


Kubernetes Operators是连接到主API并监视事件的进程,通常在有限数量的资源类型上。
当相关事件发生时,操作员会做出反应并执行特定操作。这可能仅限于与主API交互,但通常会涉及在一些其他系统上执行一些操作(这可能是在Cluster内或Cluster外的资源)。
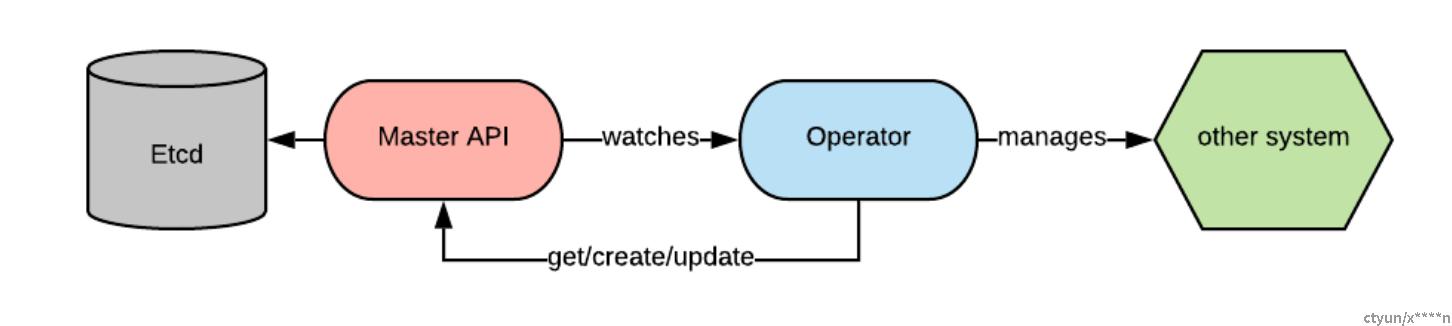
Operator被实现为控制器的集合,其中每个控制器监视特定的资源类型。当监视的资源上发生相关事件时,将启动调谐循环。
在调谐周期内,控制器有责任检查当前状态是否与被监视资源所描述的期望状态相匹配。有趣的是,在设计中事件不会传递给调谐循环,调谐循环被强制设计为关注事件关联的实例的整个状态。
基于水平的触发虽然效率较低,但由于它强制重新评估整个状态而不是只关注改变的状态,因此被认为更适合于复杂且不可靠的环境,在这种情况下信号可能会丢失或重复多次。
这种设计选择会影响我们编写控制器代码的方式。
与此讨论相关的还有对API请求生命周期的理解。下图提供了一个概要总结:
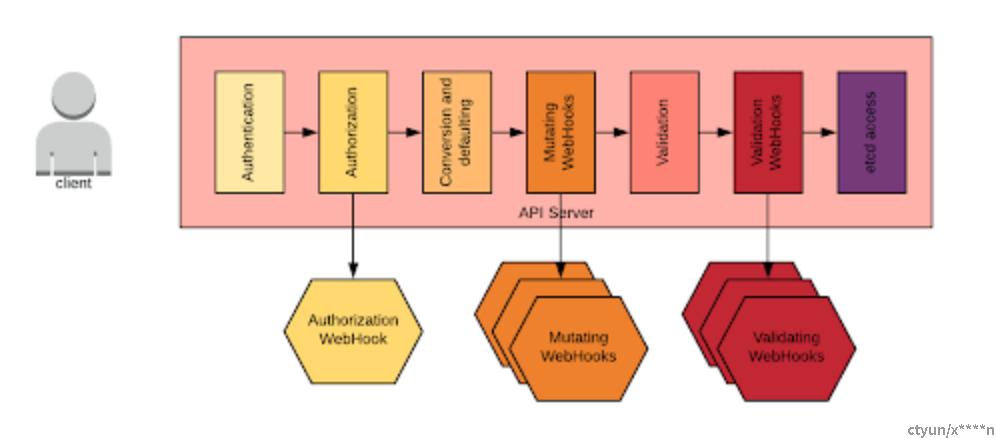
当向API服务器发出请求时,特别是对于创建和删除请求,请求将经历上述阶段。请注意,可以指定webhooks来执行互斥和校验。如果Operator引入了新的自定义资源定义( custom resource definition,CRD),我们可能还必须定义这些webhook。通常,Operator进程也会通过侦听端口来实现webhook端点。
本文档介绍了使用Operator SDK设计和开发Operator时要记住的一组最佳实践。
如果你的Operator引入了新的CRD,Operator SDK将协助构建它。要确保你的CRD符合Kubernetes扩展API的最佳实践,请遵循这些约定。
本文中提到的所有最佳实践都在operator-utils仓库中提供的示例中进行了描述。该仓库输出是一个可被依赖的库包,你可以在Operator中导入该库,为你编写自己的Operator提供一些有用的工具。
最后,这套编写Operator的最佳实践代表了我个人的观点,不应被视为红帽最佳实践的正式列表。
创建监视器
正如我们所说,控制器在资源上观察事件。这是通过抽象的监控来完成。
监视是一种接收特定类型(核心类型或CRD)事件的机制。通常通过指定以下内容来创建监视:
1.要监视的资源类型。
2.处理程序。处理程序将监视类型上的事件映射到调用协调周期的一个或多个实例,监视的类型和实例类型不必相同。
3.一个Predicate。Predicate可以是一组函数,可以自定义,仅用来过滤我们感兴趣的事件。
下图描述了整个过程:
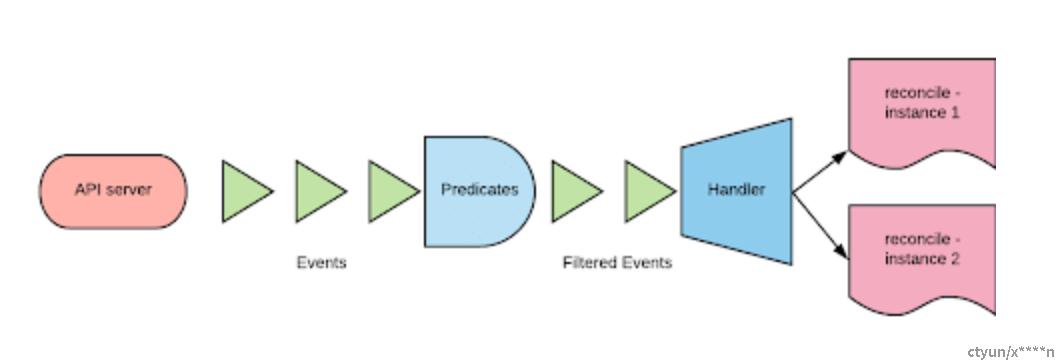
通常,打开同一种类的多个监视是可以接受的,因为监视是多路复用的。
你还应尝试尽可能过滤事件。例如,这里是一个过滤Secret事件的描述。这里我们只对有特定的注解的kubernetes.io/tls类型的Secret事件感兴趣:
isAnnotatedSecret := predicate.Funcs{
UpdateFunc: func(e event.UpdateEvent) bool {
oldSecret, ok := e.ObjectOld.(*corev1.Secret)
if !ok {
return false
}
newSecret, ok := e.ObjectNew.(*corev1.Secret)
if !ok {
return false
}
if newSecret.Type != util.TLSSecret {
return false
}
oldValue, _ := e.MetaOld.GetAnnotations()[certInfoAnnotation]
newValue, _ := e.MetaNew.GetAnnotations()[certInfoAnnotation]
old := oldValue == "true"
new := newValue == "true"
// if the content has changed we trigger if the annotation is there
if !reflect.DeepEqual(newSecret.Data[util.Cert], oldSecret.Data[util.Cert]) ||
!reflect.DeepEqual(newSecret.Data[util.CA], oldSecret.Data[util.CA]) {
return new
}
// otherwise we trigger if the annotation has changed
return old != new
},
CreateFunc: func(e event.CreateEvent) bool {
secret, ok := e.Object.(*corev1.Secret)
if !ok {
return false
}
if secret.Type != util.TLSSecret {
return false
}
value, _ := e.Meta.GetAnnotations()[certInfoAnnotation]
return value == "true"
},
}
一个非常常见的模式是观察我们创建(和我们拥有)资源上的事件,并在拥有这些资源的CR上安排协调周期,这样做可以使用EnqueueRequestForOwner处理程序。这可以按如下方式完成:
err = c.Watch(&source.Kind{Type: &examplev1alpha1.MyControlledType{}}, &handler.EnqueueRequestForOwner{})
不太常见的情况是事件被组播到多个目标资源。考虑基于注释将TLS密钥注入到路由的控制器情况中。同一命名空间中的多个路由可以指向相同的密钥。如果密钥改变,我们需要更新所有路由。因此,我们需要在密钥类型上创建一个监视器,处理程序将如下所示:
type enqueueRequestForReferecingRoutes struct {
client.Client
}
// trigger a router reconcile event for those routes that reference this secret
func (e *enqueueRequestForReferecingRoutes) Create(evt event.CreateEvent, q workqueue.RateLimitingInterface) {
routes, _ := matchSecret(e.Client, types.NamespacedName{
Name: evt.Meta.GetName(),
Namespace: evt.Meta.GetNamespace(),
})
for _, route := range routes {
q.Add(reconcile.Request{NamespacedName: types.NamespacedName{
Namespace: route.GetNamespace(),
Name: route.GetName(),
}})
}
}
// Update implements EventHandler
// trigger a router reconcile event for those routes that reference this secret
func (e *enqueueRequestForReferecingRoutes) Update(evt event.UpdateEvent, q workqueue.RateLimitingInterface) {
routes, _ := matchSecret(e.Client, types.NamespacedName{
Name: evt.MetaNew.GetName(),
Namespace: evt.MetaNew.GetNamespace(),
})
for _, route := range routes {
q.Add(reconcile.Request{NamespacedName: types.NamespacedName{
Namespace: route.GetNamespace(),
Name: route.GetName(),
}})
}
}
资源调谐周期
协调周期是监视产生事件上传后,框架给我们重新控制的地方。如前所述,此时我们没有关于事件类型的信息,因为我们正在处理基于层别的触发器。
下面是管理CRD的控制器的常见协调周期的模型。与每个模型一样,这并不能完全反映任何特定的用例,但我希望是有用的,当你在编写运算符考虑解决问题的时候。
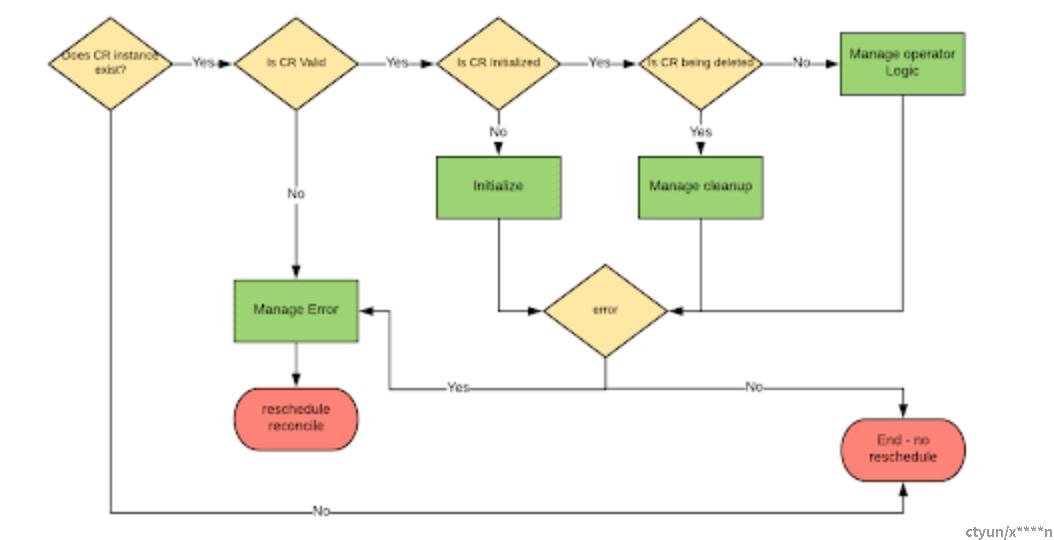
从图中可以看出,主要步骤是:
1.检索感兴趣的CR实例。
2.管理实例有效性。我们对不带有效值的实例不执行任何操作。
3.管理实例初始化。如果未初始化实例的某些值,则本节将负责处理。
4.管理实例删除。如果实例被删除,我们需要进行一些特定的清理,这就是我们管理它的地方。
5.管理控制器业务逻辑。如果上述步骤全部通过,我们最终可以管理和执行此特定实例的协调逻辑。这跟控制器非常相关的。
在本节的其余部分中,你可以在每个步骤中找到更深入的考虑因素。
资源验证
存在两种类型的验证:语法验证和语义验证。
语法验证:通过定义OpenAPI验证规则来进行语法验证。
语义验证:通过创建ValidatingAdmissionConfiguration来完成语义验证。
注意:无法在控制器中验证CR。一旦CR服务器接受CR,它将存储在etcd中。一旦它在etcd中,拥有它的控制器就无法拒绝它,如果CR无效,尝试使用/处理它将导致错误。
建议:因为我们不能保证将创建和/或运行ValidatingAdmissionConfiguration,我们还应该从控制器内验证CR,如果它们无效则避免创建无限错误循环(另请参阅:错误管理)。
语法验证
可以按照此处所述添加OpenAPI验证规则。
建议:尽可能多地为自定义资源建模作为语法验证的验证。语法验证相对简单,可防止格式错误的CR存储在etcd中,因此应尽可能使用它。
语义验证
语义验证是关于确保字段具有合理的值并且整个资源记??录是有意义的。语义验证业务逻辑取决于CR表示的概念,必须由Operatir开发人员编码。
如果给定CR需要语义验证,则Operator应公开webhook,并且应在Operator部署中创建ValidatingAdmissionConfiguration。
目前存在以下限制:
在OpenShift 3.11中,ValidatingAdmissionConfigurations处于技术预览中(从4.1开始支持它们)。
Operator SDK不支持脚手架webhooks。这可以使用kubebuilder来解决,例如:
kubebuilder webhook --group crew --version v1 --kind FirstMate --type=mutating --operations=create,update
验证控制器中的资源
最好拒绝无效的CR,而不是在etcd中接受它,然后管理错误条件。也就是说,可能存在未部署或根本不可用的ValidatingAdmissionConfiguration的情况。我认为在控制器代码中进行语义验证仍然是一个好习惯。代码的结构应使你可以在ValidatingAdmissionConfiguration和控制器之间共享相同的验证例程。
调用验证方法的控制器代码应如下所示:
if ok, err := r.IsValid(instance); !ok {
return r.ManageError(instance, err)
}
请注意,如果验证失败,我们会按照错误管理部分中的说明管理此错误。
IsValid的函数类似于:
func (r *ReconcileMyCRD) IsValid(obj metav1.Object) (bool, error) {
mycrd, ok := obj.(*examplev1alpha1.MyCRD)
// validation logic
}
资源初始化
Kubernetes资源的一个很好的传统特性是,只有资源的所需字段由用户初始化,其他字段可以省略。这是从用户角度看到的,但是从编码者和调试资源发生的事情的角度来看,实际上更好地选择是初始化所有字段。 这允许编写代码过程中无需始终检查字段是否已定义,并允许轻松排除错误情况。 为了初始化资源,有两种选择:
a. 在控制器中定义初始化方法。
b. 定义MutatingAdmissionConfiguration(该过程类似于ValidatingAdmissionConfiguration)
推荐:在控制器中定义初始化方法。代码应如下所示:
if ok := r.IsInitialized(instance); !ok {
err := r.GetClient().Update(context.TODO(), instance)
if err != nil {
log.Error(err, "unable to update instance", "instance", instance)
return r.ManageError(instance, err)
}
return reconcile.Result{}, nil
}
请注意,如果结果为true,我们更新实例然后返回。这将触发另一个立即协调周期。第二次初始化方法将返回false,逻辑将继续到下一阶段。
资源回收
如果资源不是由Operator控制的CR拥有,但在删除CR时需要采取措施,则必须使用回收器。
回收器提供了一种机制,通知Kubernetes控制面板在执行标准Kubernetes垃圾收集逻辑之前需要执行相关操作。
可以在资源上设置一个或多个终结器。每个控制器应管理自己的回收器,如果存在则忽略其他回收器。
这是管理回收器的伪代码算法:
- 如果需要,在初始化方法期间添加回收器。
2. 如果正在删除资源,请检查此控制器拥有的回收器是否存在。
a. 如果没有,请返回
b. 如果是,请执行清理逻辑
i. 如果成功,请通过删除回收器来更新CR
ii. 如果失败决定是否重试或放弃并可能留下垃圾(在某些情况下这是可以接受的)
如果清理逻辑需要创建其他资源,请记住,无法在要删除的命名空间中创建其他资源。要删除的命名空间将触发包含CR和回收器在内的所有内容的删除。
请在此处查看代码示例:
if util.IsBeingDeleted(instance) {
if !util.HasFinalizer(instance, controllerName) {
return reconcile.Result{}, nil
}
err := r.manageCleanUpLogic(instance)
if err != nil {
log.Error(err, "unable to delete instance", "instance", instance)
return r.ManageError(instance, err)
}
util.RemoveFinalizer(instance, controllerName)
err = r.GetClient().Update(context.TODO(), instance)
if err != nil {
log.Error(err, "unable to update instance", "instance", instance)
return r.ManageError(instance, err)
}
return reconcile.Result{}, nil
}
资源所有权
资源所有权是Kubernetes中的一个本地概念,用于确定如何删除资源。当删除资源及该资源拥有的其他资源时,默认情况下也会删除子资源(您可以通过设置cascade = false来禁用此行为)。
此行为有助于确保正确的资源垃圾收集,尤其是当资源控制多级层次结构中的其他资源时(请考虑Deployment-> Repilcaset-> Pod)。
推荐:如果你的控制器创建资源并且这些资源的生命周期与资源(核心或CR)相关联,那么你应该将此资源设置为这些资源的所有者。这可以按如下方式完成:
controllerutil.SetControllerReference(owner, obj, r.GetScheme())
所有权的其他一些规则如下:
owner对象必须与拥有对象位于同一名称空间中。
命名空间资源可以拥有Cluster级别资源。我们在这里要小心。对象可以有一系列所有者。如果多个命名空间对象拥有相同的Cluster级别对象,则每个对象都应声明所有权而不应该覆盖其他人的所有权(上述API负责这一点)。
Cluster级别资源不能拥有命名空间资源。
Cluster级别对象可以拥有另一个Cluster级别对象。
管理状态
Status是资源的标准部分。Status显然用于报告资源的状态。在本文档中,我们将使用Status来报告上次执行协调周期的结果。你可以使用状态添加更多信息。
在正常情况下,如果我们每次执行协调周期时都在更新资源,这将触发更新事件,而事件又会在无限循环中触发协调周期。
出于这个原因,Status应该建模为一个子资源,如这里所解释的。
这样,我们可以在不增加ResourceGeneration元数据字段的情况下更新资源状态。我们可以使用以下命令更新状态:
err = r.Status().Update(context.Background(), instance)
现在我们需要为我们的监视编写一个描述(请参阅有关这些概念的更多详细信息的监视部分),这些描述将忽略不增加ResourceGeneration的更新,这可以使用GenerationChangePredicate来完成。
如果你还记得,如果我们使用回收器,则应在初始化时设置回收器。如果回收器是唯一正在初始化的,因为它是元数据字段的一部分,ResourceGeneration将不会递增。为了解释该用例,以下是predicate的修改版本:
type resourceGenerationOrFinalizerChangedPredicate struct {
predicate.Funcs
}
// Update implements default UpdateEvent filter for validating resource version change
func (resourceGenerationOrFinalizerChangedPredicate) Update(e event.UpdateEvent) bool {
if e.MetaNew.GetGeneration() == e.MetaOld.GetGeneration() && reflect.DeepEqual(e.MetaNew.GetFinalizers(), e.MetaOld.GetFinalizers()) {
return false
}
return true
}
现在假设你的状态如下:
type MyCRStatus struct {
// +kubebuilder:validation:Enum=Success,Failure
Status string `json:"status,omitempty"`
LastUpdate metav1.Time `json:"lastUpdate,omitempty"`
Reason string `json:"reason,omitempty"`
}
你可以写一个方法来管理调谐周期内的一次成功执行流程:
func (r *ReconcilerBase) ManageSuccess(obj metav1.Object) (reconcile.Result, error) {
runtimeObj, ok := (obj).(runtime.Object)
if !ok {
log.Error(errors.New("not a runtime.Object"), "passed object was not a runtime.Object", "object", obj)
return reconcile.Result{}, nil
}
if reconcileStatusAware, updateStatus := (obj).(apis.ReconcileStatusAware); updateStatus {
status := apis.ReconcileStatus{
LastUpdate: metav1.Now(),
Reason: "",
Status: "Success",
}
reconcileStatusAware.SetReconcileStatus(status)
err := r.GetClient().Status().Update(context.Background(), runtimeObj)
if err != nil {
log.Error(err, "unable to update status")
return reconcile.Result{
RequeueAfter: time.Second,
Requeue: true,
}, nil
}
} else {
log.Info("object is not RecocileStatusAware, not setting status")
}
return reconcile.Result{}, nil
}
管理错误
如果控制器进入错误状态并在协调方法中返回错误,则Operator将错误记录到标准输出,并立即重新调度协调事件(默认调度程序应实际检测是否反复出现相同的错误,并增加调度时间,但根据我的经验,这不会发生)。如果错误条件是永久性的,则会产生永久错误循环情况。此外,用户不会看到此错误情况。
有两种方法可以通知用户错误,并且可以同时使用它们:
1.返回对象状态中的错误。
2. 生成描述错误的事件。
此外,如果你认为错误可能会自行解决,则应在一段时间后重新安排协调周期。通常,该时间段以指数方式增加,以便在每次迭代时,将在未来进一步安排协调事件(例如,每次的时间量的两倍)。
我们将在状态管理的基础上构建处理错误情况:
func (r *ReconcilerBase) ManageError(obj metav1.Object, issue error) (reconcile.Result, error) {
runtimeObj, ok := (obj).(runtime.Object)
if !ok {
log.Error(errors.New("not a runtime.Object"), "passed object was not a runtime.Object", "object", obj)
return reconcile.Result{}, nil
}
var retryInterval time.Duration
r.GetRecorder().Event(runtimeObj, "Warning", "ProcessingError", issue.Error())
if reconcileStatusAware, updateStatus := (obj).(apis.ReconcileStatusAware); updateStatus {
lastUpdate := reconcileStatusAware.GetReconcileStatus().LastUpdate.Time
lastStatus := reconcileStatusAware.GetReconcileStatus().Status
status := apis.ReconcileStatus{
LastUpdate: metav1.Now(),
Reason: issue.Error(),
Status: "Failure",
}
reconcileStatusAware.SetReconcileStatus(status)
err := r.GetClient().Status().Update(context.Background(), runtimeObj)
if err != nil {
log.Error(err, "unable to update status")
return reconcile.Result{
RequeueAfter: time.Second,
Requeue: true,
}, nil
}
if lastUpdate.IsZero() || lastStatus == "Success" {
retryInterval = time.Second
} else {
retryInterval = status.LastUpdate.Sub(lastUpdate).Round(time.Second)
}
} else {
log.Info("object is not RecocileStatusAware, not setting status")
retryInterval = time.Second
}
return reconcile.Result{
RequeueAfter: time.Duration(math.Min(float64(retryInterval.Nanoseconds()*2), float64(time.Hour.Nanoseconds()*6))),
Requeue: true,
}, nil
}
请注意,此函数会立即发送事件,然后使用错误条件更新状态。最后,计算何时重新安排下一次尝试。该算法尝试将每个循环的时间加倍,最多可达六个小时。
六小时是一个很好的上限,因为事件持续大约六个小时,所以这应该确保始终存在描述当前错误情况的活动事件。
