


在实际工作当中, 我以类似SRE角色独立运维过对外提供api接口能力的系统,这套系统日调用量约70万次,系统可用性要求较高,出现分钟级的不可用情况,客户就会感知,运营就会收到客户投诉,结合近期在极客时间学习了SRE实战手册专栏,对于提高运维质量,有自己一些想法,在这里抛砖引玉,供大家参考;
我先分享2个概念和一张系统稳定性保障规划图,
MTBF:Mean Time Between Failure, 译为平均故障时间间隔;
MTBR:Mean Time Between Repaire, 译为故障平均修复时间;
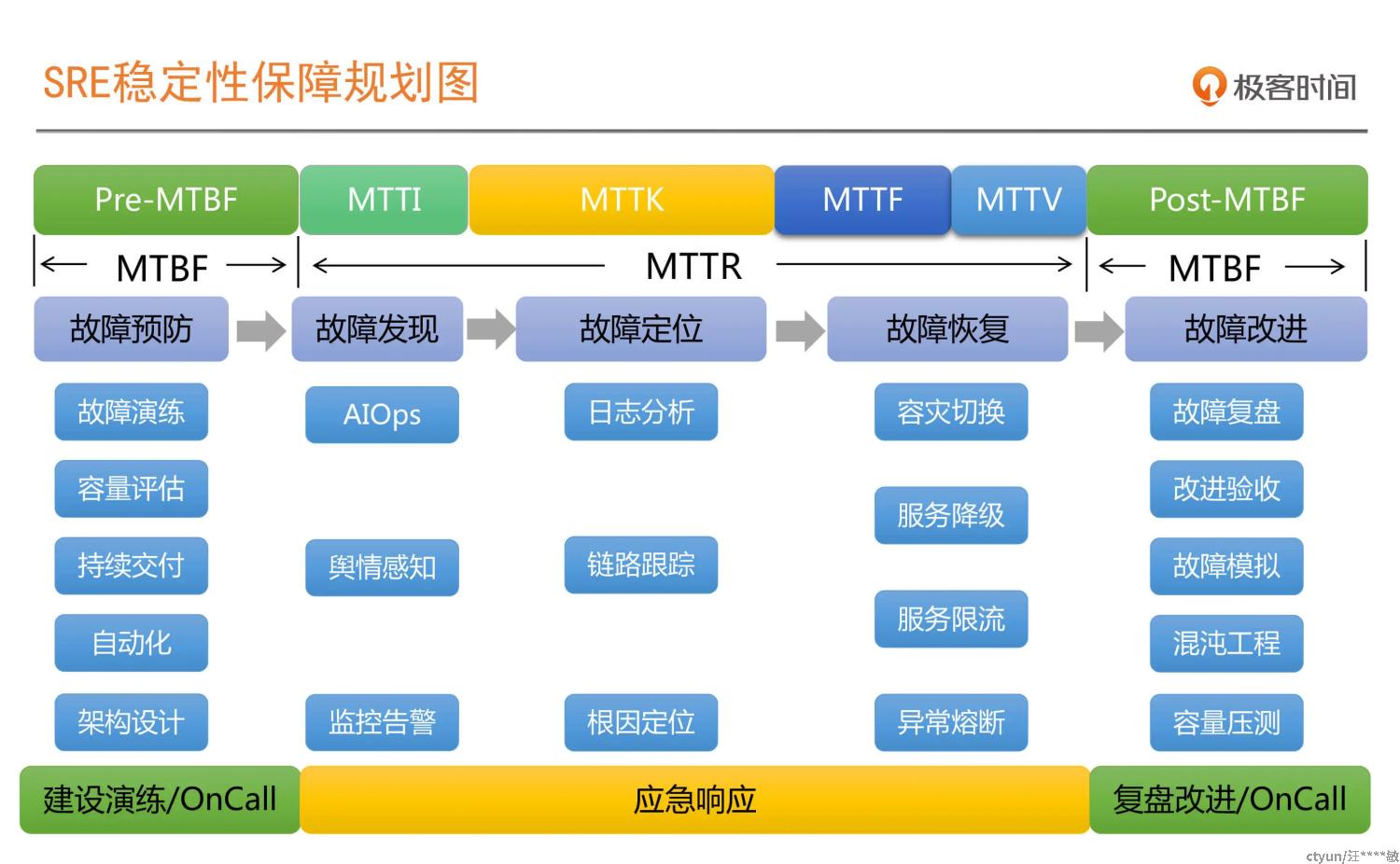
若要提高系统的稳定性、可用性,就要想办法减少故障发生率,减少故障平均修复时间。结合自己在实际工作当中的经验,聊下在架构设计、故障演练、监控系统建设、onCall制度建设、故障复盘的的一些经验;
- 架构设计
在项目架构设计评审阶段,运维人员需要参与架构设计评审,对架构设计的高可用、可运维性、可观测性给出建议, 架构师选择架构组件时,应当尽量选择运维组有运维经验的组件 ,防止出现组件故障时,运维人员因为对组件不熟悉导致定位组件问题定位时间过长,对于日志的格式、字段,运维从后期运维的角度也可以给出意见,甚至给出日志模版;运维人员可以把部署方案和架构师进行分享,架构师可以提供部署优化建议。
- 故障演练
故障演练可以让故障处理人员熟悉故障处理流程,在真正发生故障时,可以快速进入故障处理角色,不至于手忙脚乱;若系统涉及跨部门,进行故障演练时,一定要拉上跨部门关键角色人员,此外,网络运维人员也需要拉入,在我的实际工作经验当中,就出现过几起因为网络原因导致的生产故障;故障演练最好安排一、二次非工作日或是非工作时间演练,为了应对这些时间段的故障处理。
- 监控系统建设
针对系统建设相关的监控系统,有助于提前发现潜在的隐患,也可以在系统异常、不可用时触发告警。在实际工作当中,我们团队建设了服务器性能、组件、业务监控,告警发生时,监控系统会将告警信息发送到企业微信运维群、钉钉运维群中,值班人员收到告警,就会着手进行处理。
1.服务器性能监控,包括cpu、内存、硬盘,网络传输,比如可用内存小于4个G触发告警;
2.组件监控,比如数据库mysql、redis、elasticsearch、nginx;
3.业务监控,比如说是对外提供api的监控,可以监控api返回500,监控api响应时常,监控200占比;
- onCall的流程机制建设
1.保证关键角色在线
这里的关键角色不仅仅是一线值班人员,还包括系统组件的运维人员、网络运维人员、二线研发人员,若是系统依赖其它部门系统,则需要和其它部门约定好onCall制度,保证依赖系统关键角色在线。
2.组织War Room应急组织
若故障发生在工作时间,最好把相关人员拉进线下会议室,作为作战室,若是非工作时间,那就建议虚拟作战室,确立发生故障时,然后快速组建战室,呼叫故障处理人员进入作战室。
3.建立合理升级制度
若故障级别高,直接升级到高级别领导协调多资源投入,尽可能快速恢复业务、解决故障;
若短时间内,现有人员解决不了故障,需要进行升级到更高级别领导,协调更多资源投入;
- 故障复盘
即使我们身经百战,做足了准备,故障的发生难以避免,不过也不要太过沮丧,我们要学会从故障中学习,故障复盘就是一种很好的方式。
故障复盘黄金三问
1.这次故障的原因有哪些?
2.我们做哪些事情可以确保下次不在发生类似的故障?
3.故障处理过程中,如果我们采取哪些措施,可以更加快速的恢复业务,解决故障?
故障复盘讨论时紧扣上述三个问题进行讨论,获取上述三个问题的答案后,安排人员进行改进;
以上是我对运维的一些思考,提高系统稳定性、可用性是一个体系化工程,涉及的岗位、环节非常多,文章里我只写感受比较深的内容,感兴趣的同学,可以去极客时间学习下Sre 实战手册课程,作者是赵成;
