


1. 流量识别的意义
随着互联网的普及和发展,网络应用越来越多,其产生的流量呈现爆发式增长;并且,为了应对隐私保护、信息安全等需求,大多数网络应用都会选择对流量进行加密。准确识别网络流量,尤其是加密流量,是能有效进行流量监控、安全管理,进行用户行为分析等的基础;也是网络运营商和服务商能根据不同业务类型提供相应的保障响应和服务品质的基础。
2. 常用的流量识别方法
目前常用的流量识别方法包括端口识别方法、DPI(Deep Packet Inspection,深度包检测)方法、DFI(Deep/Dynamic Flow Inspection,深度/动态流检测)方法和AI(Artificial Intelligence,人工智能)方法等。
端口识别方法,通过只检查数据包的端口号进行识别。比如:HTTP协议通常使用80端口,DNS协议通常使用53号端口……端口识别方法简单易行,但由于越来越多的应用软件使用动态端口,甚至某些应用程序为躲避系统限制使用其他常用协议的端口实现端口隐蔽,导致基于端口的方法对很多应用无法识别。
DPI方法,是通过对流量包的应用层数据进行深度分析,从而识别出相应协议和应用程序的方法。它通常利用应用层载荷中的协议特征签名(通常表现为数据包出现特定字符串或特定数字)匹配来做识别。DPI技术需要逐包拆包匹配,效率较低;且由于网络新协议、新应用层出不穷,其需要不断更新后台特征匹配数据库;再者,随着加密流量的普及,该技术无法有效获取载荷特征,应用也大大受限。
DFI方法,是一种基于流量行为的识别技术。这种方法的基本思路是:不同的应用类型在会话连接及数据流上的特征体现各不相同。通过对数据流的包数、字节大小、包间隔时间、连接速率、持续时间等特征进行分析,建立流量特征模型,从而实现应用识别。该方法基于“流”粒度进行识别,识别效率高;且加密并不会对流特征造成影响,因此也可应用于加密流量识别。但其适合对应用类型进行笼统分类,较难实现精细化管理。
AI方法是近些年来随着深度学习的走红而再次走入大众视野的识别方法。流量识别,可以被看作机器学习任务中的分类或聚类任务来处理,这类任务有众多算法可供选择。该类算法,可以通过输入实际的流量(已标注数据),进行模型训练获得识别模型,而不是通过人工总结规则来应对;且不受流量加密的影响,能够有效进行加密流量识别。但有些较大的模型对设备算力要求较高,需要做投入产出比方面的分析及平衡。
3. 流量识别任务中AI方法的分类
将流量识别任务视作AI分类任务,可简单认为有以下两类方法:
- 传统统计机器学习方法。该方法通常需要依托人工经验或算法先进行流量特征选取。通过提取有效流量特征,将流量数据转化为特征数据,进行AI建模;通过对模型进行训练,得到最终的模型用于流量识别。
RF(Random Forest,随机森林)、SVM(Support Vector Machine, 支持向量机)等算法都属于该类。
- 深度学习方法。该方法通常不需要事先进行特征提取,模型中的深层网络,可以在模型训练过程中自动学习到流量深层特征,并自动做关联特征的组合,只是这些特征通常无法直观解释。利用该方法,可以直接输入流量包数据,进行模型训练和识别。
CNN(Convolutional Neural Network,卷积神经网络)、RNN(Recurrent Neural Network,循环神经网络)等算法都属于该类。
4. AI方法在流量识别任务中的应用实践
AI方法在解决实际任务中的普适性也非常好。事实上,流量识别是一类任务的统称。这个任务可以是直接识别具体应用,如BT、Wechat;也可以识别应用类型,如即时通讯类、P2P类;也可以只识别恶意流量……不同任务都有其适合的应用场景和积极意义。
我们可根据具体任务不同来选择合适的AI识别方法,如恶意流量识别就可选择二分类算法,应用类型识别就可选择多分类算法。
下面通过一个实际的应用类型识别任务,浅谈一下我们在该任务中所应用的AI方法及取得的效果。该任务要求将网络流量划分为网页浏览/实时通讯/音视频播放/办公生产/文件下载5类。通过对国内外文献的查阅、分析,我们一共选择并尝试了以下2种不同类型的AI算法用于应用类型识别。
4.1. RF(Random Forest,随机森林)
RF是经典的机器学习算法。它是决策树算法的衍生,其通过随机的方式,对数据集进行采样生成多个不同的数据集,并在每一个数据集上训练出一棵决策树,最终结合每棵决策树的预测结果作为随机森林的预测结果。在本任务中,RF算法作为监督分类算法。
4.1.1. 训练数据采集和标注
我们采集了5类应用的流量,每一类都尽可能覆盖到常用的网站、APP等。比如实时通讯类,我们就采集了微信、QQ、钉钉等APP的流量。
之后,将采集到的所有数据按照8:2的比例划分成训练集和测试集。训练集用于模型训练,测试集用于测试模型效果。
4.1.2. 数据处理及特征提取
对采集到的所有流量数据,按照五元组进行会话分割。具有相同五元组(源IP、源端口、目的IP、目的端口、协议)的所有包被称作流。会话指由双向流组成的所有包(源和目的互换)。
然后,对每个会话提取会话时长、报文数、报文字节数、上下行报文比例、载荷字节数、报文到达间隔等特征,并计算其均值、方差等统计信息形成特征向量。
4.1.3. 模型训练和测试
特征向量作为输入,进行RF模型训练,得到目标5分类分类器。
将测试集中的数据也进行特征提取,送入训练好的RF模型,并计算识别准确率。
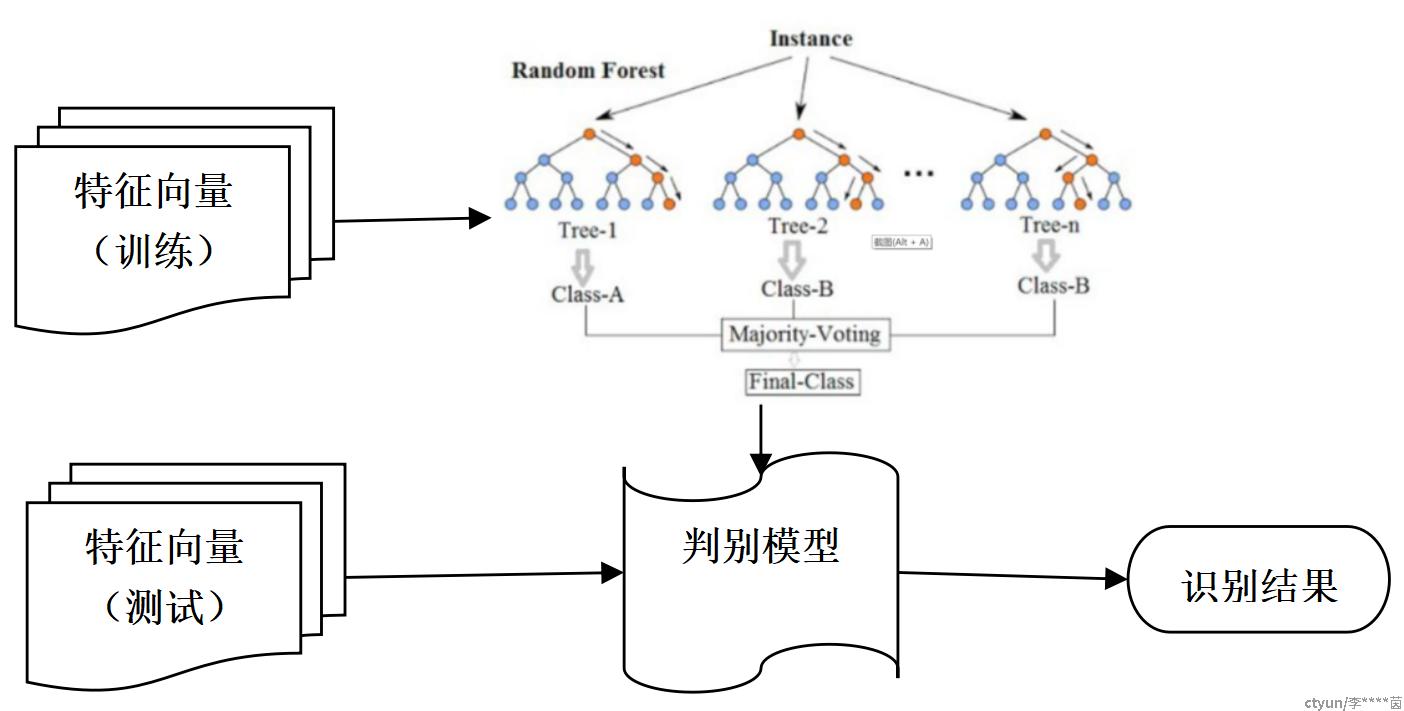
4.1.4. 模型识别
真正进行流量识别时的步骤如下:
- 抓取网络流量
- 对抓取的流量数据按照五元组分割成会话,再提取会话特征,得到特征向量
- 将特征向量送入RF模型,得到具体应用类别
为了达到更好的识别效果,特征的选取至关重要。可以通过人工经验选择有效特征,还可使用AI算法辅助进行筛选。RF算法本身也是很好的特征筛选算法,通过获取每个特征在随机森林中每棵树上的贡献度,就可以筛选出贡献大的特征。筛选出有效特征,既有助于提升模型精确度,也可以尽量减少模型复杂度,提升性能。
4.2. CNN(Convolutional Neural Networks,卷积神经网络)
CNN是一种人工神经网络,是深度学习中大家耳熟能详的算法之一,被广泛应用在图像识别领域。近年来,也被越来越多地应用到其他领域,如本文阐述的流量识别领域。
该方法跟RF方法最大的不同在于,不需事先提取特征向量。可以直接输入流量数据进行判别。采用CNN模型进行流量识别,细节上也有多种不同方法。比如可将输入的流量数据视作图片,采用普通的2D-CNN模型;也可将流量数据作为时序数据,采用1D-CNN模型。我们在实际应用中采用了普通2D-CNN模型,直观上理解,可以认为我们将流量中的一个会话视作一张图片。模型训练及识别流程大致如下图所示:
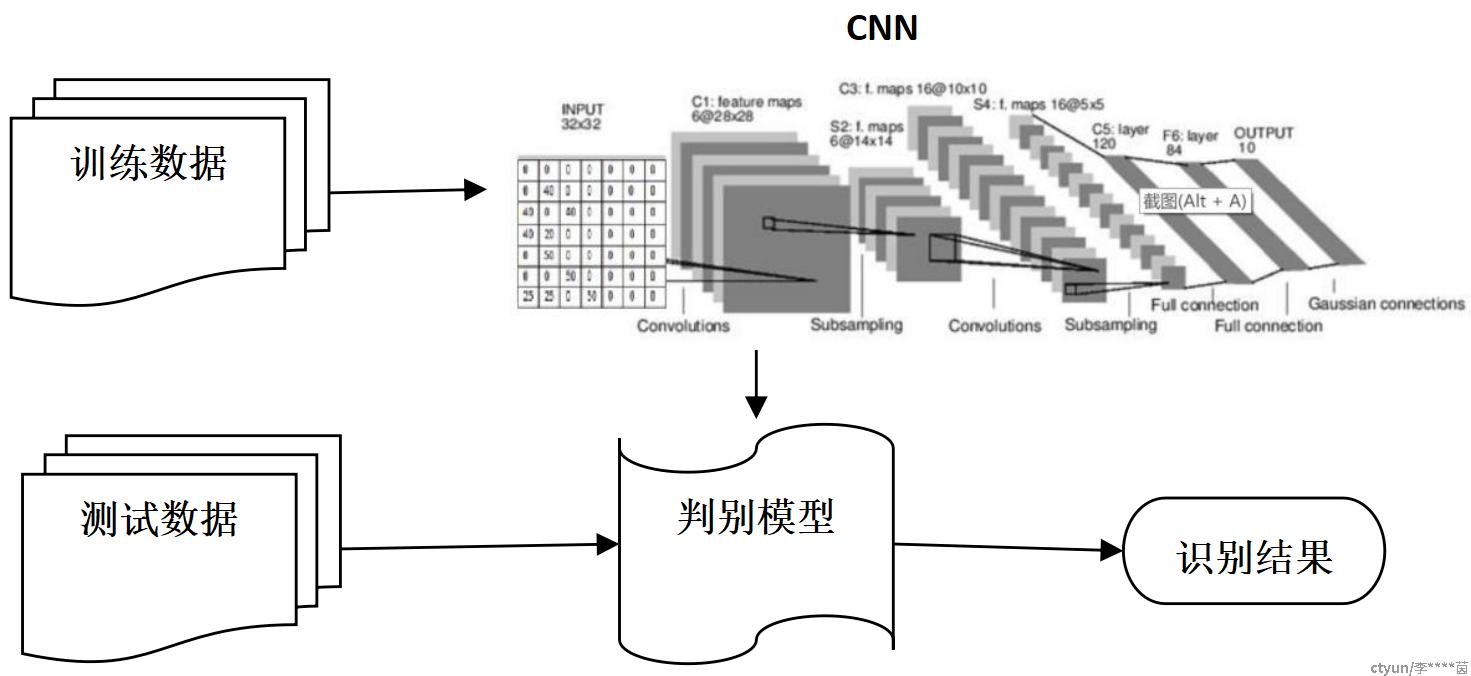
数据采集和模型训练识别过程与上面的RF算法大同小异,这里不再赘述,单说下这里的数据处理。
4.2.1. 数据处理
CNN模型要求图片大小一致,但每个流的包数、每个网络包的字节数都不尽相同。为了能够应用CNN模型,我们取每个流的前24个包,每个包取前24个字节(实践中去除了IP地址,因为流的类型跟实际IP地址无关),作为输入数据。如果数量不足,则用0补齐。这样最终得到了一个24*24的二维矩阵作为输入数据。
4.3. 总结
以上两类算法,在线下模型训练和测试中,效果不相上下,都能够达到99%以上的准确率,召回率也都在95%以上。但在实际应用过程中,由于训练数据规模的限制,CNN模型在真实环境中的泛化效果要略差一些,RF算法的泛化效果则更好。且由于RF模型小,对算力要求较低,效率也更高。
综上,是否选取AI技术作为流量识别方法,选取哪种算法作为识别方法,需要根据实际应用场景、数据规模、算力条件等进行选择。
5. 参考
- https://wenku.baidu.com/view/f866fc4841323968011ca300a6c30c225801f05b.html
- http://news.west.cn/41761.html
- http://t.zoukankan.com/bonelee-p-10303108.html
- https://max.book118.com/html/2017/0521/108160634.shtm
- 《End-to-end Encrypted Traffic Classification with One-dimensional Convolution Neural Networks》Wei Wang, Ming Zhu,Jinlin Wang, Xuewen Zeng, Zhongzhen Yang
- 《A Survey of Techniques for Mobile Service Encrypted Traffic Classification Using Deep Learning》PAN WANG, XUEJIAO CHEN, FENG YE, ZHIXIN SUN
- 《Mobile Encrypted Traffic Classification Using Deep Learning》Giuseppe Aceto, Domenico iuonzo, Antonio Montieri, Antonio Pescapé
