


一、强化学习的发展
强化学习(reinforcement learning, RL)与监督学习和无监督学习并称为及其学习的3类方法,用于描述和解决智能体在与环境交互过程中通过学习动作策略以达成回报最大化或实现特定目标的问题。
20世纪60年代,强化学习已开始用于最优化控制领域,如赌博机问题、倒立摆问题等。起初用表格法记录模型信息,并在理论上能够收敛于最优策略,但其求解难度会因为任务复杂度增加而显著增大。
随着21世纪人工智能的再次兴起,深度学习(deep learning, DL)以其强大的函数表示能力与感知能力,为强化学习的实际应用带来重大突破。目前深度强化学习(deep reinforcement learning, DRL)利用深度学习作为函数逼近器,与强化学习的策略优化方法结合,使智能体可以在复杂任务中获得显著成果。其中,2015年Mnih等人使用DQN(deep Q-learning)算法,以与人类相同的像素观察条件,在49个街机游戏套件中以与人类相同的像素级别观察条件,经过2亿(200M)帧的交互训练,获得了超越人类得分水平的智能体,至此掀起了深度强化学习的广泛研究热潮。
二、强化学习的框架结构与符号表示
在强化学习领域中,通常将问题系统划分为环境和智能体两部分,通过二者的数据交互,完成强化学习问题的构建,以便应用具体算法,系统框架通常如图所示。
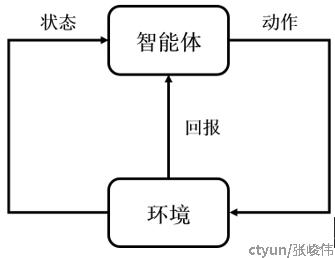
其中,智能体可以观察当前环境的状态State,并根据当前状态选择动作Action。智能体将动作作用与环境中后,会使得环境状态发生变化,并获得环境的奖励反馈Reward。智能体以最大化回合内奖励反馈Reward的总和为目标,寻找最优动作决策序列。
在强化学习问题符号表示中,通常使用马尔可夫决策过程(Markov decision process, MDP)来表示强化学习系统。所以强化学习系统需要首先满足马尔可夫性:P(S_{t+1}|S_t)=P(S_{t+1}|S_t,S_{t-1},...,S_1),即,随机过程在给定现在及所有过去状态情况下,其未来状态的条件概率分布仅依赖于当前状态。从直观的角度讲,在 t 时刻选择动作时,与 0~t-1 时刻的状态与动作无关,S_t 中包含了动作决策所需的全部信息。例如:在抛硬币问题中,已知前十次结果均为正面,那么第十一次的结果也只与硬币的质量、形状、投掷方式等物理特性有关,与十次的结果无关。
将强化学习问题建模为马尔可夫决策过程,由五元组<S,A,P,R,\gamma>表示,其中:


AlphaGo击败世界围棋冠军李世乭和柯洁,我们也根据围棋问题给出一个实际的例子:
- 智能体:在围棋问题中,需要求解最优的行棋方式,所以智能体维护一个策略函数,输入观察到的状态,并根据策略函数给出下棋的动作点位。
- 环境:在围棋问题中,假设智能体执黑子,对手执白字,那么期盼与对手就可以构成强化学习框架中的“环境”部分。
- 状态:可以使用当前棋盘中每个点的落子情况作为当前状态,如使用数组(Board [19][19])表示每个点位是否有黑子或白子。整体的落子情况包含了动作决策所需的全部信息,满足马尔可夫性。
- 动作:在当前状态下智能体执黑子落下的点位。
- 状态转移矩阵:当智能体落子在后,棋盘的变化情况,主要包含了对手行棋的概率分布。
- 奖励函数:智能体获胜后给予正向奖励1,落败后给予负向奖励-1,和棋为0

三、强化学习的特性
强化学习与监督学习和无监督学习间的差别较大,在此我们给出的特性:
1)知识来源:监督学习根据样本-标签对进行学习,无监督学习根据先验假设进行学习并需要验证,而强化学习的依据则主要是环境反馈的奖励。
2)试错:在强化学习任务中,智能体不会被告知应该采取哪个动作,而是需要通过执行动作后所产生的回报值来优化动作策略,智能体必须在试错中学习,所以强化学习需要大量的环境交互来进行采样,尝试获得具有更高回报奖励的样本,这也成为了强化学习问题求解开销大的原因之一。
3)延迟奖励:智能体的动作不仅可以影响到当前时刻所获得的回报值,还将通过对状态的改变影响到后续多个时刻的回报值,比如:在棋类问题中,可能只有胜负分晓的时候才能获得正向或负向的回报。所以需要同时考虑多个时刻的回报并将回报值向前传播。
4)探索与利用:智能体在训练过程中存在着探索与利用困境,需要在“利用已有的经验选择价值更高的动作”和“探索此前很少访问过的新颖状态”间进行抉择,因为未曾访问过的状态中,可能有着潜在价值更高的动作。
强化学习系统的框架结构,与人类在地球中的生活方式非常相似,这种探索与试错的模式,几乎能够表示出任何实际任务,DeepMind公司中负责AlphaGo项目的研究员David Silver声称: “GAI=RL+DL”, 认为结合了深度学习表示能力与强化学习推理能力的深度强化学习将会是人工智能的终极答案。但目前受限于求解强化学习的复杂度,强化学习方法在实际任务中的效果仍然有限。
