背景
不管有没有大数据技术兴起,各个企业的每日内部数据采集处理等一整套的业务需求是一直都在的,只是各个公司处理方式五花八门,小的开发人员自己手动写脚步数据摄取,sql清洗,sql处理等等,数据量不多,研发负责搞定一条龙,大点的会成立对应小组,按照数据领域划分,各司其职。自大数据兴起后,公司一般会成立大数据组织架构。
成立新组织架构
自从大数据新起,很多公司就招募或者内部转型去大数据开发人员,大多数是会成立大数据相关的新部门专门攻坚负责这块,而大数据技术和生态也是比较广,从早期的采集、存储,处理,查询等几大模块,如今这几个大模块已垂直纵向延伸快速迭代各种新的技术。
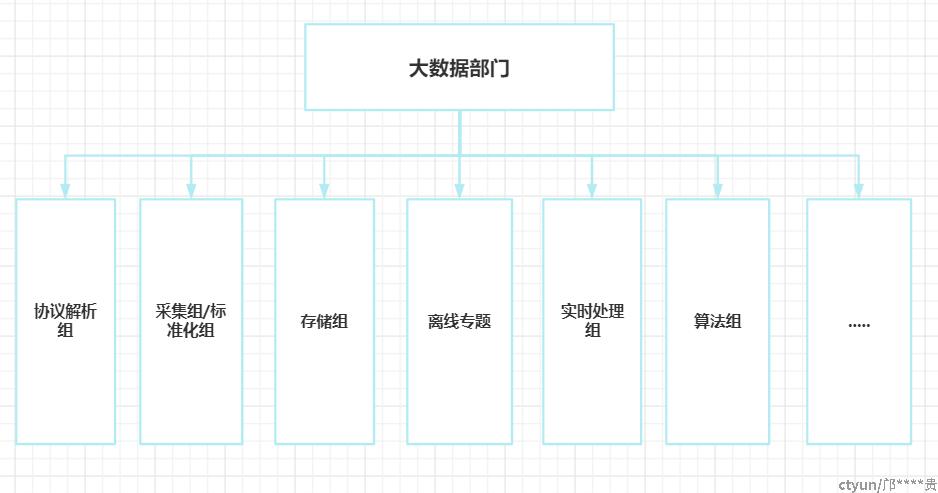
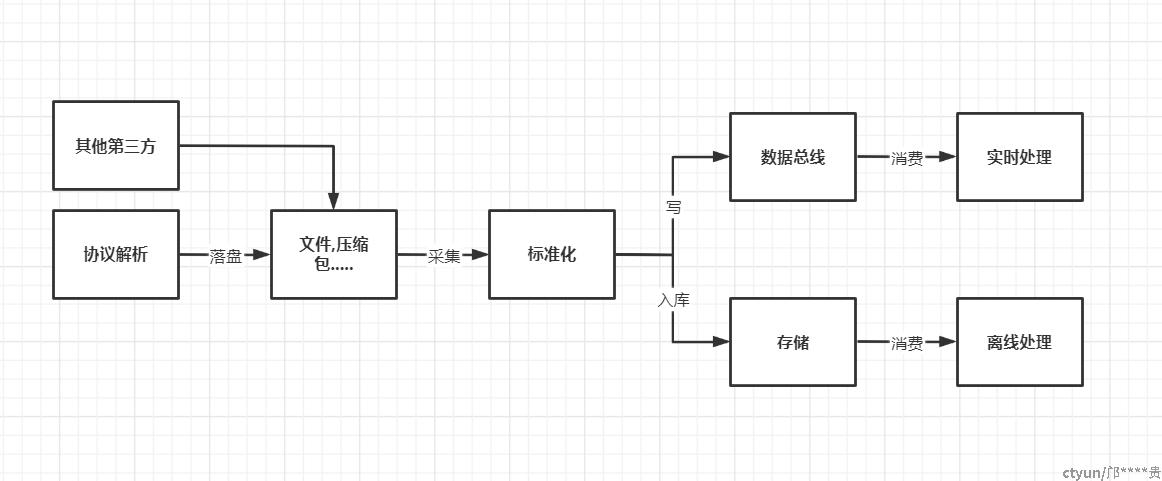
协议解析组:大部分公司可能比较少涉及,因为这块主要是网关层里面解析数据包然后进行落盘为下一步采集使用
采集组/标准化组:通过采集协议解析落盘文件,或者去到数据所在机器落地的文件或者压缩包,采集读取数据,进行统一的格转,按照公司统一标准对各类数据进行标准化并写入公司数据总线层和存储层
存储组:存储主要负责应对业务负责数据如何存储,如何查等问题,如支撑业务需要定义如何建索引,并提供数据查询服务,一般引入诸如ES,HBASE,图数据库等,为上层其他大数据技术提供数据原料和支撑业务应用
离线专题:简而言之其实就是现在的数仓, 一般使用hive,spark对数据进行清洗处理形成对应专题, 构建数据仓库,形成公司数据资产
实时处理:实时处理主要是解决离线专题不够实时而存在的,离线专题相关数据处理都可以变为实时去承接业务使用,绝大都多数公司用spark即可满足,也就是说 大部分公司并不会成立这个实时处理小组,因为场景少,需求不多一般由离线专题里面内部承接
算法组:这个是新兴的,算法里面其实也细分很多,文本挖掘,语音,图像处理,机器学习,数据分析,AI 等等,里面都可以细分拆出多个小组。
当然远不止上面这些,大公司有实力的会细分很多衍生出其他小组,主流的大概是上面
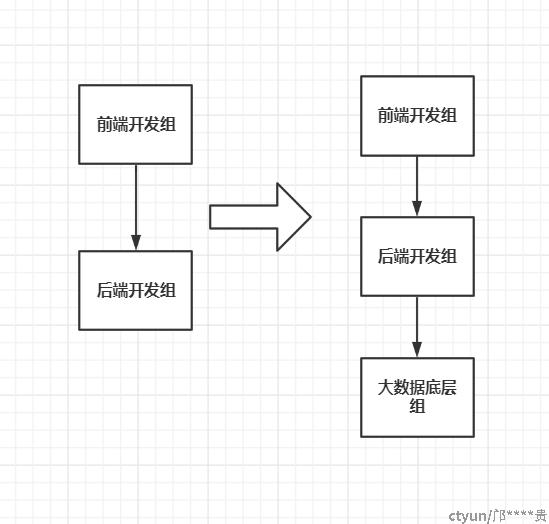
公司产品/系统研发层面的演变
由于数据相关这块已经交由大数据负责管辖,故公司相关产品研发或者项目研发的流程就得带上大数据,以前后端可以直接从一些存储直连获取数据,诸如结构性数据库mysql等,如今就得对接大数据相关小组研发去请求获取数据,大数据底层数据是不允许非底层人员直连的。因此一般有三层研发来共同完成项目或者产品
大数据各组提供业务的支撑方式:
1、API接口服务去支撑后端数据需求
2、大数据直接把业务需要的数据写入后端业务数据存储,由后端使用
通过使用获取大数据处理后的数据,直接赋能给公司产品/系统使用,那么公司产品/系统就可以称为大数据产品了或者大数据平台了去叫卖了,直接高大尚。
新的企业内部数据流
根据内部数据流程也就对应上大数据组织架构分组,在数据领域各司其职互相协助一环依赖一环,职责分明,流转清晰才保证底层数据每日正常运作,先进来,用起来,然后沉淀起来,最后支撑上层各类使用,如下是目前绝大部分公司先行运作的数据流,也称为lambda架构,当然如今新的架构也早已经有了,但是真正去使用新架构的和切换为新架构的不多。