


(一)、为什么我们需要Pod?
引言
容器的“单进程模型”,并不是指容器里只能运行“一个”进程,而是指容器没有管理多个进程的能力。
Pod,是 Kubernetes 项目的原子调度单位。这就意味着,Kubernetes 项目的调度器,是统一按照 Pod 而非容器的资源需求进行计算的。
实质上,Pod是一组共享了某些资源的容器。在k8s中,通过Pod来解决一些紧密协作的容器间的调度问题。超亲密的docker(可以理解为一个进程组)可以组成一个Pod。这些具有“超亲密关系”容器的典型特征包括但不限于:互相之间会发生直接的文件交换、使用 localhost 或者 Socket 文件进行本地通信、会发生非常频繁的远程调用、需要共享某些 Linux Namespace(比如,一个容器要加入另一个容器的 Network Namespace)等等。
l Pod 的实现原理
Pod只是一个逻辑概念。也就是说,Kubernetes 真正处理的,还是宿主机操作系统上 Linux 容器的 Namespace 和 Cgroups,而并不存在一个所谓的 Pod 的边界或者隔离环境。
Pod 里的所有容器,共享的是同一个 Network Namespace,并且可以声明共享同一个 Volume。
一个 Pod 里的多个容器不是拓扑关系(前后有依赖,启动有顺序),而是对等关系(无前后依赖)。所以,在 Kubernetes 项目里,Pod 的实现需要使用一个中间容器,这个容器叫作 Infra 容器。在这个 Pod 中,Infra 容器永远都是第一个被创建的容器,而其他用户定义的容器,则通过 Join Network Namespace 的方式,与 Infra 容器关联在一起。这样的组织关系,可以用下面这样一个示意图来表达:
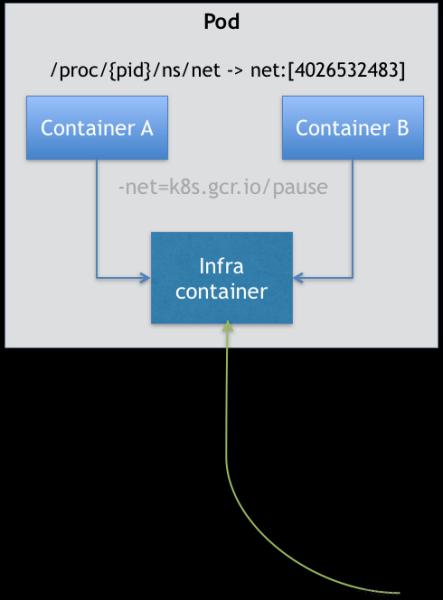
如上图所示,这个 Pod 里有两个用户容器 A 和 B,还有一个 Infra 容器。很容易理解,在 Kubernetes 项目里,Infra 容器一定要占用极少的资源,所以它使用的是一个非常特殊的镜像,叫作:k8s.gcr.io/pause。这个镜像是一个用汇编语言编写的、永远处于“暂停”状态的容器,解压后的大小也只有 100~200 KB 左右。
而在 Infra 容器“Hold 住”Network Namespace 后,用户容器就可以加入到 Infra 容器的 Network Namespace 当中了。所以,如果你查看这些容器在宿主机上的 Namespace 文件,它们指向的值一定是完全一样的。
这也就意味着,对于 Pod 里的容器 A 和容器 B 来说:
- 它们可以直接使用 localhost 进行通信;
- 它们看到的网络设备跟 Infra 容器看到的完全一样;
- 一个 Pod 只有一个 IP 地址,也就是这个 Pod 的 Network Namespace 对应的 IP 地址;
- 当然,其他的所有网络资源,都是一个 Pod 一份,并且被该 Pod 中的所有容器共享;
- Pod 的生命周期只跟 Infra 容器一致,而与容器 A 和 B 无关。
而对于同一个 Pod 里面的所有用户容器来说,它们的进出流量,也可以认为都是通过 Infra 容器完成的。
有了这个设计之后,共享 Volume 就简单多了:Kubernetes 项目只要把所有 Volume 的定义都设计在 Pod 层级即可。这样,一个 Volume 对应的宿主机目录对于 Pod 来说就只有一个,Pod 里的容器只要声明挂载这个Volume,就一定可以共享这个 Volume 对应的宿主机目录。
l 容器设计模式
Pod 这种“超亲密关系”容器的设计思想,实际上就是希望,当用户想在一个容器里跑多个功能并不相关的应用时,应该优先考虑它们是不是更应该被描述成一个 Pod 里的多个容器。
没有pod时,用户要花心思考虑多个进程间的关系;现在只要考虑放到一个pod中,其它的就交给pod了。相当于抽象出了一种设计模式。比如:war包+tomcat服务器组合的应用可以采用init container+container的方式组合成一个pod。容器之间的组合,就是容器设计模式里最常用的sidecar模式。
——sidecar模式:我们可以在一个pod中,启动一个辅助容器,来完成一些独立于主进程(主容器)之外的工作。
举例:容器的日志收集
我现在有一个应用,需要不断地把日志文件输出到容器的 /var/log 目录中。这时,我就可以把一个 Pod 里的 Volume 挂载到应用容器的 /var/log 目录上。然后,我在这个 Pod 里同时运行一个 sidecar 容器,它也声明挂载同一个 Volume 到自己的 /var/log 目录上。这样,接下来 sidecar 容器就只需要做一件事儿,那就是不断地从自己的 /var/log 目录里读取日志文件,转发到 MongoDB 或者 Elasticsearch 中存储起来。这样,一个最基本的日志收集工作就完成了。
小结
- 可以这样理解Pod的本质:Pod,实际上是在扮演传统基础设施里“虚拟机”的角色;而容器,则是这个虚拟机里运行的用户程序。
- 完成传统基于虚拟机的应用到微服务架构的迁移,核心思想是:分析应用组成(组件、进程), 将其拆分成松耦合的容器(以容器镜像方式分发), 利用 Init Container 来解决顺序和依赖关系。
- 无论是从具体的实现原理,还是从使用方法、特性、功能等方面,容器与虚拟机几乎没有任何相似的地方;也不存在一种普遍的方法,能够把虚拟机里的应用无缝迁移到容器中。因为,容器的性能优势,必然伴随着相应缺陷,即:它不能像虚拟机那样,完全模拟本地物理机环境中的部署方法。实际上,一个运行在虚拟机里的应用,哪怕再简单,也是被管理在 systemd 或者 supervisord 之下的一组进程,而不是一个进程。这跟本地物理机上应用的运行方式其实是一样的。这也是为什么,从物理机到虚拟机之间的应用迁移,往往并不困难。可是对于容器来说,一个容器永远只能管理一个进程。更确切地说,一个容器,就是一个进程。这是容器技术的“天性”,不可能被修改。所以,将一个原本运行在虚拟机里的应用,“无缝迁移”到容器中的想法,实际上跟容器的本质是相悖的。
(二)、深入解析Pod对象
问题:到底哪些属性属于 Pod 对象,而又有哪些属性属于 Container 呢?
如果把 Pod 看成传统环境里的“机器”、把容器看作是运行在这个“机器”里的“用户程序”,那么很多关于 Pod 对象的设计就非常容易理解了。比如:
- 凡是调度、网络、存储,以及安全相关的属性,基本上是 Pod 级别的。这些属性的共同特征是,它们描述的是“机器”这个整体,而不是里面运行的“程序”。比如,配置这个“机器”的网卡(即:Pod 的网络定义),配置这个“机器”的磁盘(即:Pod 的存储定义),配置这个“机器”的防火墙(即:Pod 的安全定义)。更不用说,这台“机器”运行在哪个服务器之上(即:Pod 的调度)。
- 除了跟“机器”相关的配置外,凡是跟容器的 Linux Namespace 相关的属性,也一定是 Pod 级别的。这个原因也很容易理解:Pod 的设计,就是要让它里面的容器尽可能多地共享 Linux Namespace,仅保留必要的隔离和限制能力。这样,Pod 模拟出的效果,就跟虚拟机里程序间的关系非常类似了。
- 凡是 Pod 中的容器要共享宿主机的 Namespace,也一定是 Pod 级别的定义
l 几个重要字段
- NodeSelector:是一个供用户将 Pod 与 Node 进行绑定的字段
- NodeName
一旦 Pod 的这个字段被赋值,Kubernetes 项目就会被认为这个 Pod 已经经过了调度,调度的结果就是赋值的节点名字。所以,这个字段一般由调度器负责设置,但用户也可以设置它来“骗过”调度器。一般在测试或者调试时可以手动设置。
- HostAliases
定义了 Pod 的 hosts 文件(比如 /etc/hosts)里的内容。注意:在 Kubernetes 项目中,如果要设置 hosts 文件里的内容,一定要通过这种方法。否则,如果直接修改了 hosts 文件的话,在 Pod 被删除重建之后,kubelet 会自动覆盖掉被修改的内容。
- Containers和InitContainers
- Image(镜像)、Command(启动命令)、workingDir(容器的工作目录)、Ports(容器要开发的端口),以及 volumeMounts(容器要挂载的 Volume)都是构成 Kubernetes 项目中 Container 的主要字段。
- ImagePullPolicy
它定义了镜像拉取的策略。而它之所以是一个 Container 级别的属性,是因为容器镜像本来就是 Container 定义中的一部分。ImagePullPolicy 的值默认是 Always,即每次创建 Pod 都重新拉取一次镜像。另外,当容器的镜像是类似于 nginx 或者 nginx:latest 这样的名字时,ImagePullPolicy 也会被认为 Always。而如果它的值被定义为 Never 或者 IfNotPresent,则意味着 Pod 永远不会主动拉取这个镜像,或者只在宿主机上不存在这个镜像时才拉取。
- Lifecycle
它定义的是 Container Lifecycle Hooks。顾名思义,Container Lifecycle Hooks 的作用,是在容器状态发生变化时触发一系列“钩子”。用于回调执行容器特定事件。
l Pod 的生命周期
Pod 生命周期的变化,主要体现在 Pod API 对象的 Status 部分,这是它除了 Metadata 和 Spec 之外的第三个重要字段。其中,pod.status.phase,就是 Pod 的当前状态,它有如下几种可能的情况:
- Pending。这个状态意味着,Pod 的 YAML 文件已经提交给了 Kubernetes,API 对象已经被创建并保存在 Etcd 当中。但是,这个 Pod 里有些容器因为某种原因而不能被顺利创建。比如,调度不成功。
- Running。这个状态下,Pod 已经调度成功,跟一个具体的节点绑定。它包含的容器都已经创建成功,并且至少有一个正在运行中。
- Succeeded。这个状态意味着,Pod 里的所有容器都正常运行完毕,并且已经退出了。这种情况在运行一次性任务时最为常见。
- Failed。这个状态下,Pod 里至少有一个容器以不正常的状态(非 0 的返回码)退出。这个状态的出现,意味着你得想办法 Debug 这个容器的应用,比如查看 Pod 的 Events 和日志。
- Unknown。这是一个异常状态,意味着 Pod 的状态不能持续地被 kubelet 汇报给 kube-apiserver,这很有可能是主从节点(Master 和 Kubelet)间的通信出现了问题。
更进一步地,Pod 对象的 Status 字段,还可以再细分出一组 Conditions。这些细分状态的值包括:PodScheduled、Ready、Initialized,以及 Unschedulable。
它们主要用于描述造成当前 Status 的具体原因是什么。比如,Pod 当前的 Status 是 Pending,对应的 Condition 是 Unschedulable,这就意味着它的调度出现了问题。而其中,Ready 这个细分状态非常值得我们关注:它意味着 Pod 不仅已经正常启动(Running 状态),而且已经可以对外提供服务了。
pod和deployment的区别:如果pod所在node异常,那么该pod不会被迁移到其他节点;而deployment会由K8S负责调度保障业务正常运行。
作为用户,还可以通过设置 restartPolicy,改变 Pod 的恢复策略。除了 Always,它还有 OnFailure 和 Never 两种情况:
- Always:在任何情况下,只要容器不在运行状态,就自动重启容器;
- OnFailure: 只在容器 异常时才自动重启容器;
- Never: 从来不重启容器。(如果要关心这个容器退出后的上下文环境,比如容器退出后的日志、文件和目录,就需要将 restartPolicy 设置为 Never。因为一旦容器被自动重新创建,这些内容就有可能丢失掉了(被垃圾回收了))
两个基本的设计原理:
- 只要 Pod 的 restartPolicy 指定的策略允许重启异常的容器(比如:Always),那么这个 Pod 就会保持 Running 状态,并进行容器重启。否则,Pod 就会进入 Failed 状态 。
- 对于包含多个容器的 Pod,只有它里面所有的容器都进入异常状态后,Pod 才会进入 Failed 状态。在此之前,Pod 都是 Running 状态。此时,Pod 的 READY 字段会显示正常容器的个数。
所以,假如一个 Pod 里只有一个容器,然后这个容器异常退出了。那么,只有当 restartPolicy=Never 时,这个 Pod 才会进入 Failed 状态。而其他情况下,由于 Kubernetes 都可以重启这个容器,所以 Pod 的状态保持 Running 不变。而如果这个 Pod 有多个容器,仅有一个容器异常退出,它就始终保持 Running 状态,哪怕即使 restartPolicy=Never。只有当所有容器也异常退出之后,这个 Pod 才会进入 Failed 状态。依此类推。。。
小结
- Kubernetes“一切皆对象”的设计思想:比如应用是 Pod 对象,应用的配置是 ConfigMap 对象,应用要访问的密码则是 Secret 对象。
(三)、编排其实很简单:谈谈“控制器”模型
引言
Pod 这个看似复杂的 API 对象,实际上就是对容器的进一步抽象和封装而已。说得更形象些,“容器”镜像虽然好用,但是容器这样一个“沙盒”的概念,对于描述应用来说,还是太过简单了。这就好比,集装箱固然好用,但是如果它四面都光秃秃的,吊车还怎么把这个集装箱吊起来并摆放好呢?所以,Pod 对象,其实就是容器的升级版。它对容器进行了组合,添加了更多的属性和字段。这就好比给集装箱四面安装了吊环,使得 Kubernetes 这架“吊车”,可以更轻松地操作它。而 Kubernetes 操作这些“集装箱”的逻辑,都由控制器(Controller)完成。
一个nginx-deployment 的例子:
展开源码
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
这个 Deployment 定义的编排动作非常简单,即:确保携带了 app=nginx 标签的 Pod 的个数,永远等于 spec.replicas 指定的个数,即 2 个。这就意味着,如果在这个集群中,携带 app=nginx 标签的 Pod 的个数大于 2 的时候,就会有旧的 Pod 被删除;反之,就会有新的 Pod 被创建。
kube-controller-manager 组件:负责管理 Pod 的调度和控制
kube-controller-manager提供各个对象的控制器。查看一下 某个Kubernetes 项目的 pkg/controller 目录:
$ cd kubernetes/pkg/controller/
$ ls -d */
deployment/ job/ podautoscaler/
cloud/ disruption/ namespace/
replicaset/ serviceaccount/ volume/
cronjob/ garbagecollector/ nodelifecycle/ replication/ statefulset/ daemon/
...
这些控制器之所以被统一放在 pkg/controller 目录下,就是因为它们都遵循 Kubernetes 项目中的一个通用编排模式,即:控制循环(control loop)。
K8s编排模式:控制循环(control loop)
Kubernetes 项目中一个重要的设计思想:控制器模式。用伪代码描述如下:
for {
实际状态 := 获取集群中对象X的实际状态(Actual State)
期望状态 := 获取集群中对象X的期望状态(Desired State)
if 实际状态 == 期望状态{
什么都不做
} else {
执行编排动作,将实际状态调整为期望状态
}
}
其中,实际状态数据来源:
1、kubelet通过心跳汇报
2、监控系统中保存的应用监控数据
3、控制器自己收集
期望状态,一般来自于用户提交的 YAML 文件。比如,Deployment 对象中 Replicas 字段的值。很明显,这些信息往往都保存在 Etcd 中。
控制器模型的实现
以Deployment为例:
- Deployment 控制器从 Etcd 中获取到所有携带了“app: nginx”标签的 Pod,然后统计它们的数量,这就是实际状态;
- Deployment 对象的 Replicas 字段的值就是期望状态;
- Deployment 控制器将两个状态做比较,然后根据比较结果,确定是创建 Pod,还是删除已有的 Pod。
可以看到,一个 Kubernetes 对象的主要编排逻辑,实际上是在第三步的“对比”阶段完成的。这个操作,通常被叫作调谐(Reconcile)。这个调谐的过程,则被称作“Reconcile Loop”(调谐循环)或者“Sync Loop”(同步循环)。它们其实指的都是同一个东西:控制循环。而调谐的最终结果,往往都是对被控制对象的某种写操作。比如,增加 Pod,删除已有的 Pod,或者更新 Pod 的某个字段。这也是 Kubernetes 项目“面向 API 对象编程”的一个直观体现。
——“用一种对象管理另一种对象”的“艺术”
这种设计思路的好处在于,尽管你的系统底层设计可能非常复杂,但用一层一层的抽象可以使“面向用户”部分的概念变得简单。这种简单应当包括自上而下的理解系统设计更简单,和日常的使用维护更简单。
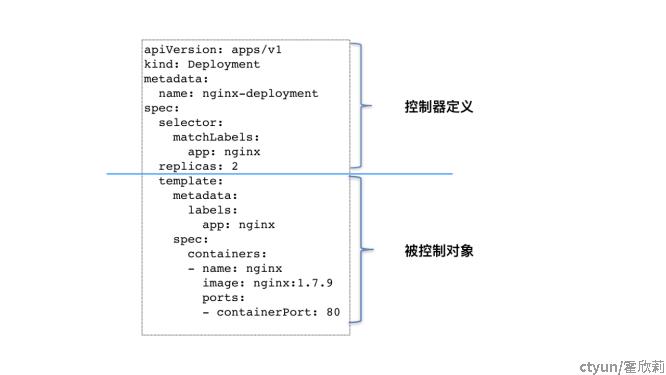
如上图所示,类似 Deployment 这样的一个控制器,实际上都是由上半部分的控制器定义(包括期望状态),加上下半部分的被控制对象的模板(如PodTemplate(Pod 模板))组成的。在所有 API 对象的 Metadata 里,都有一个字段叫作 ownerReference,用于保存当前这个 API 对象的拥有者(Owner)的信息。
小结
- Kubernetes 使用的这个“控制器模式”,跟我们平常所说的“事件驱动”,有什么区别和联系吗?
事件往往是一次性的,如果操作失败比较难处理,但是控制器是循环一直在尝试的,更符合kubernetes声明式API,最终达到与声明一致。
(四)、经典PaaS的记忆:作业副本与水平扩展
Deployment的实现
Deployment实现了 Kubernetes 项目中一个非常重要的功能:Pod 的“水平扩展 / 收缩”(horizontal scaling out/in)。举个例子,如果你更新了 Deployment 的 Pod 模板(比如,修改了容器的镜像),那么 Deployment 就需要遵循一种叫作“滚动更新”(rolling update)的方式,来升级现有的容器。而这个能力的实现,依赖的是 Kubernetes 项目中的一个非常重要的概念(API 对象):ReplicaSet。
ReplicaSet 的结构如下所示:
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: nginx-set
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
可以看到,一个 ReplicaSet 对象,其实就是由副本数目的定义和一个 Pod 模板组成的。它的定义其实是 Deployment 的一个子集。Deployment 控制器实际操纵的,正是这样的 ReplicaSet 对象,而不是 Pod 对象。
Deployment,与 ReplicaSet,以及 Pod 的关系示意图如下:
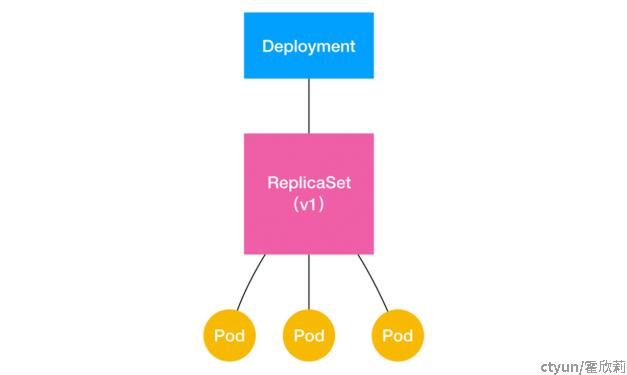
一个定义了 replicas=3 的 Deployment,与它的 ReplicaSet,以及 Pod 的关系,实际上是一种“层层控制”的关系。其中,ReplicaSet 负责通过“控制器模式”,保证系统中 Pod 的个数永远等于指定的个数(比如,3 个)。这也正是 Deployment 只允许容器的 restartPolicy=Always 的主要原因:只有在容器能保证自己始终是 Running 状态的前提下,ReplicaSet 调整 Pod 的个数才有意义。
而在此基础上,Deployment 同样通过“控制器模式”,来操作 ReplicaSet 的个数和属性,进而实现“水平扩展 / 收缩”和“滚动更新”这两个编排动作。其中,“水平扩展 / 收缩”非常容易实现,Deployment Controller 只需要修改它所控制的 ReplicaSet 的 Pod 副本个数就可以了。比如,把这个值从 3 改成 4,那么 Deployment 所对应的 ReplicaSet,就会根据修改后的值自动创建一个新的 Pod。这就是“水平扩展”了;“水平收缩”则反之。
用户想要执行这个“水平扩展”操作的指令也非常简单,就是 kubectl scale,比如:
$ kubectl scale deployment nginx-deployment --replicas=4
deployment.apps/nginx-deployment scaled
Deployment 操作ReplicaSet实现滚动更新
首先,创建一个nginx-deployment
$ kubectl create -f nginx-deployment.yaml --record
// –record 参数的作用,是记录下你每次操作所执行的命令,以方便后面查看。
然后,检查 nginx-deployment 创建后的状态信息:
$ kubectl get deployments
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx-deployment 3 0 0 0 1s
在返回结果中,我们可以看到四个状态字段,它们的含义如下所示。
- DESIRED:用户期望的 Pod 副本个数(spec.replicas 的值);
- CURRENT:当前处于 Running 状态的 Pod 的个数;
- UP-TO-DATE:当前处于最新版本的 Pod 的个数,所谓最新版本指的是 Pod 的 Spec 部分与 Deployment 里 Pod 模板里定义的完全一致;
- AVAILABLE:当前已经可用的 Pod 的个数,即:既是 Running 状态,又是最新版本,并且已经处于 Ready(健康检查正确)状态的 Pod 的个数。
可以看到,只有 AVAILABLE 字段,描述的才是用户所期望的最终状态。
创建后的一系列查看操作:
// 查看 Deployment 对象的状态变化
$ kubectl rollout status deployment/nginx-deployment
Waiting for rollout to finish: 2 out of 3 new replicas have been updated...
deployment.apps/nginx-deployment successfully rolled out
// 在这个返回结果中,“2 out of 3 new replicas have been updated”意味着已经有 2 个 Pod 进入了 UP-TO-DATE 状态。
// 继续等待一会儿,我们就能看到这个 Deployment 的 3 个 Pod,就进入到了 AVAILABLE 状态:
$ kubectl get deployments
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx-deployment 3 3 3 3 20s
// 查看一下这个 Deployment 所控制的 ReplicaSet
$ kubectl get rs
NAME DESIRED CURRENT READY AGE
nginx-deployment-3167673210 3 3 3 20s
在用户提交了一个 Deployment 对象后,Deployment Controller 就会立即创建一个 Pod 副本个数为 3 的 ReplicaSet。这个 ReplicaSet 的名字,则是由 Deployment 的名字和一个随机字符串共同组成。这个随机字符串叫作 pod-template-hash,在上面这个例子里就是:3167673210。ReplicaSet 会把这个随机字符串加在它所控制的所有 Pod 的标签里,从而保证这些 Pod 不会与集群里的其他 Pod 混淆。
这个时候,如果我们修改了 Deployment 的 Pod 模板,“滚动更新”就会被自动触发。
修改 Deployment 有很多方法。比如,可以直接使用 kubectl edit 指令编辑 Etcd 里的 API 对象。也可以使用 kubectl set image 的指令,直接修改 nginx-deployment 所使用的镜像。
$ kubectl edit deployment/nginx-deployment
...
spec:
containers:
- name: nginx
image: nginx:1.9.1 # 1.7.9 -> 1.9.1
ports:
- containerPort: 80
...
deployment.extensions/nginx-deployment edited
kubectl edit 指令编辑完成后,保存退出,Kubernetes 就会立刻触发“滚动更新”的过程。
可以通过 kubectl rollout status 指令查看 nginx-deployment 的状态变化。还可以通过查看 Deployment 的 Events,看到这个“滚动更新”的流程:
$ kubectl describe deployment nginx-deployment
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
...
Normal ScalingReplicaSet 24s deployment-controller Scaled up replica set nginx-deployment-1764197365 to 1
Normal ScalingReplicaSet 22s deployment-controller Scaled down replica set nginx-deployment-3167673210 to 2
Normal ScalingReplicaSet 22s deployment-controller Scaled up replica set nginx-deployment-1764197365 to 2
Normal ScalingReplicaSet 19s deployment-controller Scaled down replica set nginx-deployment-3167673210 to 1
Normal ScalingReplicaSet 19s deployment-controller Scaled up replica set nginx-deployment-1764197365 to 3
Normal ScalingReplicaSet 14s deployment-controller Scaled down replica set nginx-deployment-3167673210 to 0
可以看到,首先,当你修改了 Deployment 里的 Pod 定义之后,Deployment Controller 会使用这个修改后的 Pod 模板,创建一个新的 ReplicaSet(hash=1764197365),这个新的 ReplicaSet 的初始 Pod 副本数是:0。然后,在 Age=24 s 的位置,Deployment Controller 开始将这个新的 ReplicaSet 所控制的 Pod 副本数从 0 个变成 1 个,即:“水平扩展”出一个副本。紧接着,在 Age=22 s 的位置,Deployment Controller 又将旧的 ReplicaSet(hash=3167673210)所控制的旧 Pod 副本数减少一个,即:“水平收缩”成两个副本。
如此交替进行,新 ReplicaSet 管理的 Pod 副本数,从 0 个变成 1 个,再变成 2 个,最后变成 3 个。而旧的 ReplicaSet 管理的 Pod 副本数则从 3 个变成 2 个,再变成 1 个,最后变成 0 个。这样,就完成了这一组 Pod 的版本升级过程。像这样,将一个集群中正在运行的多个 Pod 版本,交替地逐一升级的过程,就是“滚动更新”。
在这个“滚动更新”过程完成之后,可以查看一下新、旧两个 ReplicaSet 的最终状态:
$ kubectl get rs
NAME DESIRED CURRENT READY AGE
nginx-deployment-1764197365 3 3 3 6s
nginx-deployment-3167673210 0 0 0 30s
其中,旧 ReplicaSet(hash=3167673210)已经被“水平收缩”成了 0 个副本。
为了进一步保证服务的连续性,Deployment Controller 还会通过设置RollingUpdateStrategy字段确保,在任何时间窗口内,只有指定比例的 Pod 处于离线状态。同时,它也会确保,在任何时间窗口内,只有指定比例的新 Pod 被创建出来。这两个比例的值都是可以配置的,默认都是 DESIRED 值的 25%。maxSurge 用于指定除了 DESIRED 数量之外,在一次“滚动”中,Deployment 控制器还可以创建多少个新 Pod;而 maxUnavailable 可以设定,在一次“滚动”中,Deployment 控制器可以删除多少个旧 Pod。
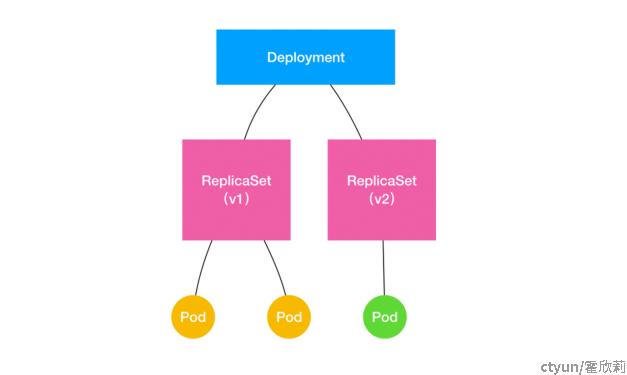
如上图所示,Deployment 的控制器,实际上控制的是 ReplicaSet 的数目,以及每个 ReplicaSet 的属性。而一个应用的版本,对应的正是一个 ReplicaSet;这个版本应用的 Pod 数量,则由 ReplicaSet 通过它自己的控制器(ReplicaSet Controller)来保证。通过这样的多个 ReplicaSet 对象,Kubernetes 项目就实现了对多个“应用版本”的描述。
Deployment 对应用进行版本控制的具体原理
1、把整个 Deployment 回滚到上一个版本:
$ kubectl rollout undo deployment/nginx-deployment
deployment.extensions/nginx-deployment
在具体操作上,Deployment 的控制器,其实就是让旧 ReplicaSet再次“扩展”成 3 个 Pod,而让新的 ReplicaSet重新“收缩”到 0 个 Pod。
2、回滚到更早之前的版本:
|- 首先,使用 kubectl rollout history 命令,查看每次 Deployment 变更对应的版本。
$ kubectl rollout history deployment/nginx-deployment
deployments "nginx-deployment"
REVISION CHANGE-CAUSE
1 kubectl create -f nginx-deployment.yaml --record
2 kubectl edit deployment/nginx-deployment
3 kubectl set image deployment/nginx-deployment nginx=nginx:1.91
可以看到,我们前面执行的创建和更新操作,分别对应了版本 1 和版本 2,而最后失败的更新操作,则对应的是版本 3。
|- 在 kubectl rollout undo 命令行最后,加上要回滚到的指定版本的版本号,就可以回滚到指定版本了
$ kubectl rollout undo deployment/nginx-deployment --to-revision=2
deployment.extensions/nginx-deployment
这样,Deployment Controller 还会按照“滚动更新”的方式,完成对 Deployment 的降级操作。
小结
- replicaSet 操作 pod实现水平扩展和水平收缩,deployment 操作replicaSet实现滚动更新。
Deployment 实际上是一个两层控制器。首先,它通过 ReplicaSet 的个数来描述应用的版本;然后,它再通过 ReplicaSet 的属性(比如 replicas 的值),来保证 Pod 的副本数量。
