


Cilium调研(1)
- Cilium组件
https://docs.cilium.io/en/stable/concepts/overview/
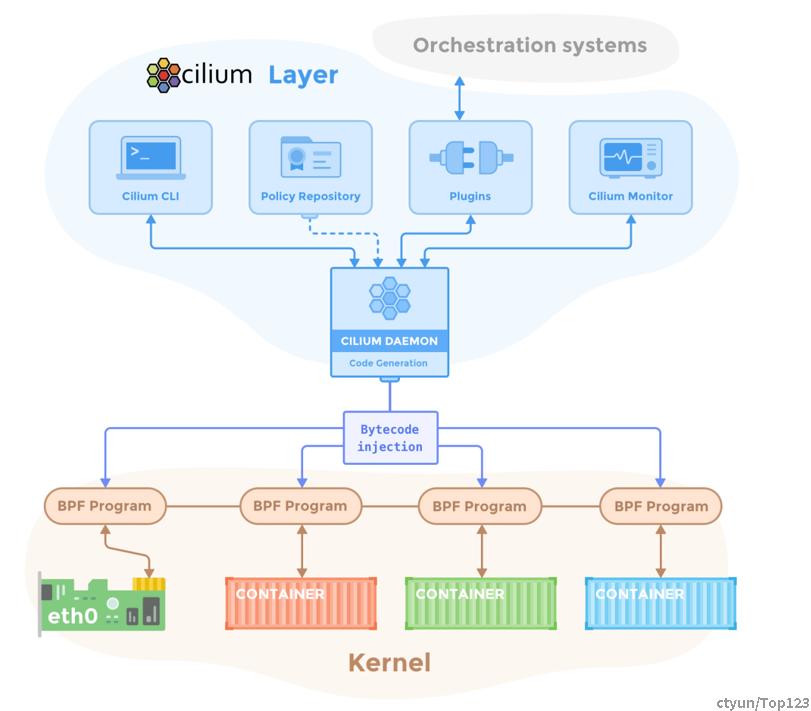
Cilium的部署包括以下组件,运行在容器集群中的每个Linux容器节点上:
- Cilium代理(cilium-agent, Daemon)在每个Linux容器主机上运行。
- Cilium CLI Client是一个与Cilium Agent一起安装的命令行工具。
- Linux Kernel BPF: 集成Linux内核的功能,用于接受内核中在各种钩子/跟踪点运行的已编译字节码。
- Cilium关键特性
Cilium 是一个基于 eBPF 技术的云原生网络、安全和可观测项目。下面简单列举一些特性。
网络功能
- 通过 CNI 集成到 Kubernetes。
- 基于 BPF 实现了 Pod-to-Pod 数据转发路径(datapath)。
- 支持直接路由(direct routing)、overlay络模式。
- 支持 IPv4、IPv6、NAT46 ( IPv4 到 IPv6 数据包互相转换)。
- 支持多集群路由(multi-cluster routing)。
- 集成BGP协议, 实现AS自治。
负载均衡
- 实现了高度可扩展的 L3-L4(XDP)负载均衡。Maglev 一致哈希值。
- 能完全替代 kube-proxy,提供 K8s Service 功能。
- 支持多集群(multi-cluster)。
https://cloudnativeto.netlify.app/blog/deep-dive-into-cilium-multi-cluster/
通过隧道或直接路由,以本地性能对多个Kubernetes集群进行Pod IP路由,而无需任何网关或代理。
网络安全
- 支持基于身份的(identity-based)L3-L7 网络安全,CiliumNetworkPolicy。
- API-aware (API感知的安全性, HTTP、gRPC 等)
- 允许所有带有方法GET和路径/public/.*的HTTP请求。拒绝所有其他请求。
- 允许service1在Kafka topic上生成topic1,service2消费topic1。拒绝所有其他Kafka消息。
- 要求HTTP标头X-Token: [0-9]+出现在所有REST调用中。
- 支持WireGuard透明加密(Transparent Encryption) ,对集群中 Pod 之间的流量进行加密, 作为现有 IPsec 实现的替代方案,性能更高。典型应用场景云边通信(边缘计算,私网到公网,私网到私网),UDP打洞 。https://docs.cilium.io/en/stable/gettingstarted/encryption-wireguard/
Cilium Service Mesh ( Beta 版本)
可观测性
- Metrics: 也是通过 BPF 收集观测数据包含:网络、DNS、安全、延迟、HTTP 等方面的数据。
- 提供流日志服务(flow log),并支持设置聚合粒度(datapath aggregation)。 流日志场景: 实时性高,监控吞吐量,优化网络。
- 基于 eBPF 的 L7 追踪和度量(无 Sidecar)。
- 基于eBPF 加速的per-node 模型。
- TLS 终止(外部https + 内部http)、金丝雀发布。
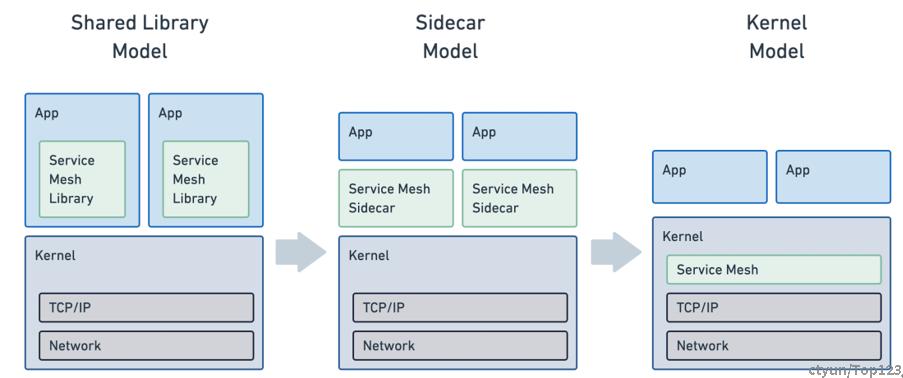
- Mesh 和APP耦合在一块。
- Mesh和APP解耦,但是每个APP上都有一个Mesh , Mesh数量 = 节点×容器数,Mesh多了即占用很多内存,也影响访问性能。
- Mesh下沉到Kernel,每个节点上只有一个Mesh。
补充 <Why use Flow Logs ?>
https://docs.microsoft.com/en-us/azure/network-watcher/network-watcher-nsg-flow-logging-overview
You can use it for optimizing network flows, monitoring throughput, verifying compliance, detecting intrusions and more.
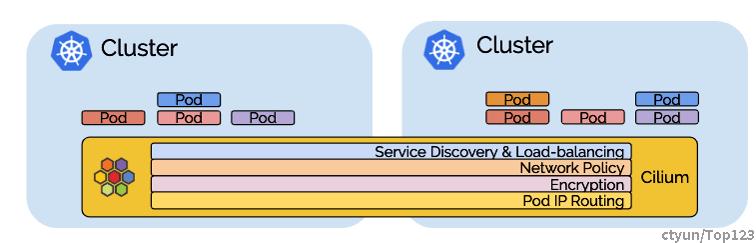
由于cilium特性很多,先集中讲下cilium在网络的优势。
Cilium 支持以下多节点的网络模型:
- Overlay 网络,当前支持 Vxlan 和 Geneve ,也可以启用 Linux 支持的所有封装格式。
网络虚拟化协议:
- VLAN (12bit) , 可对应 2048个 租户
- VXLAN (24bit),可以对应1600万 租户
- GENEVE , 不再由固定的bit数组成,而是可变长,可扩展的。本质是使用TLV类型的数据(Type-Length-Value), 可层层嵌套,不断递归。
- Native Routing, 当前支持BGP(边界网关协议) , 直接使用主机路由,并且在主机上也容器的 IP 地址,calico网络插件底层就是基于BGP协议组网。
- 基于Cilium 实现的容器网络方案
下面我们将看看 Cilium 是如何用 eBPF 实现容器网络方案的
Cilium 中的eBPF 流程
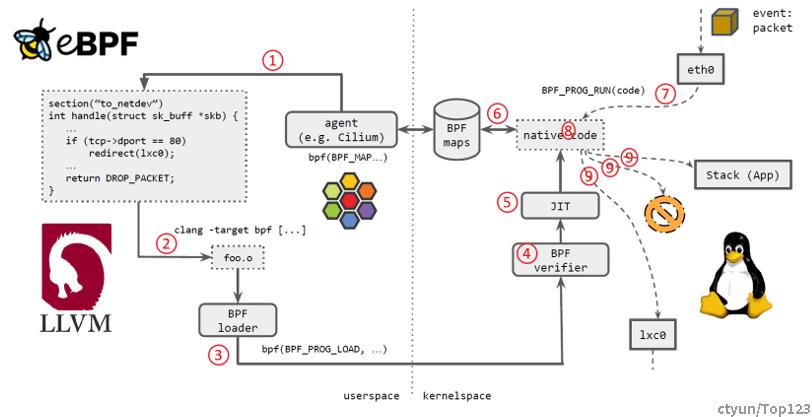
如上图所示,几个步骤:
- Cilium agent 生成 eBPF 程序。
- 用 LLVM 编译 eBPF 程序,生成 eBPF 对象文件(object file,*.o)。
- 用 eBPF loader 将对象文件加载到 Linux 内核。
- 校验器(verifier)对 eBPF 指令会进行合法性验证,以确保程序是安全的,例如 ,无非法内存访问、不会 crash 内核、不会有无限循环等。
- 对象文件被即时编译(JIT)为能直接在底层平台(例如 x86)运行的 native code。
- 如果要在内核和用户态之间共享状态,BPF 程序可以使用 BPF map,这种一种共享存储,BPF 侧和用户侧都可以访问。
- BPF 程序就绪,等待事件触发其执行。对于这个例子,就是有数据包到达网络设备时,触发 BPF 程序的执行。
- BPF 程序对收到的包进行处理,例如 mangle。最后返回一个裁决(verdict)结果。
- 根据裁决结果,如果是 DROP,这个包将被丢弃;如果是 PASS,包会被送到更网络栈的 更上层继续处理;如果是重定向,就发送给其他设备。
kube-proxy 包转发路径
从网络角度看,使用传统的 kube-proxy 处理 Kubernetes Service 时,包在内核中的 转发路径是怎样的?如下图所示: 穿越整个netfilter/iptable协议栈。
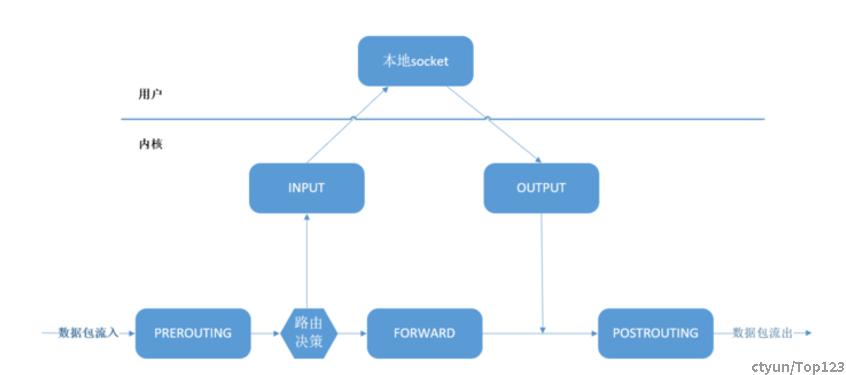
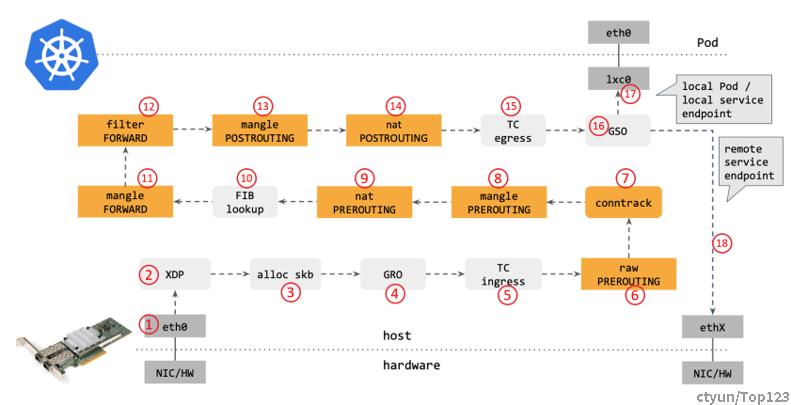
步骤:
- 网卡收到一个包(通过 DMA 放到 ring-buffer)。
- 包经过 XDP hook 点。
- 内核给包分配内存,此时才有了大家熟悉的skb(包的内核结构体表示),然后 送到内核协议栈。
- 包经过 GRO 处理,对分片包进行重组。
- 包进入 tc(traffic control)的 ingress hook。接下来,所有橙色的框都是 Netfilter 处理点, 共8个Hook。
- Netfilter:在PREROUTING hook 点处理 raw table 里的 iptables 规则。
- 包经过内核的连接跟踪(conntrack)模块。
- Netfilter:在PREROUTING hook 点处理 mangle table 的 iptables 规则。
- Netfilter:在PREROUTING hook 点处理 nat table 的 iptables 规则。
- 进行路由判断(FIB:Forwarding Information Base,路由转发表) 。接下来又是四个 Netfilter 处理点。
- Netfilter:在FORWARD hook 点处理 mangle table 里的 iptables 规则。
- Netfilter:在FORWARD hook 点处理 filter table 里的 iptables 规则。
- Netfilter:在POSTROUTING hook 点处理 mangle table 里的 iptables 规则。
- Netfilter:在POSTROUTING hook 点处理 nat table 里的 iptables 规则。
- 包到达 TC egress hook 点,会进行出方向(egress)的判断,例如判断这个包是到本 地设备,还是到主机外。
- 对大包进行分片。根据 step 15 判断的结果,这个包接下来可能会:
- 发送到一个本机 veth 设备,或者一个本机 service endpoint,
- 或者,如果目的 IP 是主机外,就通过网卡发出去。
Cilium eBPF 包转发路径
作为对比,再来看下 Cilium eBPF 中的包转发路径:
对比可以看出,Cilium eBPF datapath 做了短路(short-cut)处理:从 tc ingress 直接 shortcut 到 tc egress,节省了 9 个中间步骤(总共 17 个)。更重要的是:这个 datapath 绕过了 整个 Netfilter 框架(橘黄色的框们),Netfilter 在大流量情况下性能是很差的。去掉那些不用的框之后,Cilium eBPF datapath 长这样:
这里为什么可行呢? 是因为cilium使用 tc-eBPF 程序。
tc(traffic classifier,流量分类器)是 Cilium 依赖的最基础的东西,它提供了多种功 能,例如修改包(mangle,给 skb 打标记)、重路由(reroute)、丢弃包(drop),这 些操作都会影响到内核的流量统计,因此也影响着包的排队规则(queueing discipline )。Cilium 控制的网络设备,至少被加载了一个 tc eBPF 程序。
Cilium/eBPF 还能走的更远。例如,如果包的目的端是另一台主机上的 service endpoint,那你可以直接在 XDP (如果网卡驱动支持XDP, 则offload(卸载)到网卡上执行,不走协议栈)框中完成包的重定向(收包 1->2,在步骤 2 中对包 进行修改,再通过 2->1 发送出去),将其发送出去,如下图所示:
默认转发流程:
优化后转发流程: 不走协议栈,把转发逻辑offload到网卡上执行
可以看到,这种情况下包都没有进入内核协议栈(准确地说,都没有创建 skb)就被转 发出去了,性能可想而知。XDP 是 eXpress DataPath 的缩写,支持在网卡驱动中运行 eBPF 代码,而无需将包送到复杂的协议栈进行处理,因此处理代价很小,速度极快。
- 基于cilium的负载均衡
Cilium 基于 eBPF/XDP 实现了所有类型的 Kubernetes Service。实现方式是:
- 在每个 node 上运行一个 cilium-agent;cilium-agent 监听 K8s apiserver,因此能够感知到 K8s 里 Service 的变化;
- 根据 Service 的变化动态更新 BPF 配置(map)。
可见,本质和k8s的默认方式没有变化,都是监听service对象CRUD,只是k8s通过iptables,而cilium则借助于ebpf的map能力,从而优化了性能。
如下图所示,Service 的实现由两个主要部分组成:
- 运行在 socket 层的 BPF 程序。
- 运行在 tc/XDP 层的 BPF 程序。
这两者共享 service map 等资源,其中存储了 service 及其 backend pods 的映射关系。
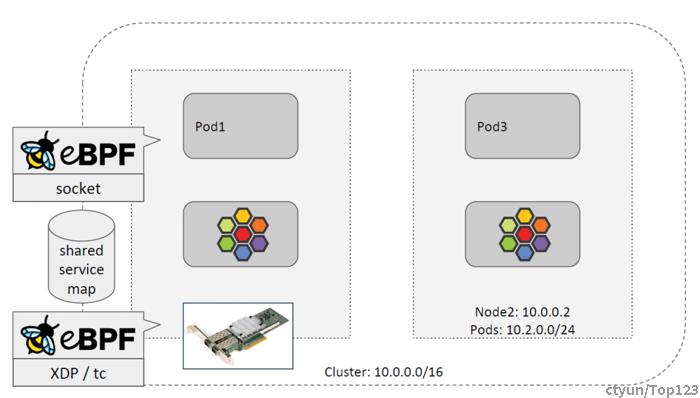
Socket 层负载均衡(东西向流量)
Socket 层 BPF 负载均衡负责处理集群内的东西向流量。实现方式是:将 BPF 程序 attach 到 socket 的系统调用 hooks,使客户端直接和后端 Pod 建连和通信 (bpf 重定向)。
TC & XDP 层负载均衡(南北向流量)
第二种是进出集群的流量(ingress/egress),称为南北向流量,在宿主机 tc 或 XDP hook 里处理。BPF 做的事情,将入向流量转发到后端 Pod,如果 Pod 在本节点,做 DNAT;如果在其他节点,还需要做 SNAT 或者 DSR( Direct Server Return ),这些都是 packet 级别的操作。
- XDP/eBPF vs kube-proxy 性能对比(cilium 官网)
网络吞吐
测试环境:两台物理节点,一个发包,一个收包,收到的包做 Service loadbalancing 转发给后端 Pods。数值越高越好。
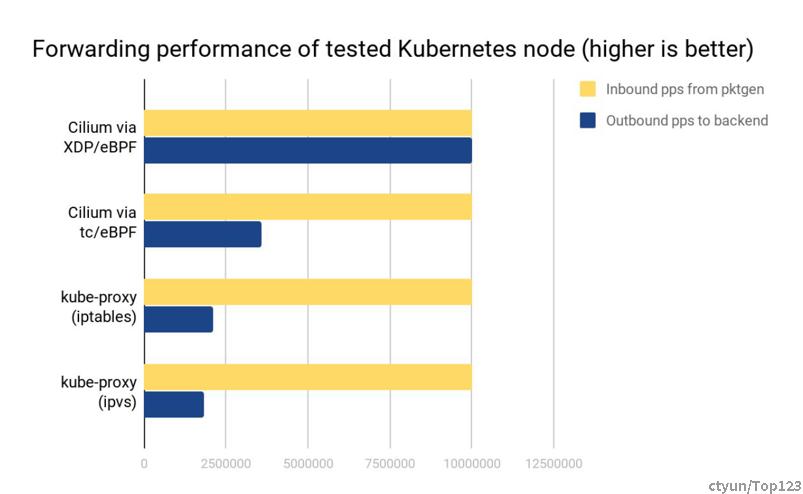
可以看出:
- Cilium XDP eBPF 模式能处理接收到的全部 10Mpps (避免穿越内核协议栈,当然性能最高)。
- Cilium tc eBPF 模式能处理5Mpps(packets per second)。
- kube-proxy iptables 只能处理3Mpps,因为它的 hook 点在收发包路径上更后面的位置。充分说明了hook点越靠前,处理越快,性能越好。
- kube-proxy ipvs 模式这里表现更差,它相比 iptables 的优势要在 backend 数量很多的时候才能体现出来。
CPU 利用率
我们生成了 1Mpps、2Mpps 和 4Mpps 流量,空闲 CPU 占比(可以被应用使用的 CPU)结果如下: 数值越高越好。
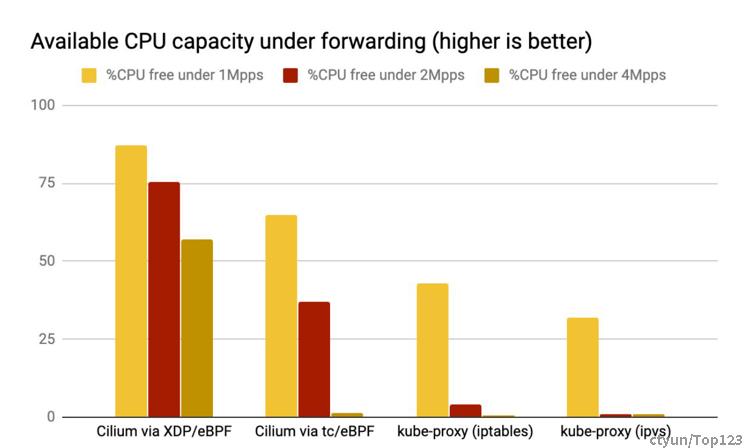
结论与上面吞吐类似。
- XDP 性能最好,是因为XDP BPF 在驱动层执行,不需要将包 push 到内核协议栈 , cilium tc 其次。
- kube-proxy 不管是 iptables 还是 ipvs 模式,都在处理软中断(softirq)上消耗了大量 CPU。
- 网络策略
Kubernetes 的网络策略仅能工作在 L3/4 层,对 L7 层就无能为力了。而cilium不仅支持 L3/4、还支持L7 的网络策略( method ,路径,内容TODO)。进一步,Cilium全集群网络策略(CCNP,Cilium-Clusterwide-Network-Policy资源规范与现有Cilium-Network-Policy CRD规范相同,但适用范围更广,面向整个集群中全部Pod。TODO.
cailico 做对比 。Kubecon大会, cilium最近发展方向,动态,cilium本身的license , 生态圈内的license 。
