


MySQL SELECT语句的执行过程概述
词法分析(Lexical Analysis):
MySQL首先对输入的SQL语句进行词法分析。在这个过程中,SQL语句被拆分为一个个的词元(tokens)。词元是语句的最小单元,它们可以是关键字、标识符、运算符、常量等。例如,对于SELECT语句,词法分析器会将它拆分为"SELECT"、"column_name"、"FROM"、"table_name"等词元。
语法分析(Syntax Analysis):
在语法分析阶段,MySQL将根据语法规则检查词元的组合是否符合SQL语句的语法结构。如果语句合法,MySQL将生成一棵抽象语法树(AST),表示SQL语句的语法结构。如果出现语法错误,MySQL将返回相应的错误信息。
语义分析(Semantic Analysis):
在语义分析阶段,MySQL会对抽象语法树进行语义验证,包括表是否存在、列是否正确等。此阶段还包括解析表和列的别名、处理函数和聚合等操作。如果发现语义错误,MySQL将返回相应的错误信息。
查询优化(Query Optimization):
在查询优化阶段,MySQL会对解析后的查询进行优化。这包括选择最优的索引,决定连接顺序,以及使用其他优化技术来提高查询性能。MySQL会尝试找到最优的执行计划,以最小化执行查询的时间和资源消耗。
执行查询计划(Execution Plan):
一旦优化器选择了最优的执行计划,MySQL就会开始执行查询。这包括打开所需的表、应用过滤条件、执行连接操作和计算聚合函数等。如果查询涉及大量数据,MySQL可能还会使用临时表来处理数据。
结果返回
执行查询后,MySQL将把结果返回给客户端,客户端可以根据需要对结果进行处理和显示。
-
解析器分析
假设我们有一个名为"employees"的表,它包含了员工的信息,其中包含列:employee_id、first_name、last_name、department、salary。
如果语句为:
SELECT first_name, last_name, salary
FROM employees
WHERE department = 'IT';
词法分析
在这个阶段,MySQL会将输入的SQL语句拆分成不同的词元。对于这个SELECT语句,词法分析器会产生以下词元:
SELECT, first_name, comma, last_name, comma, salary, FROM, employees, WHERE, department, equal, 'IT', semicolon。
在分析过程中,词法分析器使用有限状态机(finite state machine)来确定每个词元的类型。有限状态机是一种抽象计算机,它在不同的状态之间转换,根据输入的字符来决定状态转换规则。主要的词法分析步骤如下:
- 跳过空白字符:词法分析器会跳过空格、制表符、换行符等不必要的空白字符。
- 识别关键字和标识符:词法分析器将识别出SELECT、FROM、WHERE等关键字,并将它们作为相应的词元类型。
- 识别运算符和标点符号:词法分析器将识别出逗号(comma)、等号(equal)、分号(semicolon)等运算符和标点符号,并将它们作为相应的词元类型。
- 识别常量:词法分析器将识别出'IT'作为一个字符串常量,并将其作为相应的词元类型。
- 识别数字:如果SQL语句中有数字,词法分析器也会将其识别为一个数字常量。
词法分析器在分析完一个词元后,将生成一个词元对象,其中包含词元的类型(关键字、标识符、运算符等)和对应的值(如果有的话)。对于输入SQL语句中的每个字符,词法分析器都会执行适当的状态转换,并生成相应的词元对象。
有限状态机(Finite State Machine,FSM)是一个重要的概念。FSM是一种数学模型,用于描述在输入串上从一个状态转换到另一个状态的过程。在词法分析中,每个词元都被看作是一种状态,并且FSM用于识别这些词元。
例如:语句SELECT first_name, last_name, salary FROM employees WHERE department='IT';
FSM的状态图
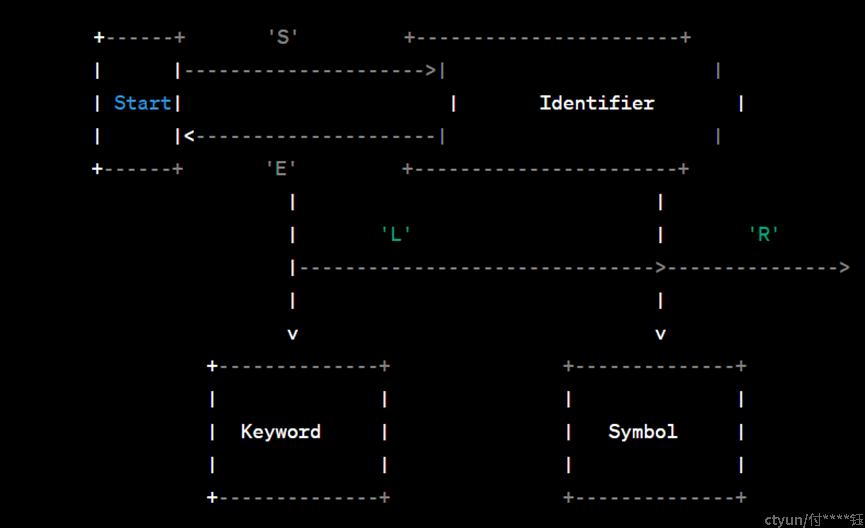
'S'代表开始状态,是FSM的初始状态。
'E'代表标识符状态,表示识别标识符(表名、列名等)。
'L'代表符号状态,表示识别分隔符(逗号、等号等)。
'R'代表结束状态,是FSM的接受状态,表示已识别出一个完整的词元。
重点关注两种词元:关键字(Keyword)和标识符(Identifier)。关键字词元包括:SELECT, FROM, WHERE。标识符词元包括:first_name, last_name, salary, employees, department,'IT'。初始状态是'S'(Start)。
FSM的识别过程
读取第一个字符'S':
由于'S'后面是'E'(End),且'SE'不匹配关键字或标识符,所以停留在'S'状态。
读取第二个字符'E':
由于'SE'不匹配关键字或标识符,所以仍然停留在'S'状态。
读取第三个字符'L':
由于'SEL'不匹配关键字或标识符,仍然停留在'S'状态。
读取第四个字符'E':
由于'SELE'不匹配关键字或标识符,仍然停留在'S'状态。
读取第五个字符'C':
由于'SELEC'不匹配关键字或标识符,仍然停留在'S'状态。
读取第六个字符'T':
由于'SELECT'匹配关键字,转换到'Keyword'状态。
读取第七个字符 ' '(空格):
由于空格后面是'E'(End),而'Keyword'状态是接受状态,所以停留在'Keyword' 状态,并识别出一个关键字"SELECT"。
继续读取字符,重复上述过程,识别出其余的关键字和标识。
语法解析
语法分析器根据MySQL的语法规则开始构建抽象语法树。
抽象语法树
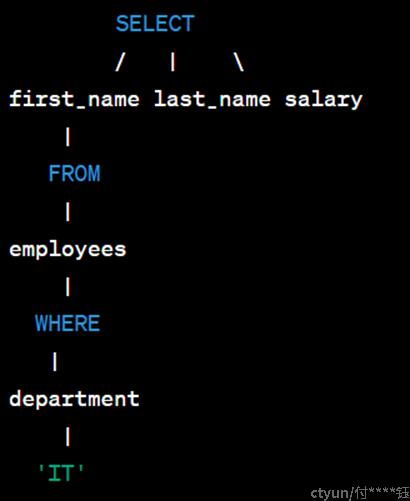
根节点是SELECT节点,它表示整个SELECT语句。SELECT节点的子节点是first_name、last_name和salary,表示SELECT子句中的列名。FROM节点的子节点是employees,表示FROM子句中的表名。WHERE节点的子节点是department和'IT',表示WHERE子句中的条件。
语义分析
首先检查对象存在性:语义分析器会检查查询涉及的表、列是否存在于数据库中。在示例中,语义分析器会验证employees表是否存在,以及其中的first_name、last_name、salary、department列是否存在。数据类型匹配:语义分析器会检查操作符的数据类型是否匹配。例如,在WHERE子句中,语义分析器会验证department列的数据类型是否与字符串'IT'匹配。表别名处理:如果查询使用了表别名,语义分析器会将表别名解析为对应的表名,以便后续处理。在示例中,FROM子句使用了表别名employees,语义分析器会将它解析为真实的表名。列解析:语义分析器会解析SELECT子句中的列名,以确定要查询哪些列。在示例中,语义分析器会解析first_name、last_name和salary列,并检查它们是否存在于目标表中。条件验证:语义分析器会验证WHERE子句中的条件是否正确。在示例中,语义分析器会验证department列是否存在,并检查它是否与字符串'IT'匹配。
通过语义分析,MySQL可以在执行查询之前对查询进行进一步的验证,确保数据的一致性和正确性。
后续需要结合源码,进一步分析mysql的解析细节。
