面,使其在大规模数据处理和实时任务中表现优异。因此,Swin Transformer 是一种非常有前途的深度学习模型,有望在未来的自然语言处理和计算机视觉领域得到更广泛的应用。
