


1 存储网络模型
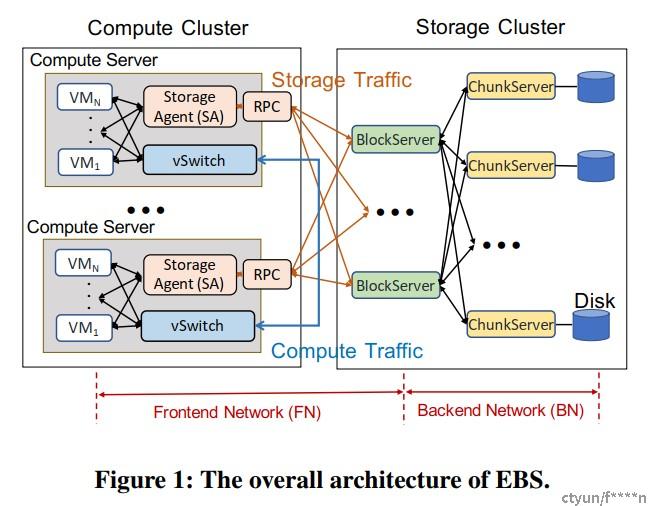
前端网络:the frontend network (FN) :连接计算节点和存储节点。需要注意的是前端computer server的数量可能非常巨大,在10K-100K规模。
后端网络:the backend network (BN) :存储集群内部的fabric互联网,连接block server 和 chunk server。存储集群的规模一般不会很大,节点数多在100以内。
Storage agent(SA)负责向VM呈现具体的磁盘,比如virtio block盘或者nvme盘。SA从VM里虚拟化的磁盘接收读写IO命令,再将其转化为网络协议层的消息传输至Block server,这里网络协议层的消息可能是一个RPC,或者是nvme over fabric协议,或者是自定义的传输层协议。Block server负责向SA呈现block device虚拟化的云盘,block server会根据消息里的原数据选择将磁盘IO的payload具体写入哪个nvme SSD磁盘,因此SA不需要知道BDEV具体的落盘信息。磁盘IO最终落盘的位置是chunk server,这是SSD真正挂载的位置。
2 存储网络传输层设计的考量
2.1 性能
- 存储网络的IOPS性能需求根据产品规格的不同在50w-100w区间, 未来可能会演进至500w IOPS。
- 存储网络的throughput吞吐量性能需求有50Gbps和100Gbps两档,未来可能会演进至200Gbps。
- 存储网络的空载时延latency性能需求根据产品规格的不同在100us-500us区间,未来可能会演进至50us。
2.2 资源消耗
- Storage agent需要占用的CPU core数量是一个关键的考量点:如果SA部署在host上则会降低host的CPU售卖比,越多的核给SA用则用于售卖的VM越少。特别是当存储网络带宽越来越大时需要消耗的host CPU core会越来越多。而当SA部署在DPU SOC上时,由于能耗的限制DPU SOC上的CPU core数量不会达到像host那样多,一般会限制在8-20个左右,这里面还有部分要留给操作系统和VPC虚拟网络,因此留给存储网络SA的核数是非常有限的,一般在5-10个左右。且由于DPU SOC上的CPU 核一般要弱于host上的CPU核,因此其算力是要打折扣的。
- Storage agent需要维护大量的长时连接,这些连接需要消耗的内存容量也是一个重要的考量点。存储一般进行的是大数据的搬移,最小的消息是4KB,最大的可能是2MB。考虑1K连接数,每个连接4K的接收队列深度,每个接收缓冲区16KB的大小,这可能会消耗64GB内存。在host上内存也是一种可售卖资源,而在DPU上内存虽然不影响售卖但却是有限的。太多的内存消耗可能导致SA无法支持大规模部署。
- 即使内存的容量不是问题,内存带宽墙也可能会成为限制。当前典型的DDR4的带宽在200Gbps-1Tbps区间,考虑到有多种硬件包括CPU都在访问DDR,storage agent能够占用的内存带宽是有限的,可能会不到总带宽的1/4,这在存储网络达到200Gbps时代时就会成为瓶颈。
- CPU核数,内存容量,网络带宽随着时间推移都在线性增长,但是PCIE带宽的增长速度要慢得多,这逐渐成为了系统互联的性能瓶颈点。典型的PCIE4 单条LANE的带宽在2GB,一个PCIE6x16的总带宽为256Gbps。考虑到PCIE BUS上设备众多,且有些设备存在双向传输,一个不好的系统架构设计可能会导致storage agent能利用的PCIE带宽不到100Gbps。
- SA处理存储IO一般采用PMD busy polling模式,这会让CPU始终处于最高功耗状态,所以SA占用的核数越多时整个系统的能耗也会越高。另一个考量点是智能网卡的架构选择:NP架构,FPGA架构,ASIC架构。其中FPGA架构的功耗最大,而智能网卡受限于PCIE供电的限制最大能耗为75W,否则就需要独立供电。
2.3 Reliability
- 出于网络健壮性的考虑,我们一般需要在计算节点和存储节点构建多条通路,这意味着存储传输层需要支持multi-path,即将其流量distribute到多个通路上到达对端。这里一个常见的问题是乱序问题,一般来说我们需要将一个flow的流量沿着相同的网络路径投递至目的端,否则就可能出现先后发出的报文在接收侧被乱序接收。
- 当网络多路径出现时一个自然的问题是failover即故障恢复,对于存储网络来说,需要做到毫秒级的故障网络路径切换才能让终端用户无感。
- 存储网络在可靠性方面的另一个强需求是数据一致性保证,要求数据在网络传输过程中不能被篡改。存储传输层一般通过在报文中附带CRC来检验数据一致性。这里的问题是存储的数据一般在4KB-1MB之间,如果靠CPU软件去计算和验证CRC将是一个非常耗时的操作。需要将CRC的计算和校验卸载给硬件。
2.4 Scalability
- 在当前的网络架构里存储集群和计算集群是分离部署的,存储集群的规模规较小(10-100个存储服务器节点),而计算集群规模可以很大(10K-100K个计算节点)。可扩展性指的是我们的存储前端网络可以采用scale-out的方式增加计算节点和存储节点横向扩展以支持更大的网络规模。scalability首先的问题是存储前后端所消耗的资源是否会随着网络规模扩大而不断增加,比如我们是否要增加更多的CPU core,消耗更多的memory,如果答案是yes那么我们的存储网络就不具备scalability。随着时间的推移网络规模越来越大是必然的但留给存储网络的资源总是有限的。
- 可扩展性里一个常见的limitation是connection的数量。 如果10K个SA和100个block server的10个线程间都需要维护full mesh的长时TCP连接,即使每个连接只需要4MB的收发缓冲区,那么在每个block server上也需要维护100K的连接,消耗400GB内存,这在一般的服务器上是不可接受的。
2.5 Compatibility
- 数据中心的网络会采用多个厂家多个规格的服务器,所以从兼容性上考虑我们要保证存储传输层可以在各种服务器上运行起来。首先从CPU架构上考虑就是要同时兼容X86和ARM这2种主流CPU架构。 驱动是否能在特定架构的OS上运行,是否有用到特定架构的指令,不同架构下是否有数据面的性能差异,这些都是架构兼容性需要考虑的问题。
- 除了CPU就是我们用到的网卡,不仅是一般的网卡还包含具备IAAS卸载功能的DPU网卡。网卡兼容性是指尽量使用大多数网卡都具备的功能,而不去绑定特定厂商的特定feature。即使日后使用自研DPU卡,我们也要小心的分离功能性设计和性能设计,我们可以说在自研DPU卡上性能更好,但也要保证在降低性能后完整的功能在商用DPU卡上也能跑起来。一般来说商用卡由于量产规模大价格更便宜,而自研DPU卡价格贵但因为有业务针对性的设计性能更好。
- 存储传输层的设计不仅是追求当前性能最优还要保证以后在硬件架构升级的情况下还能随着新架构一起提升性能。这里可能的一种未来趋势是P4可编程硬件。
- 尽管TCP/RDMA这一类的协议要求各个厂家兼容同一套标准,但是现实中不同厂家的协议对接时还是有各种问题:比如intel E810的RDMA网卡在receive buffer耗尽时不会发送RNR而只是timeout,这与Nvidia CX6网卡的行为就不一致。即使相同厂家的不同版本的网卡也会有兼容性问题,比如Nvidia 的CX4和CX5/6在RDM协议上就无法对接。协议兼容性问题也会限制网络的部署。
3 存储IO流程
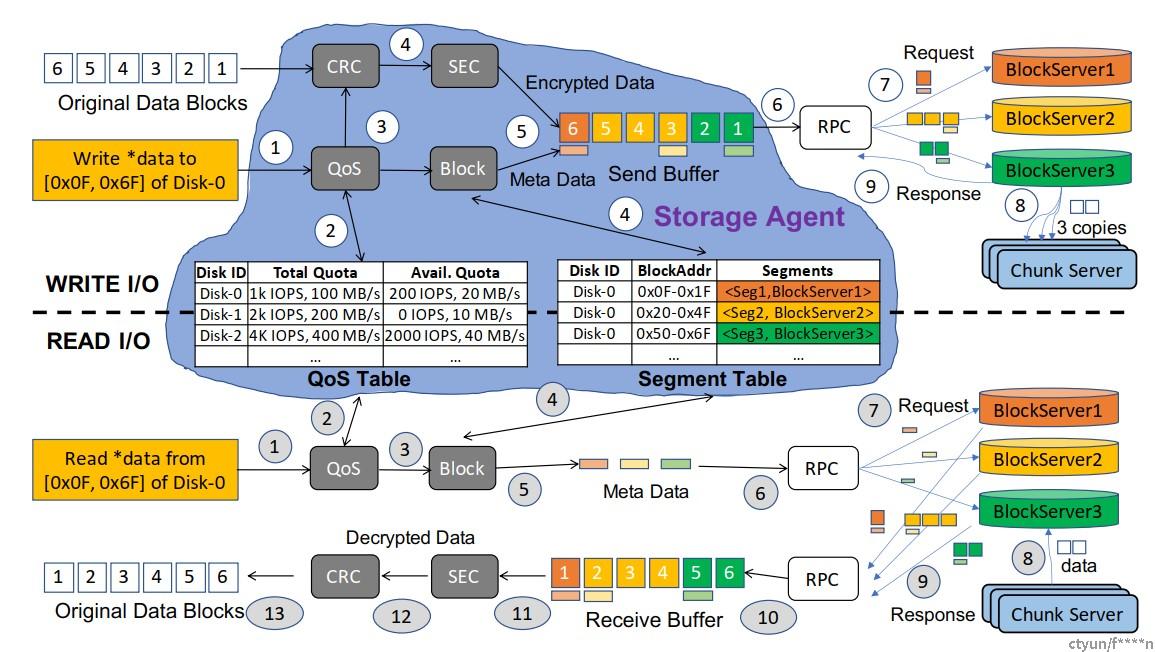
SA维护两个表:(1)Segment表,跟踪虚拟磁盘(VD)上数据块地址与物理磁盘和存储集群中相应数据片段的映射,是实现虚拟化存储的核心数据结构;(2)QoS表维护每个虚拟磁盘的服务级别(SL)和当前使用情况,通过带宽和IOPS进行衡量。每个I/O请求都会在数据平面遍历QoS和Segment表,这些条目是通过存储管理平面填充的。
Write IO(图上半部分):收到来自客户操作系统的写入请求后,SA检查Segment表(步骤4)以查找要写入的数据块的片段和托管块服务器,然后调用RPC一次或多次(步骤7)将可选加密的数据和元数据传输到存储集群中的块服务器。块服务器将数据写入拥有多个副本(例如3个)的块服务器(步骤8),然后确认写入成功并将其通知给SA(步骤9)。
Read IO(图下半部分):读取操作遵循类似的过程,但比写入操作具有更多的步骤。请注意,所有数据都被分成原子单元 - 数据块,其大小为4K字节,以与SSD的扇区大小保持一致 - 并且SA中的所有操作都是以块为单位进行的,RPC可能会在一个传输中组合多个块。因此,在块传输中延迟时间至关重要,因为任何落后者都会推迟整个I/O的完成。
4 路线1:用户态TCP
采用此技术路线的有阿里云LUNA,天翼云ESAR。

4.1 为什么不是kernel TCP ?
Kernel TCP需要进行用户态/内核态上下文切换,需要将数据从用户态copy至内核态,CPU需要处理大量协议栈细节,总体时延高至上百微秒。
4.2 为什么不是RDMA ?
Scalability考量:FN需要维护大量的连接,且要支持跨AZ的流量。RDMA的卡上资源并不支持大量连接,并且当连接数变大时性能会显著下降。而当RDMA跨AZ通信时又会遭遇不可控的网络拥塞问题(PFC风暴和死锁)。
Interoperability考量:BN是自成一体一次性建设成的,所以BN里的服务器配置一般是一致的。但是FN一般是增量建设的,新老服务器的配置会有较大差异,比如老的服务器可能没有RDMA网卡。目前的RDMA网卡只支持同厂家互联。

4.3 用户态TCP的关键设计点
- RTC :采用PMD轮询,报文从头到尾只在一个线程内处理,不跨线程切换上下文。
- zero copy:CPU不执行block data的copy,只由网卡硬件进行DMA,节省CPU cycles。
- lock-free:全程无锁化。
- share nothing:每个线程有自己独立的内存缓冲区和上下文,线程间不共享数据。
- TSO/GSO:使用硬件的无状态卸载能力,比如TSO大包切片。
- Batch RX/TX:以批量的形式进行报文和IO的发送和接收,提高cache命中率。
- Multi-thread:在lock-free的基础上使用多线程进行处理能力的并行扩展。
- Multi-queue:使用硬件的多队列能力将数据直接喂给CPU core,每个队列只专属一个CPU core,每个CPU core有自己专属的收发队列集合,core之间不交叉使用队列。
- Use huge page:使用大页能加速VA到PA的翻译,从而加速DMA过程。

5 路线2:half offload半卸载
采用此技术路线的有阿里云SOLAR,天翼云SF-STACK。
5.1 SOLAR:a storage-oriented UDP stack
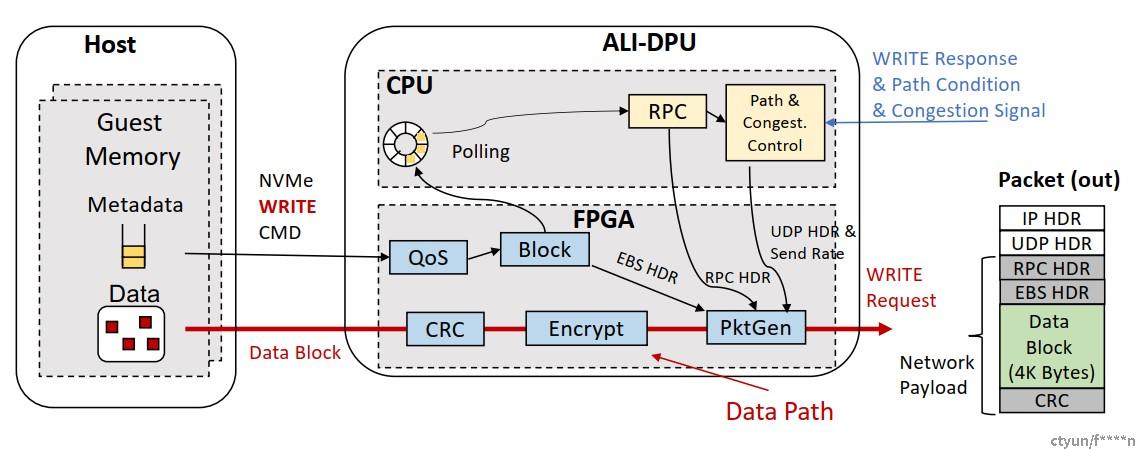 The workflow of a WRITE request in SOLAR
The workflow of a WRITE request in SOLAR

The workflow of a READ request in SOLAR
核心观点: one packet one block: 每个报文都包含payload写入block device的全部信息。
- offloading the entire EBS data path: 处理packet就是处理block,将block处理逻辑硬化为报文处理逻辑。
- Simplified and lightweight hardware implementation: 各个packet之间没有依赖关系,不保序,因此无需保存状态,无需将多个报文merge为一个大的message。
- High confidence on data integrity: CRC of CRC,每512B计算block CRC,最后综合所有block CRC计算最终的CRC,在数据一致性和CPU overhead间平衡
- Multi-path transport for fast failure recovery:因为采用的是UDP,每个包自成一体,不像TCP的一个flow必须走相同的path,因此UDP支持大规模扩展。
- 避免了block data上送至DPU上的CPU,一方面减少了总体时延,另一方面避免了block data在DPU内部FPGA与CPU之间的PCIE总线上的2次传送,网口达到200G后这里的PCIE总线就会形成带宽瓶颈。
5.2 天翼云SF-Stack:存储与网络融合设计

- Meta data 走DPU上的SOC,由software生成报文头,以及生成DMA指令。
- DPU上的NIC收到DMA指令直接从host搬运block data作为报文payload。
- 小数据走DPU SOC,大数据由DPU NIC硬件直接DMA,减少DPU SOC开销,减少时延。
- 兼顾灵活性与高性能。
6 路线3:full offload 全卸载
6.1 天翼云SF-Stack storage agent(LAVA)全卸载:
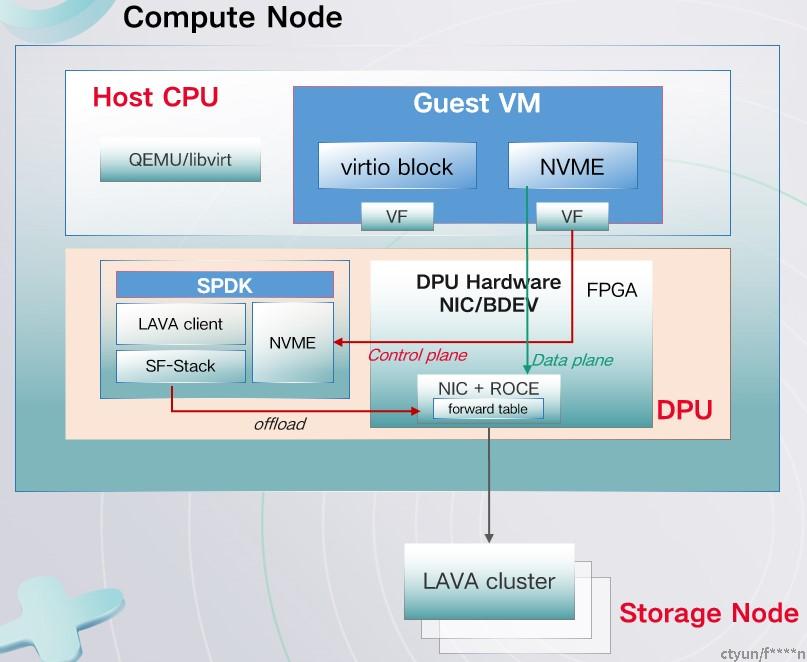
- 控制面上到SoC建链,数据面直接由DPU硬件发送。
- SoC侧控制面会把云盘元数据信息在FPGA中做更新,之后IO由DPU硬件直接进行收发。
- 当云盘元数据发生变化导致IO无法收发,则此部分IO将由SoC侧来进行处理,并更新相关元数据。
- 性能达到500w IOPS。
6.2 SF-Stack与应用加速器的融合

FPGA offload的加速器包括:
- 支持EC纠删码计算
- 支持数据压缩
- 支持存储object hash值计算
- 支持一次操作同时读写存储对象数据和元数据
- 支持CAS操作
6.3 存储集群nvme target offload
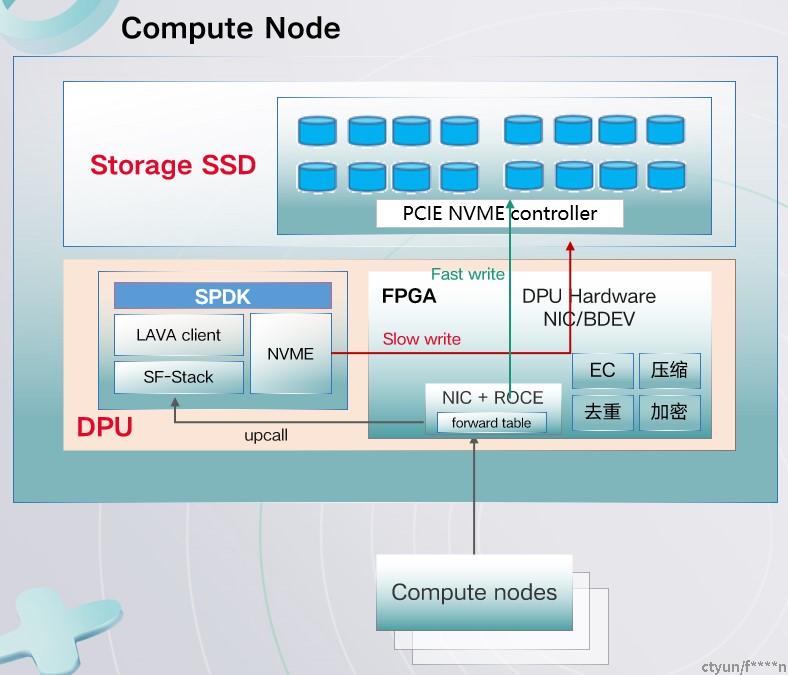
- 存储节点上的DPU FPGA直接将IO请求内的数据写入NVME device,bypass DPU SOC.
- 当DPU FPGA内没有转发规则时upcall到DPU SOC,再在慢路径处理并进一步在FPGA内建立转发规则。
- peer-to-peer PCI 通信,无需CPU介入。
