


问题描述
客户使用redis服务,LB后端挂载16台redis db,当连接空闲5分钟后,客户端再次写数据时,redishuirst报文,客户端报 conntion rst by peer 异常。
问题分析
如果redis server的连接在5分钟之内没有任何数据的传输,sever会主动调用close()将连接关闭(tcp经过4次握手正常关闭连接),不会出现client的异常断开,在server端抓包发现redis向client的发送的fin + ack包一直在重传直到超时,所以当client,再次尝试发送数据时,此连接被redis reset了。
问题定位过程
初步分析
通过抓包看,fin + ack在有重传而且重传了很多次,所以判断server到client此方向的链路上,包被丢弃了
1. 首先怀疑是公网ip的带宽不够,通过sar命令查看,业务的流量不是很大,排除是QoS问题。
2. 因为先前出现过一例因为ct检测连接时checksum的不对将丢弃fin + ack的包,所以怀疑是ovs将包丢弃了,通过tcpdump确认的确是ovs的ct将包丢弃了,所以我们关闭了ct checksum检查,然后观察问题是否还会出现,同时我们也在测试环境复现此问题。
3. 修改了checksum后,问题未复现,可能和问题的发生频率有关系,幸运的事,我们在测试环境很快便复现此问题。

redis: 10.0.1.64,client: 10.226.192.70
10.0.1.64 --> 10.226.192.70的fin+ack有tcp 重传,但是10.226.192.70 <--> 10.0.1.64发送的keep-alive是正常的。
测试环境debug
测试环境复现了之后,关闭ct的checksum,关闭方式如下命令:
sysctl -w net.netfilter.nf_conntrack_checksum=0问题依然存在,确定不是checksum的问题,在ct的tcp有一个参数超时时间设置正是5分钟,然后我们将其修改为10分钟,如下命令:
sysctl -w net.netfilter.nf_conntrack_tcp_timeout_unacknowledged=600问题不复现,怀疑此问题和此参数的设置有关系,因为我们在client开启了10个连接,但是只有个别的连接异常,不是所有的,为了进一步确认,我们将超时时间由5分钟修改为2分钟,如下命令:
sysctl -w net.netfilter.nf_conntrack_tcp_timeout_unacknowledged=120发现这10个连接都出现了异常,所以确定是nf_conntrack_tcp_timeout_unacknowledged的设置导致的。
分析代码此参数的功能:如果发送的报文携带了数据,那么此数据必须在nf_conntrack_tcp_timeout_unacknowledged时间内被ACK,也就是T4-T2<nf_conntrack_tcp_timeout_unacknowledged, 否则将此session从ct表中删除。
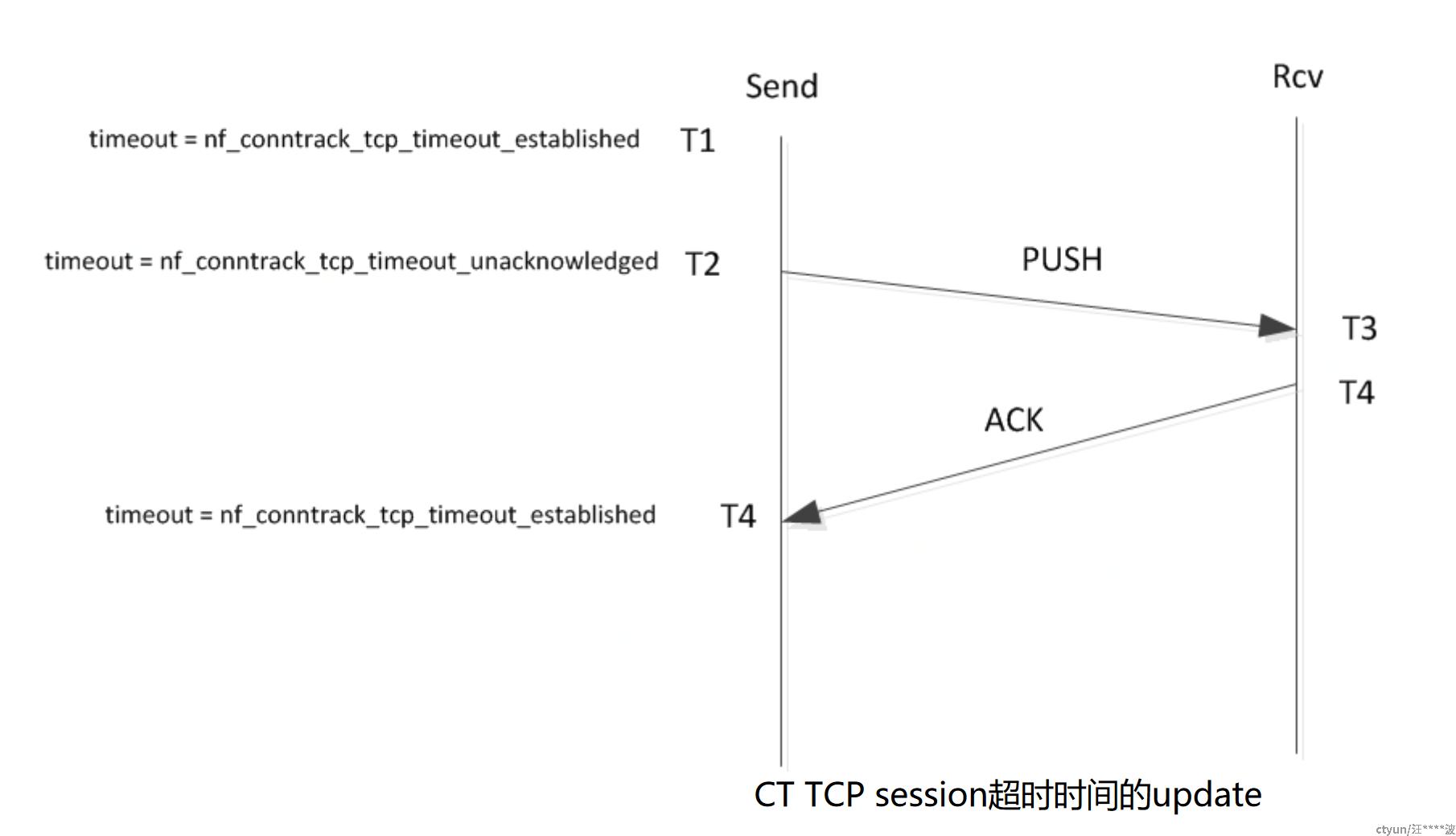
修改ct的超时时间
当current end sequence > last end sequence时,发送的时候设置IP_CT_TCP_FLAG_DATA_UNACKNOWLEDGED标记。
当current ack sequence == last end sequence时,接收的时候清除IP_CT_TCP_FLAG_DATA_UNACKNOWLEDGED此标记,
当设置了IP_CT_TCP_FLAG_DATA_UNACKNOWLEDGED标记后,ct的timeout更新为nf_conntrack_tcp_timeout_unacknowledged(默认5分钟)。
因为fin+ack的报文被drop了,而且redis发送的fin+ack距离上一个ack报文的时间间隔是5分钟,所以怀疑是redis发送的ack报文或是push+ack报文有问题,需要check这两种报文的sequence是否正确,然后将netfilter的pr_debug日志打开,如下:
PSH+ACK:
[2051865.254109] tcp_in_window: START
[2051865.254119] tcp_in_window:
[2051865.254119] seq=984687149 ack=57047932+(0) sack=57047932+(0) win=58
end=984687154
[2051865.254129] tcp_in_window: sender end=984687149 maxend=984716845
maxwin=29696 scale=9 receiver en #sender end > end, 配置send->flags
d=57047932 maxend=57077628 maxwin=29696 scale=9
[2051865.254138] tcp_in_window:
[2051865.254138] seq=984687149 ack=57047932+(0) sack=57047932+(0) win=58
end=984687154
[2051865.254147] tcp_in_window: sender end=984687149 maxend=984716845
maxwin=29696 scale=9 receiver en
d=57047932 maxend=57077628 maxwin=29696 scale=9
[2051865.254151] tcp_in_window: I=1 II=1 III=1 IV=1
[2051865.254161] tcp_in_window: res=1 sender end=984687154 maxend=984716845
maxwin=29696 receiver end=57047932 maxend=57077628 maxwin=29696
ACK:
[2051865.254414] tcp_in_window: START
[2051865.254426] tcp_in_window:
[2051865.254426] seq=57047932 ack=984687154+(0) sack=984687154+(0) win=58
end=57047938
[2051865.254436] tcp_in_window: sender end=57047932 maxend=57077628 maxwin=29696
scale=9 receiver end=984687154 maxend=984716845 maxwin=29696 scale=9 #receiver
end== ack, 清除receiver->flags, 同时sender end > end, 配置send->flags
[2051865.254451] tcp_in_window:
[2051865.254451] seq=57047932 ack=984687154+(0) sack=984687154+(0) win=58
end=57047938
[2051865.254464] tcp_in_window: sender end=57047932 maxend=57077628 maxwin=29696
scale=9 receiver end=984687154 maxend=984716845 maxwin=29696 scale=9
[2051865.254470] tcp_in_window: I=1 II=1 III=1 IV=1
[2051865.254483] tcp_in_window: res=1 sender end=57047938 maxend=57077628
maxwin=29696 receiver end=984687154 maxend=984716850 maxwin=29696在wrireshark里ack报文的seq为57047932,data len=0, 所以end = seq + data len= 57047932, 但是日志里end=57047938, data len= end - seq = 6, 多了6个字节的数据, 所以ct一直在等待此6字节的数据被ack,但实际上接收端不会发送此ack,直到5分钟到期,session被删除。

在ACK报文的二层头里边的padding的数据正好是6字节,怀疑是ct将此6字节的pading当数据处理了。
这里说一下当以太网报文的的长度小于64字节的时候,网卡会在二层报文的最后添加padding使报文的长度大于或等于64字节。
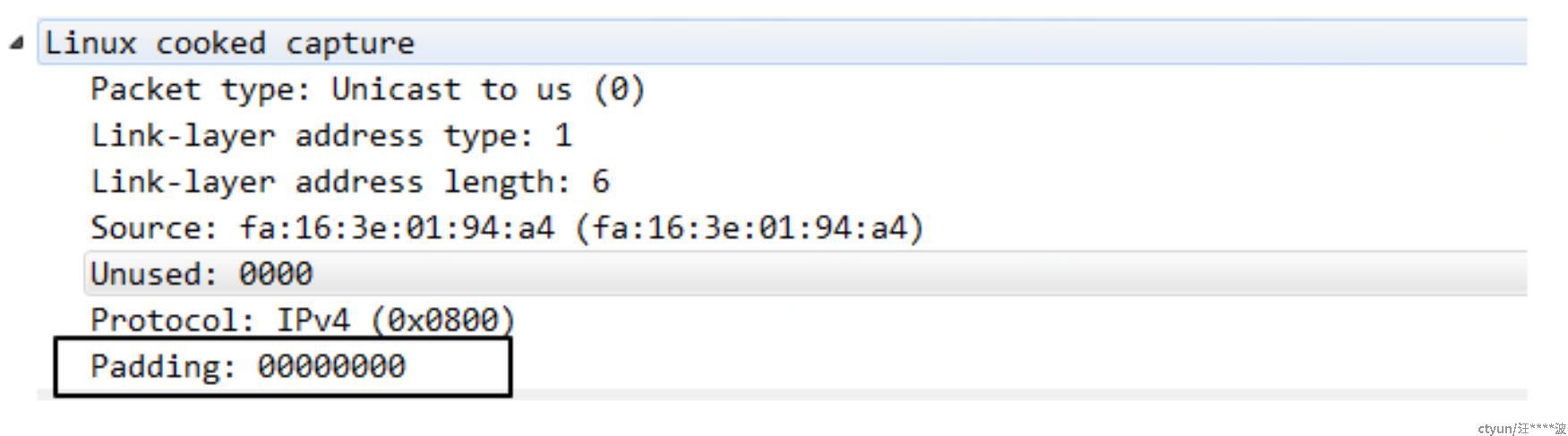
那ct为什么会将报文的padding作为数据呢,通过systemtap和review netfilter的代码发现,在ct在处理skb的时候,其skb->len是46,正确的值应该为40,然后继续分析skb->len,最后追溯到ovs的ovs_ct_execute()函数里
ovs提交给CT的skb->len为46,所以ct处理L3的报文,计算skb->len时并没有去掉padding的len,导致ct将pading作为数据了。
线上ovs的master代码,如下,已经去掉了paddingd的len了
函数ovs_skb_network_trim()计算去掉padding后的skb->len,至此问题已定位解决。
