


背景:
在传统场景应用中,需要获取场景数据,并进行人工标记,和模型训练,最终输出的是训练好的初版模型及演示demo等。可以先看下相关案例:

牛奶奶瓶及瓶盖检测识别
步骤:
1.传统场景视频获取,视频切分,存储。
2.需要检测的物体分类,边界确认及标注。
3格式文件整理并进行模型训练,查看模型效果,并进行基础的demo制作等。
存在问题
整个过程中花费时间最多的,主要集中在前期检测物体的确定及以边框边界确认,中期人员的标注成本,而且随着数据增多,本身花费的标注时间线性增长,在文件各个环节拷贝存储以及制作标签格式过程中,时间成本巨大,加上人员在训练过程中的认知成本,及demo制作成本,导致整个开发过程可能达到2周或者更多。
解决方法:
如何解决上述问题,涉及到流程优化及技术迭代,从流程上来讲,需要存储1处,打标需要模板标准和描述。这里不展开。从技术迭代来讲,主要替换或者优化的是人员标记。
人员标注:人员标注是典型的劳动力密集型产业,需要针对图片中的检测物,使用鼠标进行密集画点或者拖拽框图,以形成模型训练所需要的各种检测物体正样本,样本数据越多,数据分布相对越完整,得到的最终训练模型效果从精度鲁棒性都更好。
但是人员成本以及不断的标注,对人身心都是极大考验,重复的标注更多的是时间浪费,而成果仅仅是某个项目的数据标注,后续可能因为各种原因项目难以成行,同时这种重复的标注难以提升标注人员的本身技能,需要具备更高的视野,这些标注人员才能更好的负责整个数据标注工作,才有可能输出更高质量的数据标注成果。同时针对上层人员,标注所花费的时间,以及标注错误,重新迭代的成本是巨大的,可能会直接导致产品竞争力,时效性直线下降。
而恰恰是科技的发展,替代了一部分低创造力的工作,对于人员较少时候,这种工具和模型的出现是对生产效率提升巨大,当人员较多时候,需要兼顾就业率等。
大模型从ChatGpt出现之后,吸引了一大波关注,普通人在使用后也获得了非常好的使用体验。从本质上讲,chatgpt是把人类的历史知识通过文本话的形式进行大模型训练,因此人可以询问任何问题,并且得到大数据的支撑,通过炼金得到的相对完整且全面的回答。其网络本身黑盒,因此类人脑,得到的结果可能正面,可能负面,需要一定监管。后续针对cv领域,诞生了相关生成类图片和视频模型方法,但是这些更多关注的是创造力,和视觉设计。
本文将要介绍的,则是大模型生产力方面的相关工作,autodistill
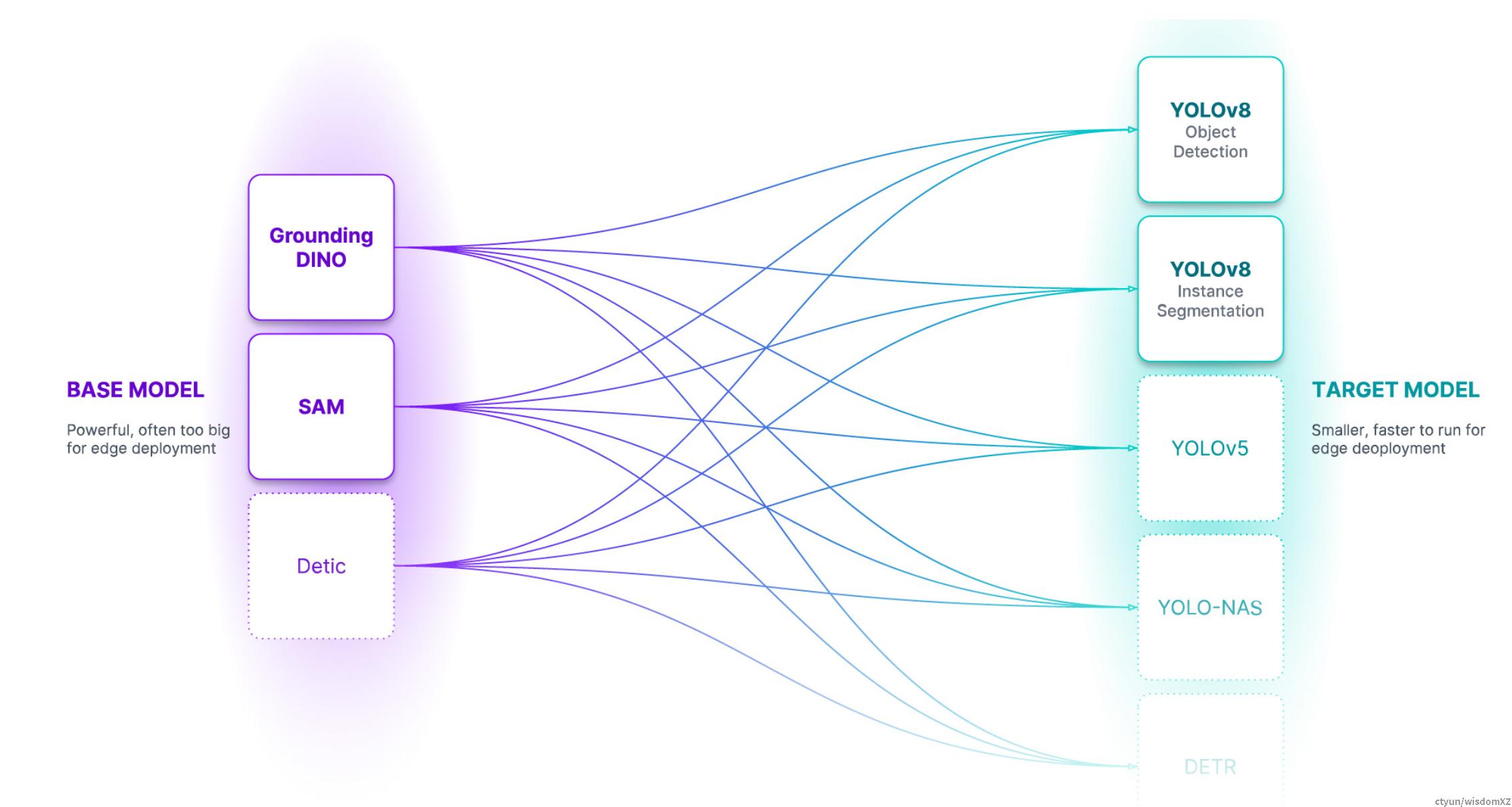
其核心思想是借助已有的大模型如Dino和SAM进行自然语言交互式的标注,这个好处是不断迭代的大模型可以通过代码更新的方式不断加入到当前项目中,这里使用自然语言交互,可以给出检测物更详细的标注确认,如果像传统模型仅仅给出一个类别名称,会造成不同数据集上的歧义,反而使用可以任意长度的,可以包含详细信息的自然语言可以更准确确认,同时给这个描述一个类别名称,兼顾了传统数据标注模式和训练模式。

上图为使用大模型标注的图片,可以看到针对瓶身,进行了非常精准的标注,这主要得益于SAM模型惊人的效果,当前无监督的检测识别精度还处于中等水平,但是无监督分割大模型SAM效果惊人,分割精准,从上图也可以看出分割效果非常好。这里隐藏着一个迭代问题,即描述的精确程度决定了检测的错误和精确,因此针对常见常见的常见物体标注相对准确,但是对于一些特殊行业场景,检测识别效果会降低较多,同时描述的精确与否,也会一定程度上需要交互迭代才能确认,但是相对于人工标注的速度和精度,大模型从生产效率上已经超越。并且随着不断迭代,可以提升速度和精度,但是人在重复标注过程中的上限却已经确定。
生成的标注文件,可以借助已有的yolo框架或者mmdetection框架直接训练,得到初始的基础模型,和演示demo等。

这里可以优化的点集中在大模型检测,可以通过确定性的阈值来进行少量自标注进行模型训练,得到更精准的小模型训练数据,或者在大模型标注完成后,进行人工检查,这样标注人员做的工作更集中在核心检查与客户需求侧,个人能力也会提升。
