


1、背景
随着云原生普及和快速发展,prometheus已经成为服务端监控的事实规范,各家云厂商也都提供了托管式的prometheus服务。开源的prometheus缺少集群化方案,很难直接应用在大规模的监控场景。急需一种需要能够兼容prometheus生态的tsdb产品应对大规模指标监控场景。本文主要横行对比目前主流的tsdb引擎特性及差异
2、横向对比
|
victoriametrics |
m3db |
thanos |
clickhouse |
|
|
安装部署 |
简单,只需要部署victoriametrics集群(可单机部署) |
较方便,需要部署M3集群、etcd集群,可通过prometheus remote与prometheus集成 |
较方便,需要部署thanos集群和ceph集群,需要在每个prometheus部署sidecar与thanos集成 |
较复杂,部署clickhouse实例和协调节点(zookeeper/ckeeper)、需要实现prometheus remote read/write adapt才能和prometheus对接 |
|
可用性 |
较高,无单点。查询、写入、存储分离。 storage节点数据副本能力较差,扩缩容及节点故障时,容易造成数据丢失 |
大量查询可能会影响数据的写入,可用性高 |
写入和查询经过sidecar,prometheus性能无法扩展 数据上传有周期限制,prometheus数据损坏则数据会丢失 |
高 |
|
数据实时性 |
高 |
高 |
较低,非实时数据存储在ceph,查询时速度较慢 |
高 |
|
升级、扩展 |
较方便,query、insert组件可以做HA |
方便、灵活 |
不方便 query组件可以做HA,其他组件单实例,store组件升级不便 |
较复杂 |
|
查询 |
响应快 |
响应较快 |
响应较慢 |
响应较慢 |
|
多租户 |
支持 通过account id |
不支持 |
支持 通过prometheus external label标识 |
需要适配 |
|
运维成本 |
低 |
需要维护m3db、etcd |
需要维护thanos、ceph、prometheus |
较高 |
|
HA |
vselect、vinsert需要部署负载均衡组件 |
支持 |
query支持 |
支持 |
|
数据备份 |
vmutil支持 |
支持 |
ceph支持 |
支持 |
|
数据压缩 |
支持(2byte/point) |
支持 |
支持 |
支持 |
|
降精度 |
开源版本不支持,query支持在查询时增加时间范围实现降精度效果 |
支持(namespace) |
支持 |
GraphiteMergeTree支持有限 |
|
社区活跃度 |
国内使用不多,社区较活跃 |
不太活跃 |
活跃 |
活跃,用来做prometheus remote storage较少 |
|
性能 |
vminsert 对资源要求较少 vmselect取决于查询qps和复杂度对mem/network要求较高 vmstorage对cpu/mem/disk要求高 |
m3db对dish/mem要求高 coordinator对mem/cpu要求高 |
sidecar对cpu/disk/mem/network要求一般 store对cpu/mem要求高,对disk磁盘要求低 |
clickhouse对cpu/mem/disk要求高 |
|
promql |
支持,有兼容性问题,官方兼容性测试用例通过率70%,常规使用无问题 |
支持 |
支持 |
不支持,需要开发适配 |
|
分布式能力(数据分片) |
不完善,不支持分布式协议,采用hash算法实现数据分布,shared-nothing |
完善(基于hash算法做数据分布,数据节点存储的虚拟分片保存在etcd) |
不完善 |
教完善 |
|
数据副本 |
支持,多副本,写入端写入多份数据,查询端查询多份数据后去重 |
支持,副本信息存储在etcd |
支持 | |
|
节点扩缩容 |
vinset,vselect节点无状态,vstroage存储节点,如果单副本存在,无法做到无损 |
多副本部署,无损扩缩容 |
支持 |
3、总结
prometheus
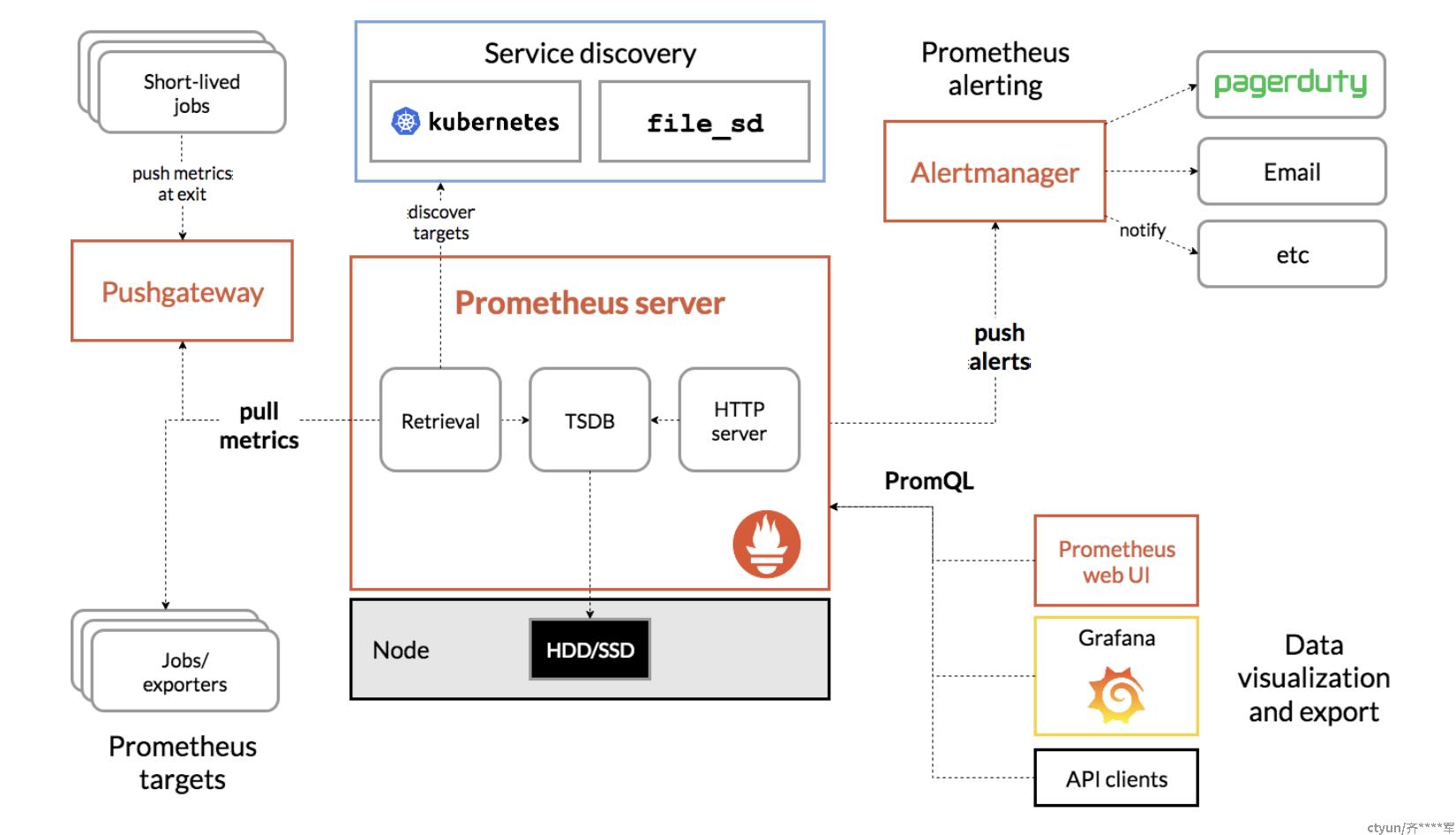
prometheus由前Google 员工,受Google 内部Borgman 的启发,2012年开始的开源项目,2018年进入毕业状态。是一个集数据采集、数据存储、异常检测、可视化为一体的全套监控解决方案,具有功能丰富、易用性高等特点。
VictoriaMetrics
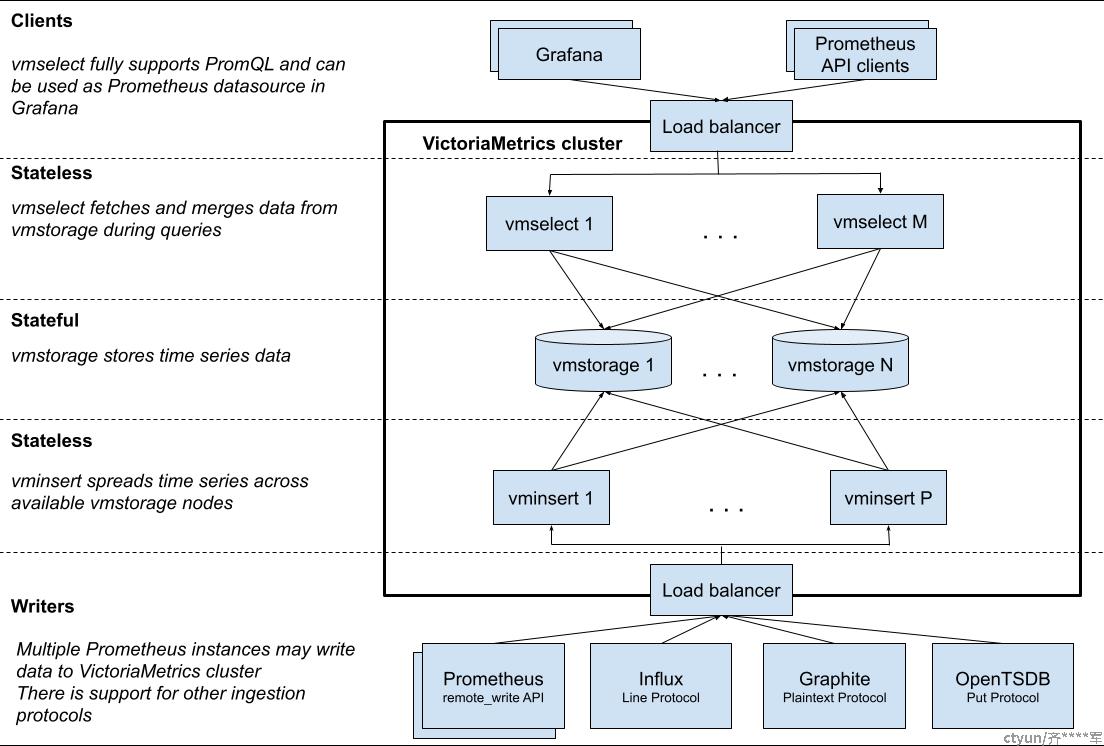
VictoriaMetrics 是一种快速、经济高效且可扩展的监控解决方案和时间序列数据库。支持单机和集群版本,单机版本支持超100万/s数据点的摄入,集群版本支持性能和容量的水平扩展,可以作为prometheus的远程存储,也可以直接替换prometheus使用。VictoriaMetrics的架构设计更加注重简单可靠和单机版的性能优化,而在分布式能力和高级功能方面相对较弱。downsample等功能目前只有企业版本支持,而数据的自动再平衡也需要用户自己实现。VictoriaMetrics是一个非常优秀的时序数据存储和查询引擎,适用于大多数中小型应用场景。
M3DB

M3DB架构设计上更高级,实现难度也更大。M3DB的设计目标是为了解决大规模时序数据存储和查询的问题,它的架构设计包含了多个组件,如存储节点、协调节点、查询节点等,同时还支持自动扩缩容和数据自动平衡等高级运维功能。M3DB的可靠性也更难保证,由于其架构设计较为复杂,各个组件之间的依赖关系也比较复杂,因此在运维和维护方面需要付出更多的精力和成本。同时,M3DB的学习曲线也相对较陡峭,需要花费一定的时间和精力去掌握其使用方法和技术细节。M3DB在国内的社区活跃度也较低。
Thanos
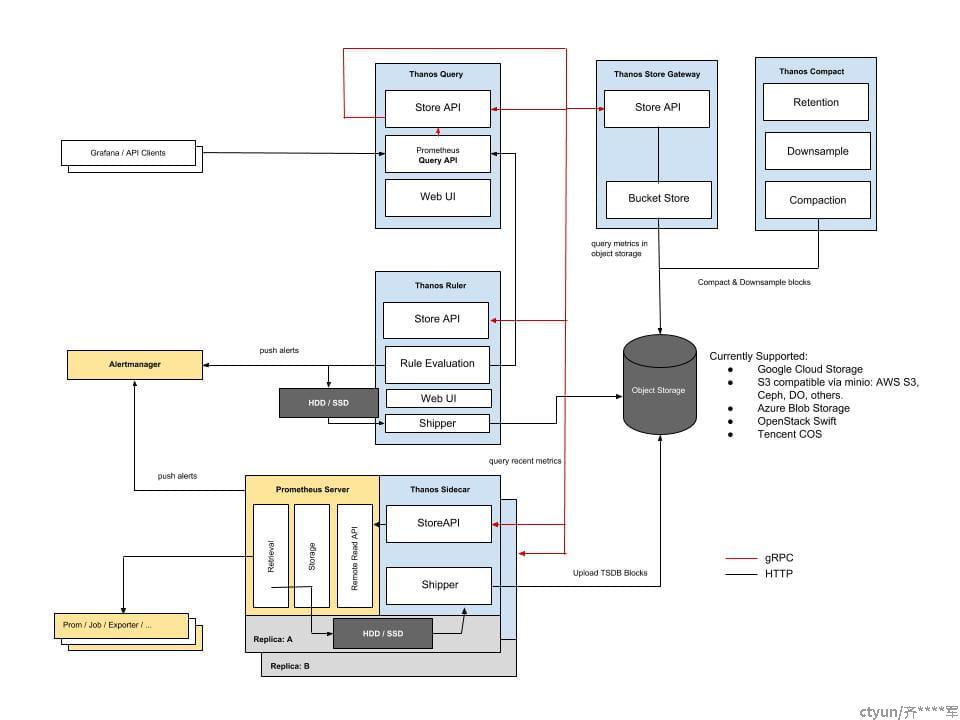
Thanos 是一个开源的分布式系统的监控和告警系统,它可以整合多个 Prometheus 服务器的数据,并提供查询和告警的功能。Thanos 的主要目标是解决 Prometheus 在长期存储和全局查询方面的不足之处。通过 Thanos,用户可以将 Prometheus 数据存储在对象存储中,从而允许用户保存更长时间的历史数据。同时,Thanos 可以跨多个数据中心查询 Prometheus 数据,从而方便用户进行全局监控和分析。Thanos 还支持水平扩展,通过添加更多的 Prometheus 服务器来扩展其能力,从而支持更大规模的监控。如果您需要进行大规模的分布式系统监控,可以考虑使用 Thanos。
Thanos需要引入额外的组件,同样也会给架构带来复杂性,配置也较复杂度,Thanos 的查询性能可能会受到多个 Prometheus 服务器的影响,从而导致一些性能损失。
