在redis cluster容错机制中,我们通常会为集群中每个主节点设置若干的从节点,这样可以保证当某个主节点发生故障时,集群会自动将其中某个节点提升为主节点。但是如果某个主节点没有从节点,主发生故障时,会导致集群出于不可用的状态,服务端会抛出(error) CLUSTERDOWN The cluster is down的错误。
不过redis cluster提供了cluster-require-full-coverage配置,当cluster-require-full-coverage 参数为no时 集群若有一对主从都故障,集群也会仍保持可用;依靠redis cluster自身的高可用性,那么什么时候会导致集群不可用的情况?
- 集群任意主挂掉,并且当前主没有从节点,集群不可用(cluster-require-full-coverage = yes)
- 集群超过半数以上的主同时故障,无论是否有这些主是否有从节点,集群不可用 (选举过程是集群中所有的主节点参与,如果半数以上master节点与故障master节点通信,若通信超过cluster-node-timeout, 则认为当前master节点挂掉,需要对其进行主从切换)
若同时遇到半数以上的主节点故障时,依赖集群自身的高可用无法恢复,这时依赖接入机Access介入:
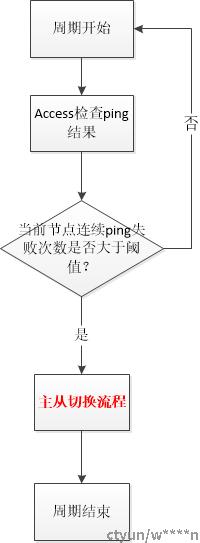
接入机Access会定期收集每个主节点的状态,如果超过两倍的cluster-node-timeout,这时由接入机介入恢复(只有在redis cluster自身无法恢复的情况下接入:如果在cluster-node-timeout内,access介入会干扰集群自身的恢复机制)Access介入机制具体如下:。
* Access介入 一般都是集群失效状态(无法完成自动切换的场景)
* 场景一 主节点未宕机 判断master节点数超过一半, access在故障master对应的 slave节点执行CLUSTER FAILOVER 等待数据同步并且投票
* 场景二 主节点未宕机 判断master节点数少于过一半, access在故障master对应的 slave节点执行CLUSTER FAILOVER TAKEOVER 无需投票
* 场景三 主节点已宕机 判断master节点数超过一半, access在故障master对应的 slave节点执行CLUSTER FAILOVER FORCE 不用等待数据同步
* 场景四 主节点已宕机 判断master节点数少于过一半, access在故障master对应的 slave节点执行CLUSTER FAILOVER TAKEOVER
* 优先级 cluster failver > cluster failover force > cluster failover takeover

CLUSTER FAILOVER处理流程:
Step1: 通知master停止处理来自客户端的请求
Step2:master响应当前最大的replication offset
Step3: 客户端等待复制复制同步完成直到replication offset
Step4: 提升epoch并获取半数leader的选举认可
Step5: 更新configuration并解除客户端的阻塞请求,返回重定向到新的master
该操作用于正常的主从切换,但是如果master节点宕机了无法响应failover请求,那么failover将会失败,为了处理master宕机的情况,可以添加FORCE 选项。
CLUSTER FAILOVER FORCE: 添加FORCE选项时,failover流程直接从上述的第4步开始,也即跳过了和旧master通信协商复制数据的过程,当master宕机时,force选项可以快速进行人工主从切换。但是该过程仍然需要获得半数master的统=同意才能当选为新主。当出现半数master节点异常时,该流程无法进行主从切换。
CLUSTER FAILOVER TAKEOVER: 为了处理半数master节点异常的场景,可以添加TAKEOVER 选项。通过TAKEOVER 选项,可以无需获得半数master的认同,而是直接更新状态为master并向所有可达的节点发送最新配置epoch。
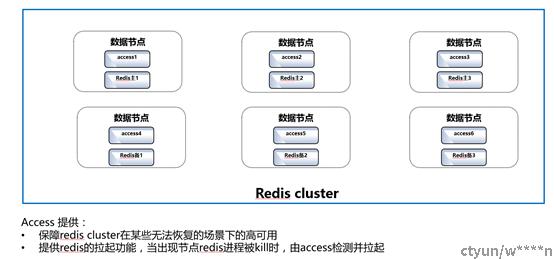
附:集群架构