


eBPF调研(1)
eBPF发展历程
eBPF(extend-BPF) 是从 BPF (Berkeley Packet Filter) 技术扩展而来的。 早在1992年就为 BSD 操作系统带来了革命性的包过滤机制 BSD Packet Filter(简称为 BPF),这比当时最先进的数据包过滤技术还快20 倍。为什么性能这么好呢?这主要得益于BPF 的包过滤技术,它可以直接在内核中执行,避免了向用户态复制每个数据包,从而极大提升了包过滤的性能,我们常用的抓包工具tcpdump背后就是BPF技术。 直到2011年在, Linux 3.0 中才增加的BPF即时编译器(JIT)可以算是一个最重大的更新了。它替换掉了原本性能更差的解释器,进一步优化了 BPF 指令运行的效率。但直到此时,BPF的应用还是仅限于网络包过滤这个传统的领域中,中途发展一直较慢,直到2014年进入发展快车道。
2014年,为了研究新的软件定义网络方案,Alexei Starovoitov 为 BPF 带来了第一次革命性的更新,将 BPF 扩展为一个通用的虚拟机,也就是 eBPF。eBPF 的诞生是 BPF 技术的一个转折点,使得 BPF 不再仅限于网络栈,而是成为内核的一个顶级子系统。
2015年,BCC(BPF Compiler Collection)提供了一些列基于eBPF的工具和库函数,极大的简化了eBPF程序的开发和运行,同时从linux-4.1开始支持kprobe和cls_bpf(用于tc )
2016年,linux-4.7-4.10引入了跟踪点(tracepoint),perf事件,XDP以及cgroups。同年cilium项目发布。
2017年,BPF成为内核独立的子模块,并支持kTLS(内核级别的TLS), bpftool,libbpf(bpf的lib库)。同年Netflix,Facebook,cloudflare等大厂开始讲ebpf用于跟踪,DDOS防御,4层的LB。
2018年,BPF新增了轻量级调试信息格式BTF以及新的AF_XDP类型的格式。同年,cilium发布1.0版本,bpftrace和bpffilter项目也正是发布。
2019年,BPF新增了对尾调用(tail-call)和热更新的支持,GCC也开始支持EBPF的编译。同年cilium-1.6发布了基于BPF的服务发现(可完全替换基于iptable的kube-proxy)。
2020年,google和Facebook为BPF新增LSM和TCP拥塞控制的支持,主流云厂商开始通过SRIOV(硬直通)支持XDP。同年,微软基于ebpf开始为windows监控工具sysmon增加linux支持。
2021年,ebpf基金会成立,包括微软,Facebook,google。同年cilium发布基于ebpf的service mesh,取代了代理模式。截止目前ebpf生态空前活跃。https://ebpf.io/
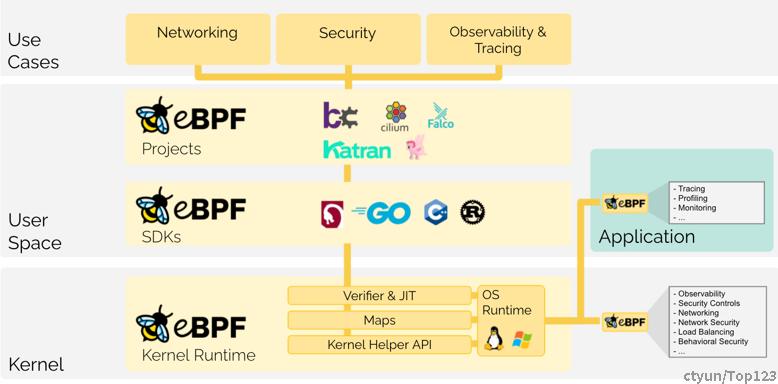
在内核发展的同时,尤其是4.x 和5.x,eBPF 繁荣的生态也进一步促进了 eBPF 的蓬勃发展。与之相关的开源项目如下:
- BCC (基于BPF的高效内核跟踪工具包和库)
- bpftrace (Linux eBPF 的高级跟踪语言)
- Cilium (基于 eBPF 的网络、安全性和可观察性)
- Falco (云原生运行时安全)
- Katran (高性能4层负载均衡器)
- eBPF for Windows (基金计划)
- Hubble (使用 eBPF 的 Kubernetes 网络、服务和安全可观察性)
- KubeArmor (容器感知运行时安全执行系统)
- kubectl 跟踪(在 Kubernetes 集群中可以调度 bpftrace(8) 程序的执行)
- L3AF(eBPF 程序的完整生命周期管理)
- ply(Linux 的动态跟踪器)
- Tracee(使用 eBPF 的 Linux 运行时安全和取证)
eBPF的工作原理
eBPF 程序并不像常规的线程那样,启动后就一直运行在那里,它需要事件触发后才会执行。这些事件包括系统调用、内核跟踪点、内核函数和用户态函数的调用退出、网络事件,等等。借助于强大的内核态插桩(kprobe)和用户态插桩(uprobe),eBPF 程序几乎可以在内核和应用的任意位置进行插桩。
通常我们借助 LLVM 把编写的 eBPF程序转换为 BPF 字节码,然后再通过 bpf 系统调用提交给内核执行。内核在接受 BPF 字节码之前,会首先通过验证器对字节码进行校验,只有校验通过的 BPF 字节码才会提交到即时编译器执行,如下图所示: https://ebpf.io/
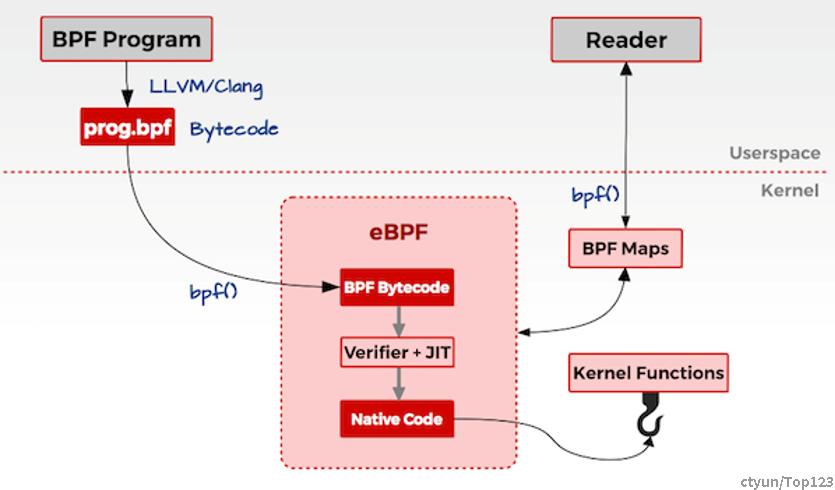
如果 BPF 字节码中包含了不安全的操作,验证器会直接拒绝 BPF 程序的执行。BPF 程序可以利用 BPF 映射(map)进行存储,而用户程序通常也需要通过map与运行在内核中的 BPF 程序进行交互。 在性能观测中, BPF 程序收集内核运行状态存储在映射中,用户程序再从映射中读出这些状态。
- 只有特权进程才可以执行 bpf 系统调用;
- BPF 程序不能包含无限循环;
- BPF 程序不能导致内核崩溃;
- BPF 程序必须在有限时间内完成。
可以看到,eBPF 程序的运行需要历经编译、加载、验证和内核态执行等过程,而用户态程序则需要借助 BPF 映射来获取内核态 eBPF 程序的运行状态。
eBPF 的限制
eBPF 技术虽然强大,但是为了保证内核的处理安全和及时响应,内核中的 eBPF 技术也给予了诸多限制,当然随着技术的发展和演进,限制也在逐步放宽或者提供了对应的解决方案。
此外,虽然 Linux 内核很早就已经支持了 eBPF,但很多新特性都是在 4.x 版本中逐步增加的,具体你可以看下这个链接。所以,想要稳定运行 eBPF 程序,内核版本至少需要 4.9或者更新。而在开发和学习 eBPF 时,为了体验最新的 eBPF 特性,推荐使用更新的 5.x。同时eBPF 也不是万能的,它也有很多的局限性:
- eBPF 程序不能调用任意的内核参数,只限于内核模块中列出的 BPF Helper 函数,以bpf_打头的函数,函数支持列表也随着内核的演进在不断增加。见链接: https://www.man7.org/linux/man-pages/man7/bpf-helpers.7.html
- eBPF 程序不允许包含无法到达的指令,防止加载无效代码,延迟程序的终止。
- eBPF 程序中循环次数限制且必须在有限时间内结束,这主要是用来防止在 kprobes 中插入任意的循环,导致锁住整个系统;解决办法包括展开循环,并为需要循环的常见用途添加辅助函数。Linux 5.3 在 BPF 中包含了对有界循环的支持,它有一个可验证的运行时间上限。
- eBPF 堆栈大小被限制在 MAX_BPF_STACK,截止到内核 Linux 5.8 版本,被设置为 512;参见include/linux/filter.h (#define MAX_BPF_STACK 512),这个限制特别是在栈上存储多个字符串缓冲区时:一个char[256]缓冲区会消耗这个栈的一半。目前没有计划增加这个限制,解决方法是改用 bpf 映射存储,它实际上是无限的。见连接: https://elixir.bootlin.com/linux/latest/source/include/linux/filter.h
- eBPF 字节码大小最初被限制为 4096 条指令,截止到内核 Linux 5.8 版本, 当前已将放宽至 100 万指令 efine BPF_COMPLEXITY_LIMIT_INSNS 1000000 ,参见:include/linux/bpf.h,对于无权限的BPF程序,仍然保留4096条限制 ( BPF_MAXINSNS );新版本的 eBPF 也支持了多个 eBPF 程序级联调用,虽然传递信息存在某些限制,但是可以通过组合实现更加强大的功能。https://elixir.bootlin.com/linux/latest/source/include/linux/bpf.h
BPF 程序开发语言
对于大多数开发者而言,更多的是基于 BPF 技术之上编写解决我们日常遇到的各种问题,当前 BCC 和 BPFTrace 两个项目在观测和性能分析上已经有了诸多灵活且功能强大的工具箱,完全可以满足我们日常使用。
方法1,基于C 语言
用C语言来编写 BPF 程序,门槛较高,但有助于对加深对eBPF 技术的理解。它使用 LLVM + clang 把c源码编译成 BPF 字节码,然后加载都内核执行该字节码。
方法2,基于BCC
BCC 提供了更高阶的抽象,可以让用户采用 Python、C++ 、Golang、 Lua 等高级语言快速开发 BPF 程序;
https://github.com/iovisor/bcc
https://est357.github.io/posts/cilium_iovisor/
https://github.com/iovisor/gobpf
方法3,基于BPFTrace
BPFTrace 采用类似于 awk 语言快速编写 eBPF 程序;BPFTrace 是基于 BPF 和 BCC 的开源项目,与 BCC 不同的是其提供了更高层次的抽象,可以使用类似 AWK 脚本语言来编写基于 BPF 的跟踪或者性能排查工具,更加易于入门和编写,该工具的主要灵感来自于 Solaris 的 D 语言。
https://github.com/iovisor/bpftrace
https://github.com/iovisor/bpftrace/blob/master/docs/reference_guide.md
https://github.com/iovisor/bpftrace/blob/master/docs/tutorial_one_liners.md
eBPF程序开发步骤
作为 eBPF 最重大的改进之一,一次编译到处执行(简称 CO-RE)解决了内核数据结构在
不同版本差异导致的兼容性问题。不过,在使用 CO-RE 之前,内核需要开启
CONFIG_DEBUG_INFO_BTF=y 和 CONFIG_DEBUG_INFO=y 这两个编译选项。为了避免你在首次学习 eBPF 时就去重新编译内核,推荐使用已经默认开启这些编译选项的发行版,作为你的开发环境,比如:
Ubuntu 20.10+
Fedora 31+
RHEL 8.2+
Debian 11+
环境准备:
- 升级内核到x
- 安装将 eBPF 程序编译成字节码的 LLVM + clang 编译工具
- 安装最流行的 eBPF 工具集 BCC 和它依赖的内核头文件
- 安装与内核代码仓库实时同步的 libbpf;
- 安装 bpftool 工具。
在开发 eBPF 程序之前,先来看一下 eBPF 的开发和执行过程。
第一步,使用 C 语言开发一个 eBPF 程序;
第二步,借助 LLVM 把 eBPF 程序编译成 BPF 字节码;
第三步,通过 bpf 系统调用,把 BPF 字节码提交(load)给内核;
第四步,内核验证并运行 BPF 字节码,并把相应的状态保存到 BPF 映射中;
第五步,用户程序通过 BPF 映射查询 BPF 字节码的运行状态
https://brendangregg.com/ebpf.html
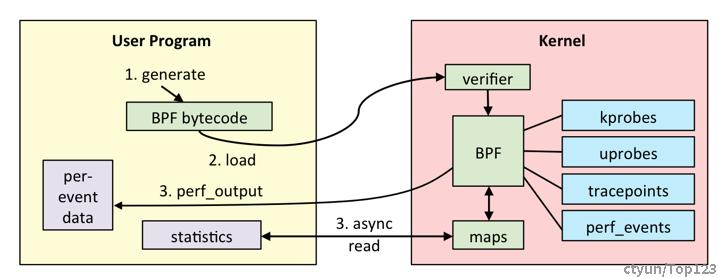
从上图也可以看到,kernel有4种不同类型的事件源(event source) ,同时有2种方法把数据传回给用户态(per-event 或者 map),同时map也有多种类型。
If the BPF bytecode is accepted, it can then be attached to different event sources:
- kprobes: kernel dynamic tracing.
- uprobes: user level dynamic tracing.
- tracepoints: kernel static tracing.
- perf_events: timed sampling and PMCs.
The BPF program has two ways to pass measured data back to user space: either per-event details, or via a BPF map. BPF maps can implement arrays, associative arrays, and histograms, and are suited for passing summary statistics.
下面从0开始编写eBPF的hello word
第一步:使用 C 开发一个 eBPF 程序 ,新建一个 hello.c 文件,并输入下面的内容:
int hello_world(void *ctx)
{
bpf_trace_printk("Hello, World!");
return 0;
}
第二步:使用 Python 和 BCC 库开发一个用户态程序 ,接下来,创建一个 hello.py 文件,并输入下面的内容:
#!/usr/bin/env python3
# 1) 导入 bcc 库
from bcc import BPF
# 2) 加载BPF 程序
b = BPF(src_file="hello.c")
# 3) attach kprobe
b.attach_kprobe(event="do_sys_open", fn_name="hello_world")
# 4) 读取结果 cat /sys/kernel/debug/tracing/trace_pipe
b.trace_print()
第三步:执行 eBPF 程序 ,用户态程序开发完成之后,最后一步就是执行它了。需要注意的是, eBPF 程序需要以root 用户来运行.
#python hello.py
cat-10656 表示进程的名字和 PID;
[006] 表示 CPU 编号;
d… 表示一系列的选项;
2348.114455 表示时间戳;
bpf_trace_printk 表示函数名;
最后的 “Hello, World!” 就是调用 bpf_trace_printk() 传入的字符串。
BPF tips & tricks: the guide to bpf_trace_printk() and bpf_printk()
https://nakryiko.com/posts/bpf-tips-printk/
改进该 eBPF 程序
BPF 程序可以利用 BPF 映射(map)进行数据存储,而用户程序也需要通过 BPF 映射,同运行在内核中的 BPF 程序进行交互。所以,为了解决上面提到的第一个问题,即获取被打开文件名的问题,我们就要引入BPF 映射。
// 包含头文件
#include <uapi/linux/openat2.h>
#include <linux/sched.h>
// 定义数据结构
struct data_t {
u32 pid;
u64 ts;
char comm[TASK_COMM_LEN];
char fname[NAME_MAX];
};
// 定义性能事件映射
BPF_PERF_OUTPUT(events);
// 定义kprobe处理函数
int hello_world(struct pt_regs *ctx, int dfd, const char __user * filename, st
{
struct data_t data = { };
// 获取PID和时间
data.pid = bpf_get_current_pid_tgid();
data.ts = bpf_ktime_get_ns();
// 获取进程名
if (bpf_get_current_comm(&data.comm, sizeof(data.comm)) == 0)
{
bpf_probe_read(&data.fname, sizeof(data.fname), (void *)filename);
}
// 提交性能事件
events.perf_submit(ctx, &data, sizeof(data));
return 0;
}
其中,以 bpf 开头的函数都是 eBPF 提供的辅助函数,比如:
有了 BPF 映射之后,前面我们调用的 bpf_trace_printk() 其实就不再需要了,因为用户态进程可以直接从 BPF 映射中读取内核 eBPF 程序的运行状态。 这其实也就是上面提到的第二个待解决问题。那么,怎样从用户态读取 BPF 映射内容并输出到标准输出(stdout)呢? 在 BCC 中,与 eBPF 程序中 BPF_PERF_OUTPUT 相对应的用户态辅助函数是open_perf_buffer() 。它需要传入一个回调函数,用于处理从 Perf 事件类型的 BPF映射中读取到的数据。具体的使用方法如下所示:
{
bpf_probe_read(&data.fname, sizeof(data.fname), (void *)filename);
}
// 提交性能事件
events.perf_submit(ctx, &data, sizeof(data));
return 0;
}
bpf_get_current_pid_tgid 用于获取进程的 TGID 和 PID。因为这儿定义的data.pid 数据类型为 u32,所以高 32 位舍弃掉后就是进程的 PID;
bpf_ktime_get_ns 用于获取系统自启动以来的时间,单位是纳秒;
bpf_get_current_comm 用于获取进程名,并把进程名复制到预定义的缓冲区中;
bpf_probe_read 用于从指定指针处读取固定大小的数据,这里则用于读取进程打开的文件名。
Bpf辅助函数可以从如下获取帮助手册
https://www.man7.org/linux/man-pages/man7/bpf-helpers.7.html
