


Overview
前一篇文章深入了解Prometheus监控平台对prometheus的存储结构做了一下介绍,在后续的了解中,发现Prometheus的实现上实际上参考了Gorilla。
Gorilla 是Facebook内部孵化的一款内存时序数据库,用于存储Facebook内部监控系统的时序数据,采用了比较激进的压缩方式,节省大量的存储空间,同时基于内存的时序数据库,使得查询效率得到较大提高。
Gorilla的具体信息可以参考Facebook出的官方论文Gorilla: A Fast, Scalable, In-Memory Time Series Database
这篇文章主要想总结一下Gorilla的压缩算法。
时序数据的组成
对于Gorilla而言,每一个时序数据由一个三元组组成(这点和prometheus一致)
- key:
string类型,参考prometheus的series名 - timestamp:时间戳,64bit
- value:
float64类型,时序数据的值
Gorilla集qun由多个shard(实例)构成,时序存在哪一个shard上是对key进行计算得到,扩容时只需要修改分片函数,使得时序能够分配到新shard上即可。
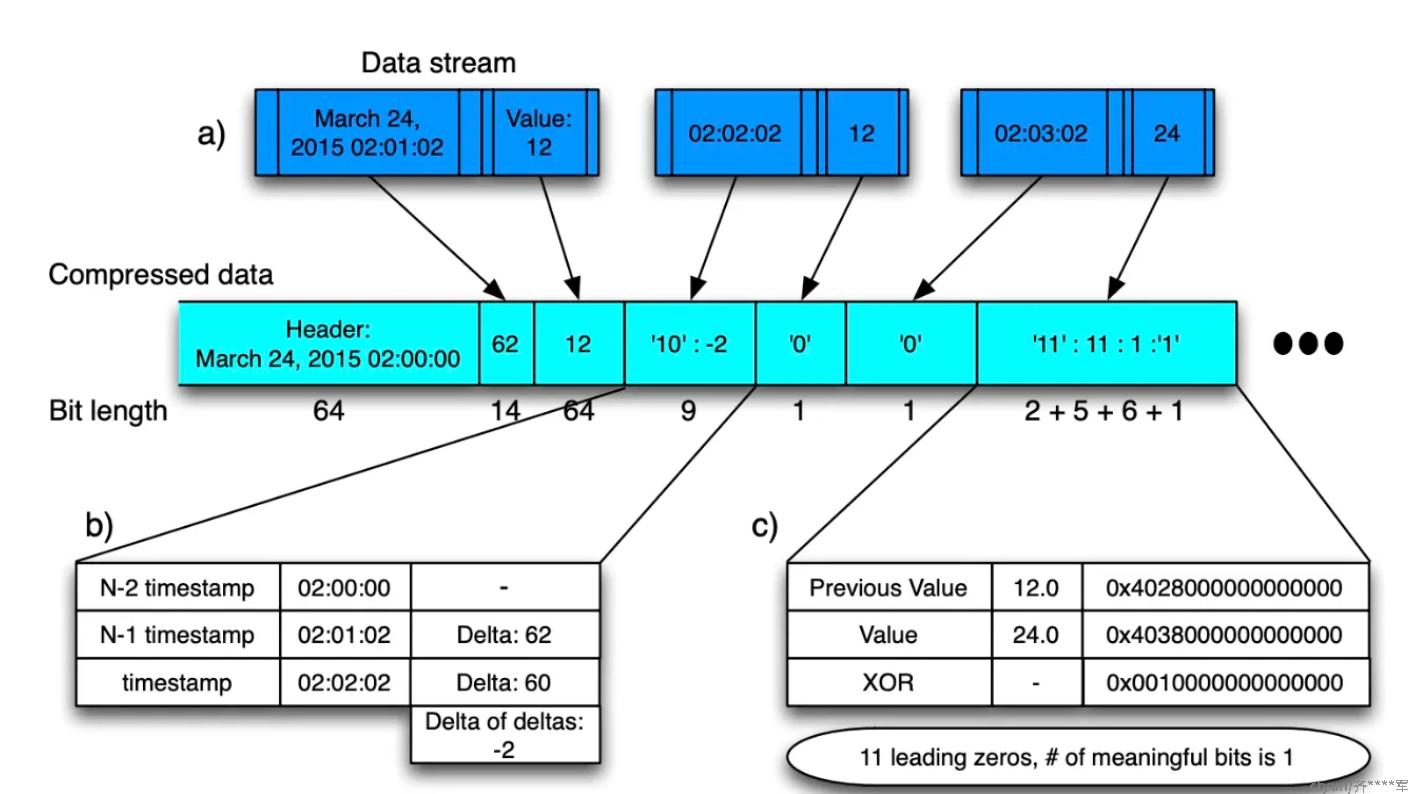
Gorilla的压缩算法使得压缩效率从没有压缩的16bytes/sample压到了1.37bytes/samples。大概的压缩流程如下图所示。
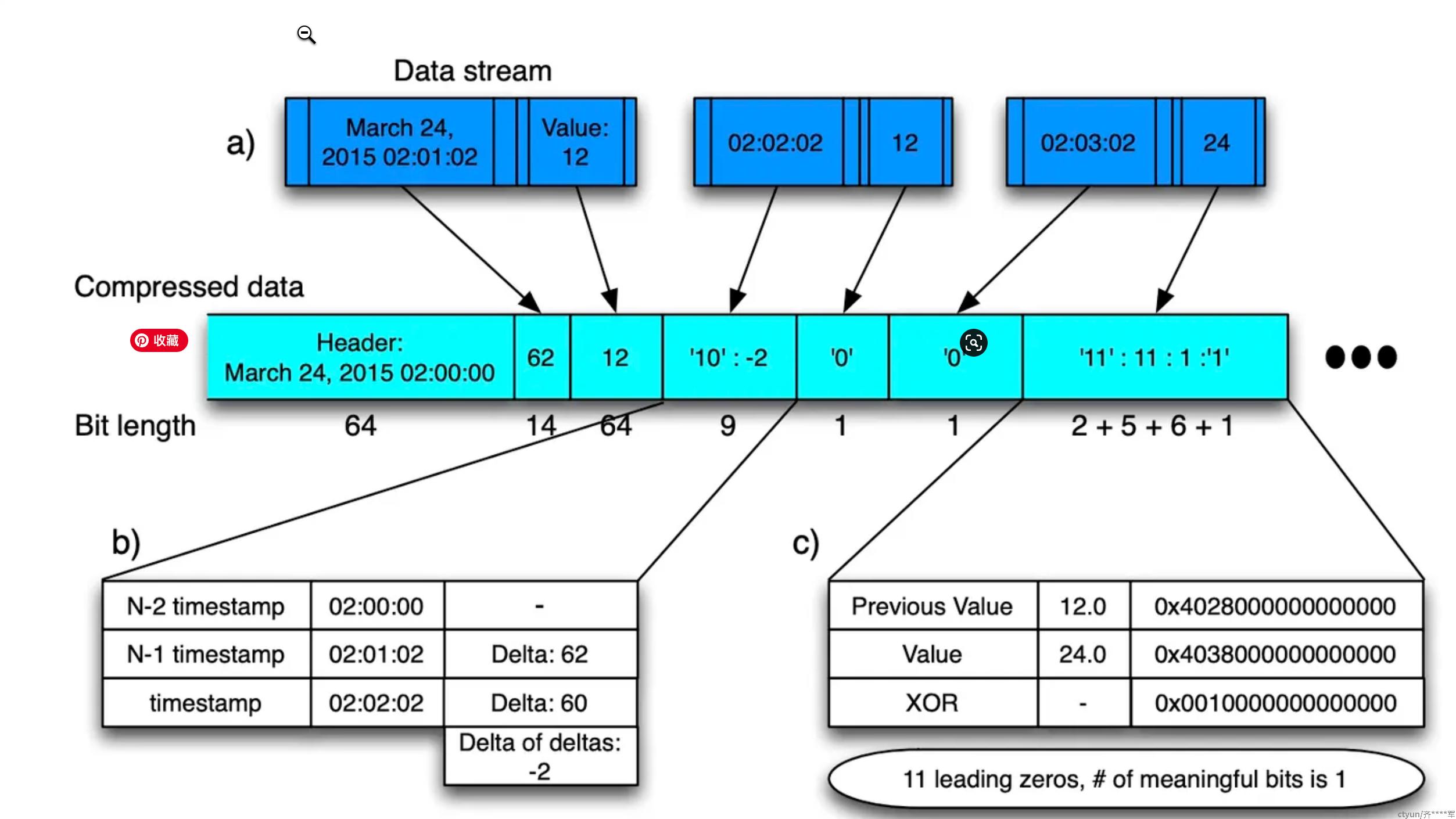
该压缩算法对时间戳和时序值采用了不同压缩方式,将在下文具体介绍。
delta of delta -- 时间戳压缩方式
Gorilla对时间戳采用的是delta of delta的压缩方式,感觉和信号/图形处理领域的差分编码思想上类似。
对于一个监控系统而言,我们的采样间隔总是固定的,因此采样的时间戳是很有规律的,比如第0s,第15s,第30s,第45s,只有少量的特殊情况会有较小的误差。
因此,如果我们存储的数据是和前一个时间的差值,那么我们就只需要存第一个完整的时间戳,后续的时间只需存和前一个的差值,即15,15,15,15,如果有部分误差的时间戳,则可能存的是16/14。这样就可以减少用于存储的bit。
再更进一步压缩,我们可以存储时间差的差值,第一个时间戳是0,第二个时间戳和第一个时间戳的差值是15,第三个时间戳和第二个时间的差值 减去第二个时间戳和第一个时间戳的差值 是0,因此我们存储的数据就是0,15,0,0。如果有部分误差的时间戳,那么0可能就是1/2/-1/-2。可以看出,所需要的bit数大幅地下降。
Gorilla采用的就是后面说的这种压缩方式(delta of delta)
 每一个时间窗口(2小时)的数据会存放在一个block当中,block header会存放这个时间窗口的开始时间(t−1t_{-1}t−1),需要64bit
每一个时间窗口(2小时)的数据会存放在一个block当中,block header会存放这个时间窗口的开始时间(t−1t_{-1}t−1),需要64bit
第一个时序数据会存储数据采样时间和起始时间的差值(t0t_0t0),需要14bit,这个14bit足够存2个小时的差值了。
然后,对于后续的每一个时间戳,采用下图(a)的公式计算delta of delta的值
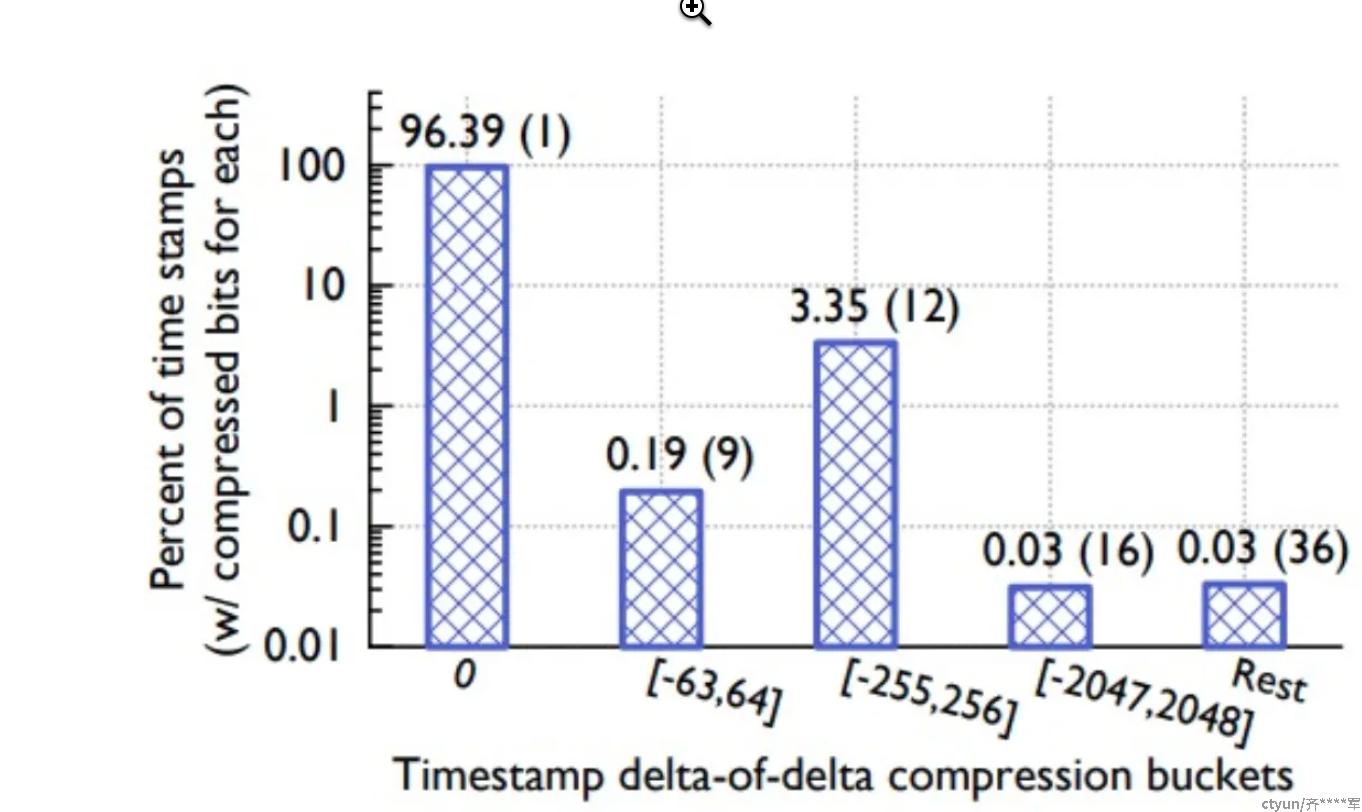
- 如果是0,则只需要存0这一个bit
- 如果大小在-63到64区间,则加上前缀10进行存储,一共存储2+7个bit
- 如果在-255到256区间,则加上前缀110进行存储,一共存储3+9个bit
- 如果在-2047到2048区间,则加上前缀1110进行存储,一共存储4+12bit
- 更大的话,则加上前缀1111,再加上实际的差值,一共32bit

对于这个区间的选择,应该是facebook通过具体数据的分析得到的。
从论文的图中可以看到,绝大部分的时间戳,其实用1个bit(0)存储就够了,需要用32位来存储的是极少数。
现在再回头看这个图,就可以知道他的时间是怎么算出来的了
t2t_2t2和t1t_1t1的差值是60,而前一个时间点的delta是62,计算出来的D=-2,在-63到64区间,所以需要加上10前缀,在用7bit存储-2
t3t_3t3的delta和t2t_2t2一样,所以直接存0,只用1bit
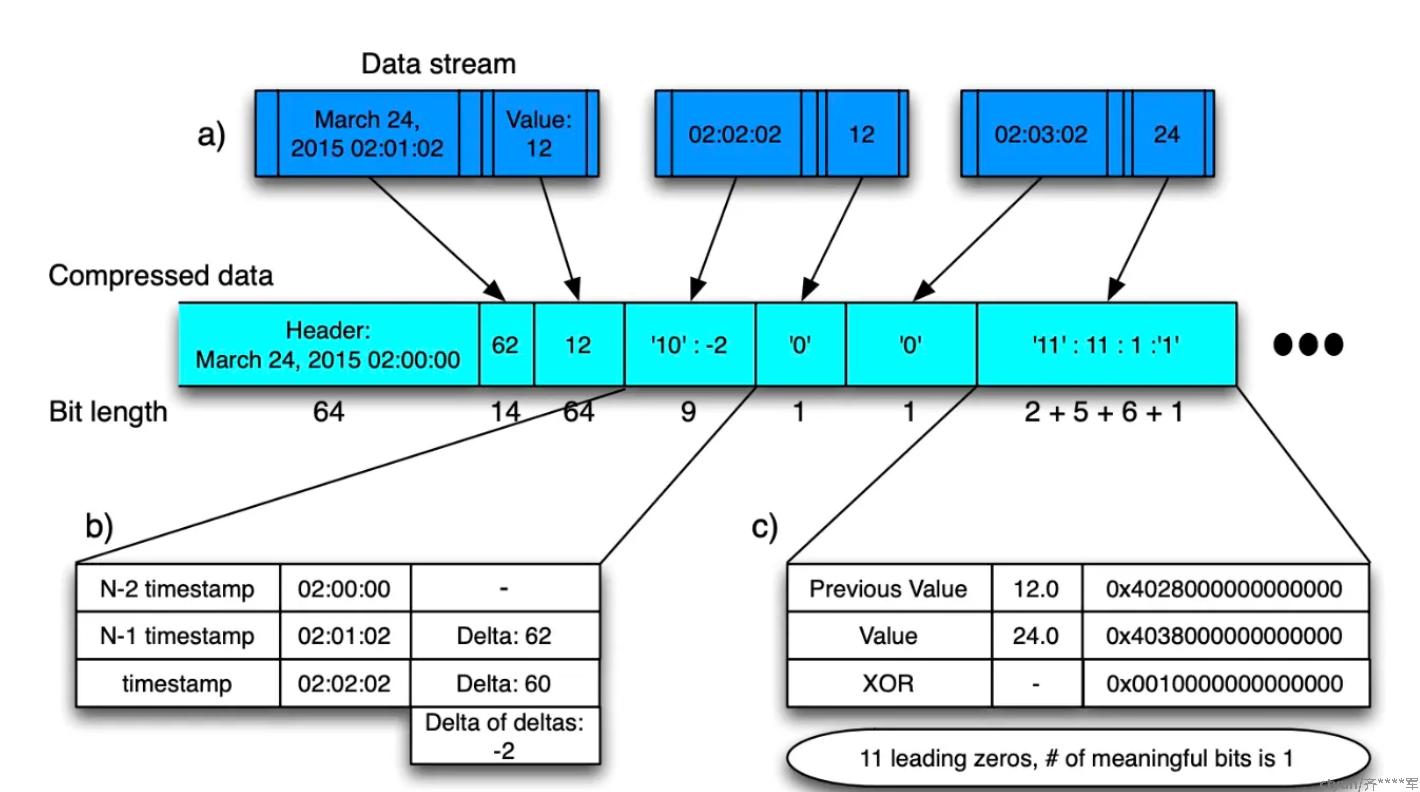
XOR -- 值压缩方式
Gorilla的值类型是float64双精度类型,对其进行压缩的方式则是将值和前一个值进行XOR异或
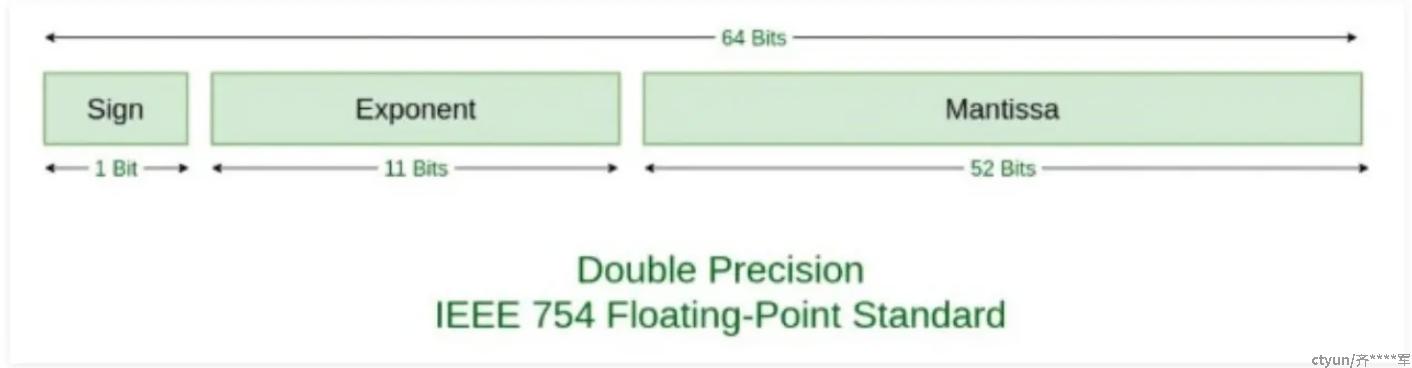
双精度浮点数的结构如上图,1位的符号位,11位的指数位,,和52位的小数位
对于监控系统而言,每隔固定的时间进行采样,其实数据量并不会有太大变化,对于平稳运行的的系统,不可能会cpu突然暴涨,内存突然暴涨。所以存储的值其实有很多位是一样的。
Gorilla利用这个特性,利用异或对数据进行压缩。


压缩的思路大致如下:
-
block的第一个数不压缩存储
-
后续的每个值和前一个值做XOR异或
-
如果结果为0,则只存储一位0
-
如果结果不为0,那么会有两种情况
- 如果异或的结果和前一个数异或的结果,他们的前导0和后导0数量一样,那么存储前缀
10加有效位的数据 - 如果前导0和后导0数量不一致,那么就存前缀
11+ 5位的前导0数量 +6位的有效位数量(实际上就是存了后导0数量) +有效位数据
- 如果异或的结果和前一个数异或的结果,他们的前导0和后导0数量一样,那么存储前缀
论文中也给出了一些实例
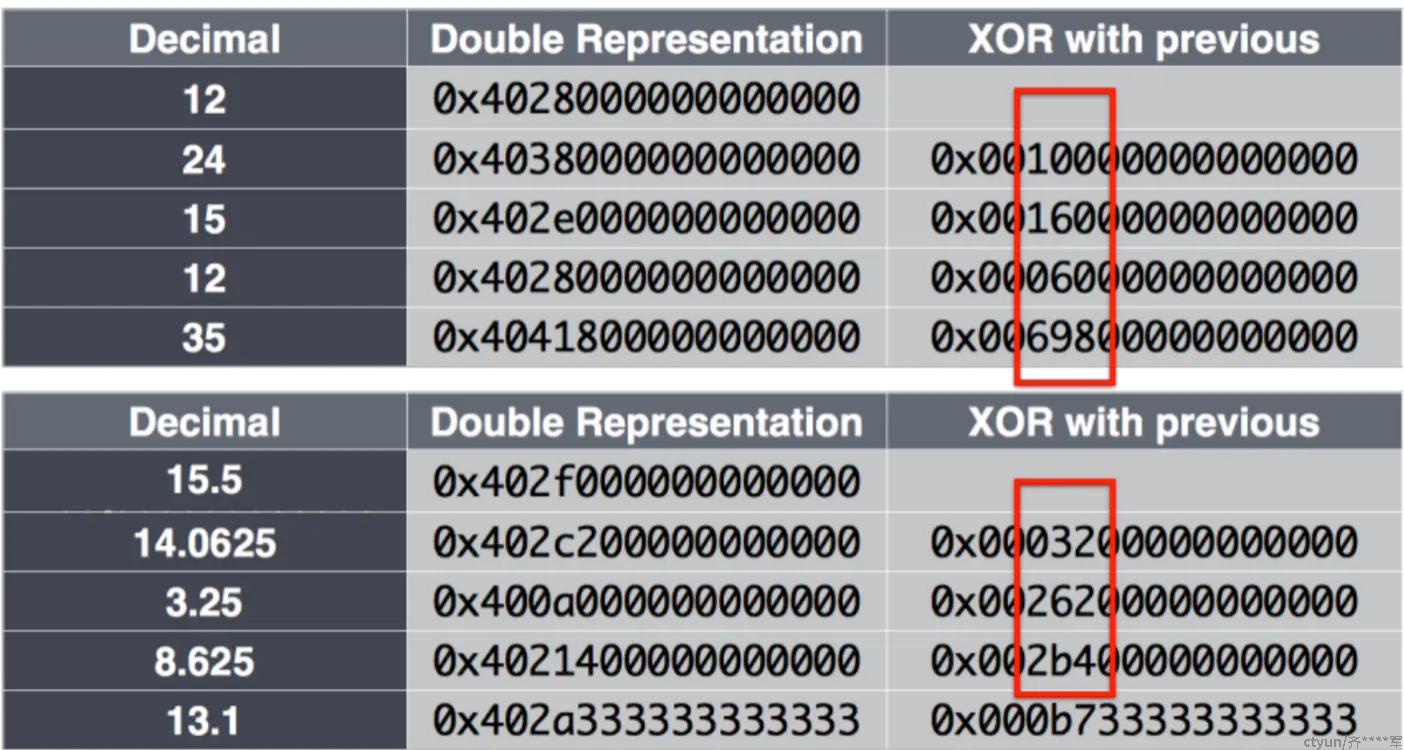
对于绝大部分的数据,是可以共享前导0和后导0的,因此需要用于存储的bit是较少的。
分布情况
同样的,再看这张图,可以知道第二个数据24的XOR结果(0)和前一个时序数据的XOR结果没有共享前后导0,因此需要存前缀11,然后数据0x001有11个前导0,有效为长度位1,有效位数据是1,最后存储的结果就如图所示。
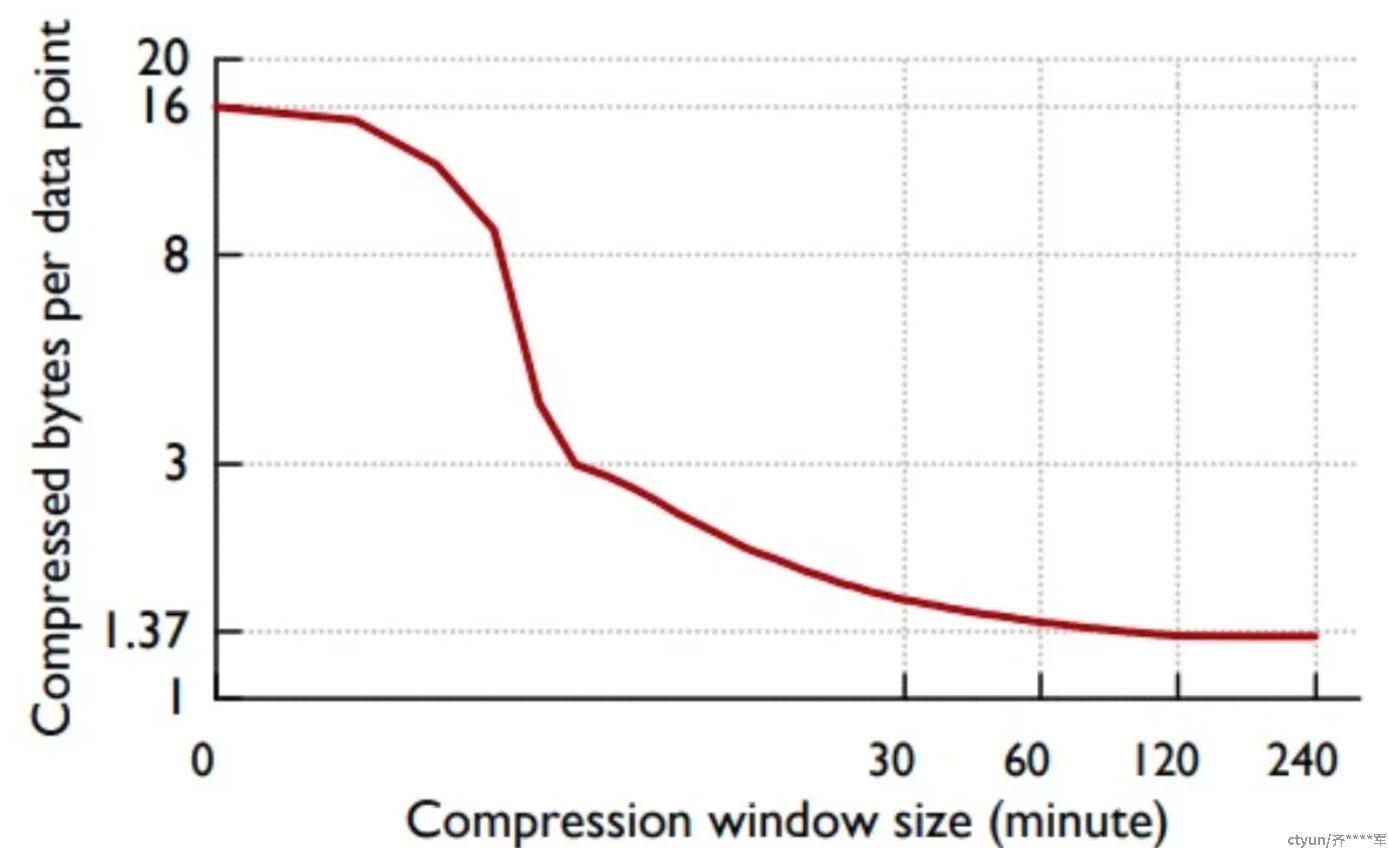
通过上面的压缩分析,其实如果一个block的时间窗口越长,压缩效率会越高。但同时,解压缩的成本的会相应提高,Facebook的论文给出的一个最合适的时间窗口为2小时,prometheus采用的也是这个值。
Gorilla内存中的数据结构
Gorilla的实现用的是C++,他存储的数据结构大致如下图所示
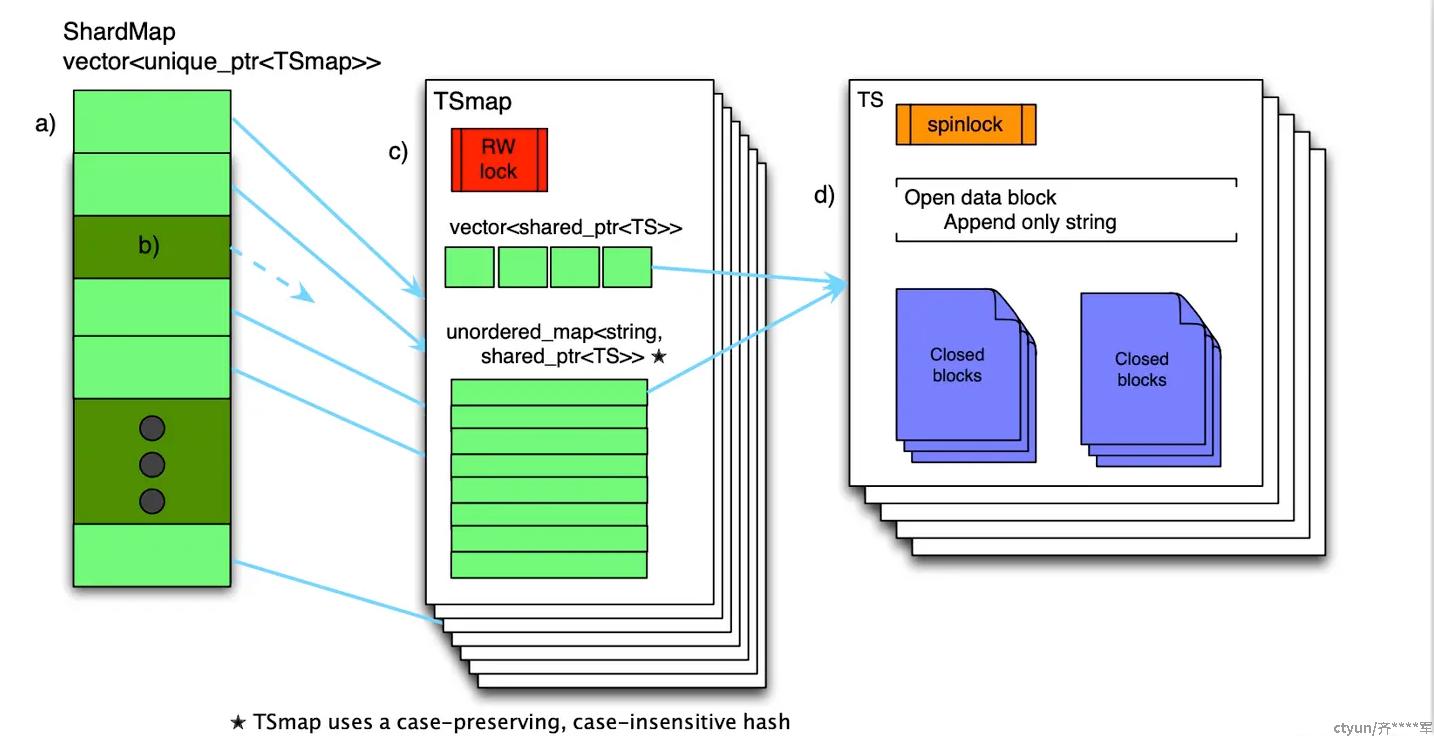
- shardMap是分片的map,ShardMap用一个数组vector来存储TSmap的指针(unique_ptr),查询时,通过key计算出时序在哪个分片shard上,然后快速查找到对应的TsMap上。
- TSmap即Timeseries Map,由一个vector和map组成,均作为时序数据的索引使用。vector的元素指向对应时间序列的智能指针(shared_ptr);map以时间序列的名称作为key(大小写不敏感但是保留大小写),指向时间序列的智能指针作为value。vector可以提供较好的范围查询能力,map提供较好的点查询能力。
- TS为真正存储数据的块,包含一个打开的block,用于写入新数据。和多个关闭的块,存储旧数据。每个块存储2个小时的数据
ps.TsMap对每个分片维护一个分片的读写锁,减小锁的粒度,不用锁全部数据。
与Gorilla不同,Gorilla 的解码放在客户端,而promethus的解码在服务端完成。
高可用
facebook在论文中提到,Gorilla通过将数据写到两个不同地区的集qun中,一个坏了会切换到另一个;
Gorrila在不同的数据中心维护两个完全一样但不考虑一致性的实例级别的数据副本,以实现数据中心故障或分区的情况下的高可用。
对于这点,prometheus感觉也是采样的相似的思路。
