


什么是离线数据、实时数据?
简而言之 这个数据出来后 跟当前时间延迟。延迟大的就是离线数据,延迟小就是实时数据,一般而言分钟以内才可以认为是实时/(当天)准实时数据,否认是离线数据。数据从产生,到分析处理到赋能反哺业务,都得需要经过一系列的清洗、处理入库,而经过这一处理过程是实时的还是滞后的,也就是处理数据的时效性。按照处理延迟的大小,可以将数据分为离线数据和以及实时数据(准实时)。
1. 离线数据
离线数据一般是指T-1的日期,例如今天的日期T=2023-7-27,那么数据结果中,能够体现的业务数据只包括前一天的(昨日数据)。都是指的今天处理的数据最新日期是截止昨天。
2. 实时数据
实时数据主要是指的数据延迟小,例如毫秒、秒、分钟级的延迟,当天的小时级的延迟一般叫“准实时数据“更为准确了,当下你在app可以看到外卖员的实时位置
什么是实时处理和离线处理?
1、离线数据处理
离线处理一般称为批处理,即数据产生之后,不会立即进行清洗,而是在固定的周期进行调度处理,一般是凌晨深夜处理前一天产生的数据。比如我们把几天的衣服攒了几天后再一次性洗,这就是离线处理的思想,离线处理一直以来都是非常成熟稳定,具备海量大批量的数据处理,一直是最可靠保证的兜底方式,不过有个缺点就是延迟大,一般隔天延迟,目前常用技术是hive,MapReduce,spark,数据存放在hdfs
2、实时数据处理
由于离线数据处理的劣势就是延迟大、而且如今对实时场景越来越多,一些离线数据处理已无法满足、远古需要实时,是通过不断的轮询达到实时的效果,后面新技术衍生,通过了spark Streaming,对于大部分公司是足以满足和应付了、不过毕竟还是属于准实时、通过调低频次达到准实时,但非真正的实时处理,还是属于微批方式即批处理、实时技术storm,flink是真正的实时流方式,如今storm基本没用了、业内都使用flink作为实时计算引擎,其实flink是流批一体引擎,既可以做批处理也可以做实时处理,这也为当下流批一体提供了技术支持。
3、FLINK 123
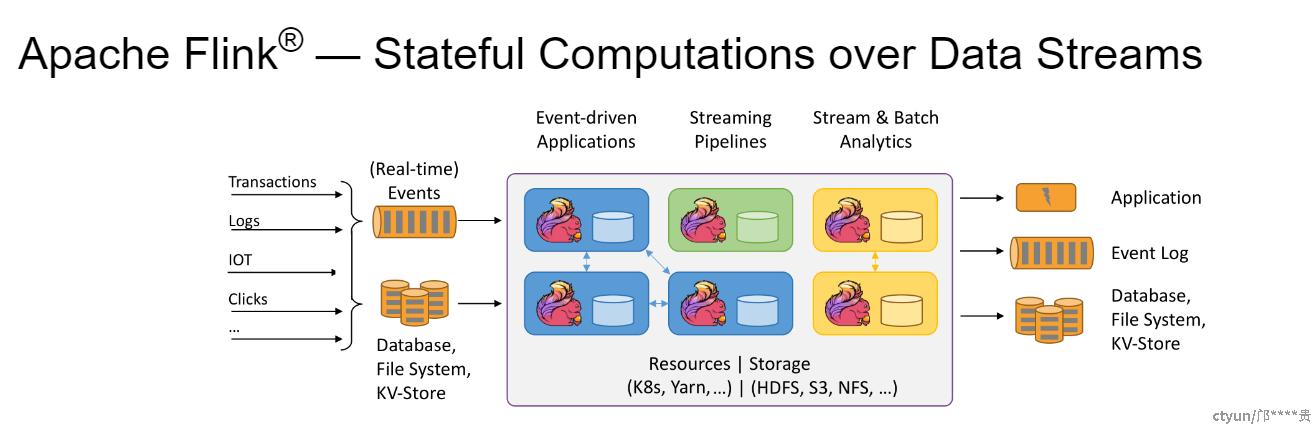
1、flink的checkpoint和savapoint
savepoint是手动的checkpoint,flink是有状态计算、通过定时checkpoint来达到保存检查点目的、即使故障挂掉重启,也可以通过上一次的checkpoint进行恢复,不至于数据处理丢失
2、flink的背压
当整条链路上 有一个算子处理性能慢、导致处理跟不上消费的速度、这时候flink会正常运行、并且会通过一级一级自下往上进行背压、直至背压到消费source端
3、flink的数据一致性
任何数据处理框架都要面对这个数据仅有一次,至少一次,至多一次的场景选择,flink 完美支持仅有一次,flink通过state 有状态计算和checkpointd定时保存快照机制来实现数据 Exactly-once。
4、时间语义
flink支持两个时间语义 process time和event time,但其实还有一个 ingest time,一般而言数据的时间则是使用event time,也就是说处理的数据有自己的时间,使用数据自带的时间,反之是process time
5、水位
水位一般用于窗口计算和支持数据延迟的情况,因为我们处理数据的过程中,有些数据可能会晚点时间到达、通过设置水位来到支持。
