


2023年5月19日,微软发表了发布了可组合扩散(Composable Diffusion,CoDi)及相关论文,能够从任意输入模态的任意组合中生成语言、图像、视频或音频等任意组合的输出模态。
论文地址:https://arxiv.org/abs/2305.11846
代码地址:https://github.com/microsoft/i-Code/tree/main/i-Code-V3
背景:
提出了可组合扩散(Composable Diffusion,CoDi),这是一种新颖的生成模型,能够从任意输入模态的任意组合中生成语言、图像、视频或音频等任意组合的输出模态。与现有的生成人工智能系统不同,CoDi能够并行生成多个模态,并且其输入不仅限于文本或图像等模态子集。尽管许多模态组合缺乏训练数据集,但我们提出在输入和输出空间中对模态进行对齐。这使得CoDi能够自由地在任何输入组合上进行条件生成,并生成任何一组模态,即使它们在训练数据中不存在。CoDi采用一种新颖的可组合生成策略,通过在扩散过程中建立共享的多模态空间来进行对齐,从而实现交织模态的同步生成,例如时间上对齐的视频和音频。高度可定制和灵活的CoDi实现了强大的联合模态生成质量,并且在单模态合成方面优于或与最先进的单模态技术相媲美。
引言:
训练一个模型以接受任何混合输入模态并灵活生成任何混合输出模态具有重要的计算和数据需求,因为输入和输出模态的组合数呈指数级增长。此外,对于许多模态组合,缺乏对齐的训练数据,甚至可能根本不存在,使得无法对所有可能的输入-输出组合进行训练。为了解决这个挑战,我们提出在输入条件(第3.2节)和生成扩散步骤(第3.4节)中对多模态进行对齐。此外,我们提出了一种“桥接对齐”策略用于对比学习(第3.2节),可以用线性数量的训练目标高效地对指数数量的输入-输出组合进行建模。
构建具有任意到任意生成能力和出色生成质量的模型需要全面的模型设计和对多样化数据资源的训练。因此,我们以一种综合的方式构建CoDi。首先,我们为每种模态(例如文本、图像、视频和音频)训练一个潜变扩散模型(Latent Diffusion Model,LDM)。这些模型可以独立并行训练,利用广泛可用的特定模态训练数据(即具有一个或多个模态作为输入和一个模态作为输出的数据)确保出色的单模态生成质量。对于条件跨模态生成,例如使用音频+语言提示生成图像,输入模态被投影到共享特征空间(第3.2节),输出LDM关注输入特征的组合。这种多模态条件机制使得扩散模型能够在不直接训练这些设置的情况下以任何模态或模态组合进行条件生成。
训练的第二阶段使模型能够处理多对多的生成策略,涉及同时生成任意组合的输出模态。据我们所知,CoDi是第一个具有这种能力的人工智能模型。这是通过为每个扩散器添加交叉注意力模块和一个环境编码器V来实现的,将不同LDM的潜变量投影到共享的潜空间(第3.4节)。接下来,我们固定LDM的参数,只训练交叉注意力参数和V。由于不同模态的环境编码器是对齐的,LDM可以通过插值表示的V与任何组合的共同生成模态进行交叉注意力。这使得CoDi能够无缝地生成任何模态组合,而无需对所有可能的生成组合进行训练。这将训练目标的数量从指数级降低到线性级。
我们展示了CoDi的任意到任意生成能力,包括单模态生成、多条件生成以及多模态联合生成的新能力。例如,根据文本输入提示生成同步的视频和音频;或根据提示图像和音频生成视频。我们还使用八个多模态数据集对CoDi进行了定量评估。CoDi在各种场景中展现出优秀的生成质量,合成质量与单一到单一模态的SOTA相当甚至更好,例如音频生成和音频字幕。
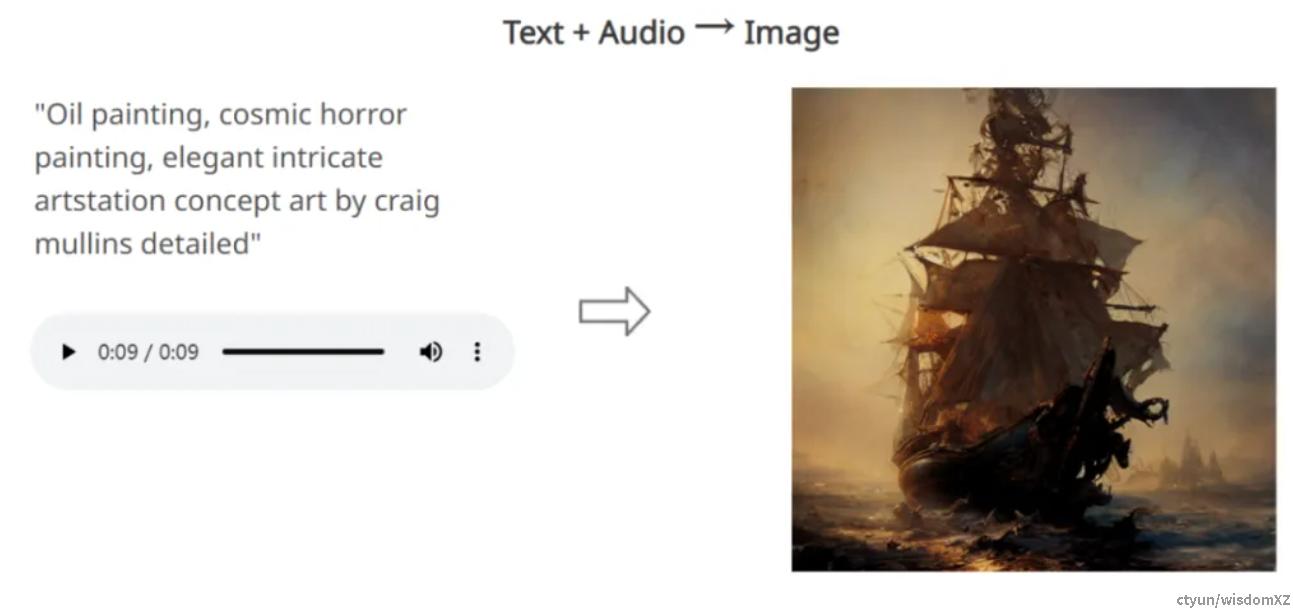
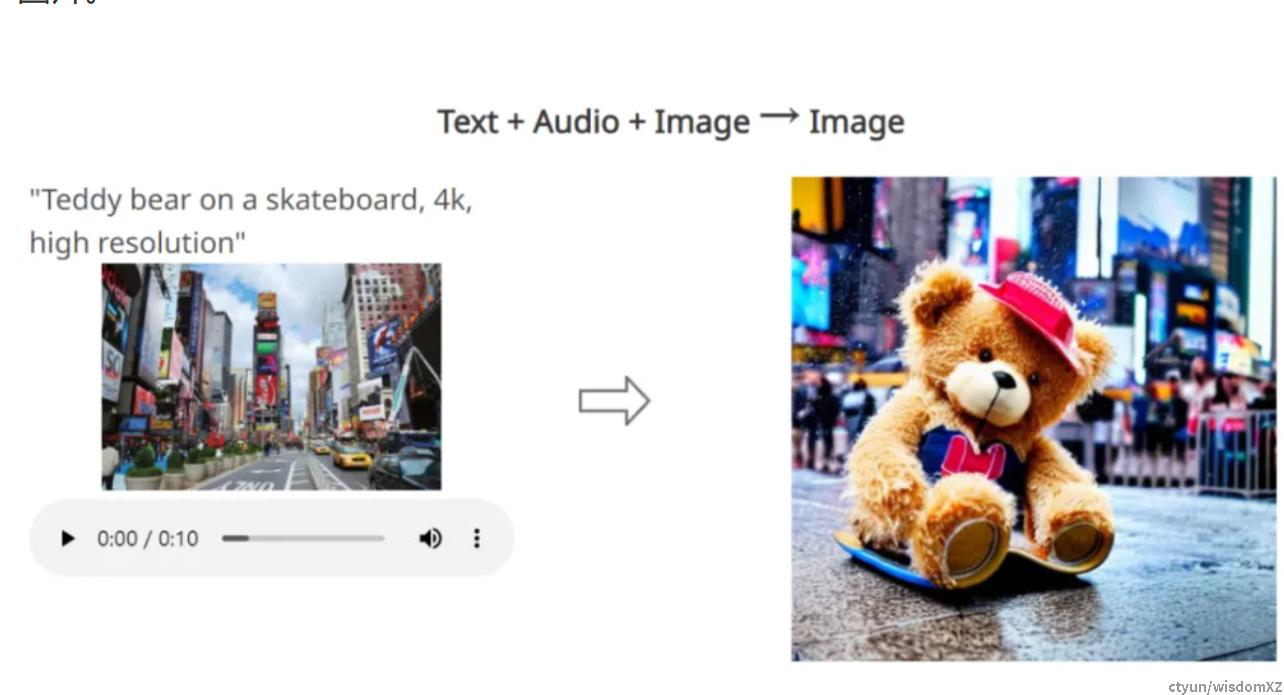
技术架构
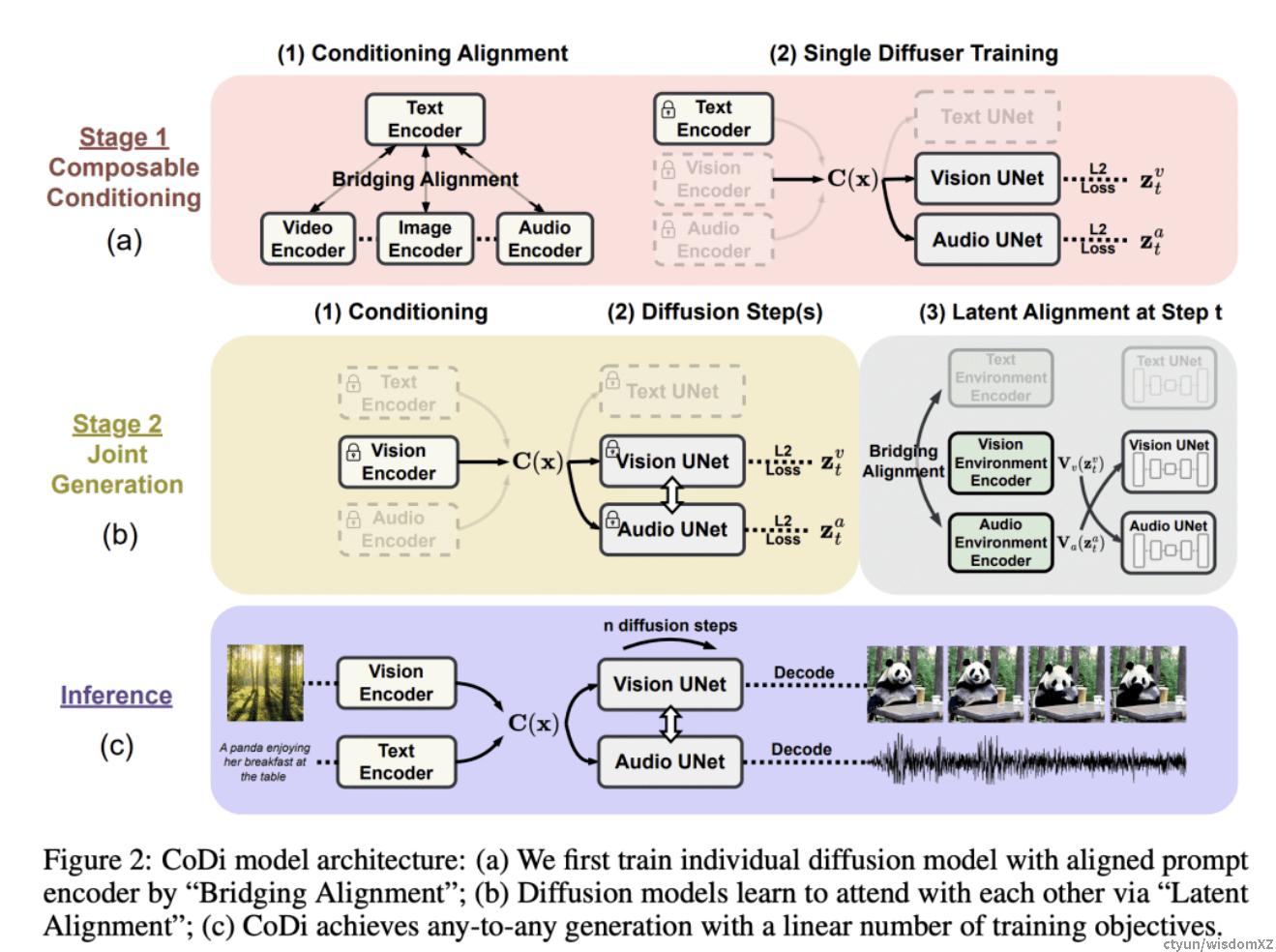
-
CoDi采用一种新的可组合生成策略,通过在扩散过程中建立共享的多模态空间,实现模态之间的对齐,从而实现模态的同步生成。CoDi在生成过程中能高度定制和灵活,实现了强大的联合模态生成质量,并且在单模态合成方面优于或与最先进的单模态合成方法持平。 -
优势:CoDi是一种创新的多模态生成模型,能从各种输入模态中同时处理和生成多种模态(包括文本、图像、视频和音频)。通过对齐模态空间,能自由地生成各种组合的输出模态,具有高质量和连贯性。
多模态大模型的最终形态应该和具身智能相关,也是机器人理解复杂场景的技术路径之一,类比人的视觉输入,理解,分析和操作,正是像ChatGPT等单模型不断前进的方向。我们相信后续会有越来越多的多模态大模型,不断进行技术迭代,达到越过图灵测试的能力。
