


一、从进程到容器
程序与进程
假如,现在你要写一个计算加法的小程序,这个程序需要的输入来自于一个文件,计算完成后的结果则输出到另一个文件中。由于计算机只认识 0 和 1,所以无论用哪种语言编写这段代码,最后都需要通过某种方式翻译成二进制文件,才能在计算机操作系统中运行起来。而为了能够让这些代码正常运行,我们往往还要给它提供数据,比如我们这个加法程序所需要的输入文件。这些数据加上代码本身的二进制文件,放在磁盘上,就是我们平常所说的一个“程序”,也叫代码的可执行镜像(executable image)。
然后,我们就可以在计算机上运行这个“程序”了。首先,操作系统从“程序”中发现输入数据保存在一个文件中,所以这些数据就会被加载到内存中待命。同时,操作系统又读取到了计算加法的指令,这时,它就需要指示 CPU 完成加法操作。而 CPU 与内存协作进行加法计算,又会使用寄存器存放数值、内存堆栈保存执行的命令和变量。同时,计算机里还有被打开的文件,以及各种各样的 I/O 设备在不断地调用中修改自己的状态。就这样,一旦“程序”被执行起来,它就从磁盘上的二进制文件,变成了计算机内存中的数据、寄存器里的值、堆栈中的指令、被打开的文件,以及各种设备的状态信息的一个集合。像这样一个程序运行起来后的计算机执行环境的总和,就是:进程。
所以,对于进程来说,它的静态表现就是程序,平常都安安静静地待在磁盘上;而一旦运行起来,它就变成了计算机里的数据和状态的总和,这就是它的动态表现。
而容器技术的核心功能,就是通过约束和修改进程的动态表现,从而为其创造出一个“边界”。对于 Docker 等大多数 Linux 容器来说,Cgroups 技术是用来制造约束(限制)的主要手段,而 Namespace 技术则是用来修改进程视图(隔离)的主要方法。
小结
- 容器,其实就是操作系统在启动进程时通过设置一些参数实现了隔离不相关资源后的一个特殊进程。
二、隔离与限制
要点
- Docker本身并没有对应用进程进行隔离,也没有创建所谓的“容器”,而是通过宿主机的操作系统通过namespace对应用进程进行隔离,通过cgroups对被隔离的应用进程限制相关资源属性。
- “敏捷”和“高性能”是容器相较于虚拟机最大的优势,也是它能够在 PaaS 这种更细粒度的资源管理平台上大行其道的重要原因。敏捷是指快速打包,快速发布;高性能是指容器进程本来就是系统里的普通进程,没有虚拟化层的性能损失。但缺点是没有虚拟化层的隔离性。
Linux 容器中用来实现“隔离”的技术手段:Namespace
Namespace 技术实际上修改了应用进程看待整个计算机“视图”,即它的“视线”被操作系统做了限制,只能“看到”某些指定的内容。但对于宿主机来说,这些被“隔离”了的进程跟其他进程并没有太大区别。
uts:主机名和域名隔离
ipc:信号量,消息队列和共享内存隔离
mnt:文件系统挂载点隔离
net:网络隔离,每个namespace都有自己独立的ip,路由和端口
pid:隔离进程id
Linux 容器中用来实现“限制”的技术手段:Cgroups
Linux Cgroups 的全称是 Linux Control Group。它最主要的作用,就是限制一个进程组能够使用的资源上限,包括 CPU、内存、磁盘、网络带宽等等。此外,Cgroups 还能够对进程进行优先级设置、审计,以及将进程挂起和恢复等操作。
在 Linux 中,Cgroups 给用户暴露出来的操作接口是文件系统,即它以文件和目录的方式组织在操作系统的 /sys/fs/cgroup 路径下。简单粗暴地理解,Linux Cgroups就是一个子系统目录加上一组资源限制文件的组合。
Cgroups 的每一个子系统都有其独有的资源限制能力,比如:cpu,主要限制进程的cpu使用率;blkio,为块设备设定I/O 限制,一般用于磁盘等设备;cpuset,为进程分配单独的 CPU 核和对应的内存节点;memory,为进程设定内存使用的限制。
小结
- 一个正在运行的 Docker 容器,其实就是一个启用了多个 Linux Namespace 的应用进程,而这个进程能够使用的资源量,则受 Cgroups 配置的限制。
- 容器是一个“单进程”模型。容器本身的设计,就是希望容器和应用能够同生命周期。
三、深入理解容器镜像
现状
Mount Namespace 跟其他 Namespace 的使用略有不同的地方:它对容器进程视图的改变,一定是伴随着挂载操作(mount)才能生效。即:mount namespace是修改文件系统的挂载点,只有挂载操作之后容器才能修改挂载点,修改之前都是直接继承宿主机的挂载点。
需求
每当创建一个新容器时,我希望容器进程看到的文件系统就是一个独立的隔离环境,而不是继承自宿主机的文件系统。
解决-->容器镜像的引入
我们可以在容器进程启动之前重新挂载它的整个根目录“/”。而由于 Mount Namespace 的存在,这个挂载对宿主机不可见,所以容器进程就可以在里面随便折腾了。
一般,我们会在容器的根目录下挂载一个完整操作系统的文件系统,比如 Ubuntu16.04 的 ISO。这样,在容器启动之后,我们在容器里通过执行 "ls /" 查看根目录下的内容,就是 Ubuntu 16.04 的所有目录和文件。而这个挂载在容器根目录上、用来为容器进程提供隔离后执行环境的文件系统,就是所谓的“容器镜像”。它还有一个更为专业的名字,叫作:rootfs(根文件系统)。所以,一个最常见的 rootfs,或者说容器镜像,会包括如下所示的一些目录和文件,比如 /bin,/etc,/proc 等等。而进入容器之后执行的 /bin/bash,就是 /bin 目录下的可执行文件,与宿主机的 /bin/bash 完全不同。
注意:rootfs 只是一个操作系统所包含的文件、配置和目录,并不包括操作系统内核。在 Linux 操作系统中,这两部分是分开存放的,操作系统只有在开机启动时才会加载指定版本的内核镜像。
容器的一致性
由于 rootfs 里打包的不只是应用,而是整个操作系统的文件和目录,也就意味着,应用以及它运行所需要的所有依赖,都被封装在了一起。有了容器镜像“打包操作系统”的能力,操作系统这个运行应用最基础的依赖环境也终于变成了应用沙盒的一部分。
这就赋予了容器所谓的一致性:无论在本地、云端,还是在一台任何地方的机器上,用户只需要解压打包好的容器镜像,那么这个应用运行所需要的完整的执行环境就被重现出来了。这种深入到操作系统级别的运行环境一致性,打通了应用在本地开发和远端执行环境之间难以逾越的鸿沟。
问题:难道每开发一个应用,或者升级一下现有的应用,都要重复制作一次 rootfs 吗?
解决-->分层镜像设计:
Docker 在镜像的设计中,引入了层(layer)的概念。也就是说,用户制作镜像的每一步操作,都会生成一个层,也就是一个增量 rootfs。这样,所有人都只需要维护相对于 base rootfs 修改的增量内容,而不用重复制作 rootfs。这里,用到了一种叫作联合文件系统(Union File System)的能力。
联合文件系统(Union File System)
Union File System 也叫 UnionFS,最主要的功能是将多个不同位置的目录联合挂载(union mount)到同一个目录下。比如,现在有两个目录 A 和 B,它们分别有两个文件:
$ tree
.
├── A
│ ├── a
│ └── x
└── B
├── b
└── x
然后,使用联合挂载的方式,将这两个目录挂载到一个公共的目录 C 上:
$ mkdir C
$ mount -t aufs -o dirs=./A:./B none ./C
这时,再查看目录 C 的内容,就能看到目录 A 和 B 下的文件被合并到了一起:
$ tree ./C
./C
├── a
├── b
└── x
可以看到,在这个合并后的目录 C 里,有 a、b、x 三个文件,并且 x 文件只有一份。这,就是“合并”的含义。此外,如果你在目录 C 里对 a、b、x 文件做修改,这些修改也会在对应的目录 A、B 中生效。
容器的roofs分层结构
容器的roofs分层结构如下图所示:
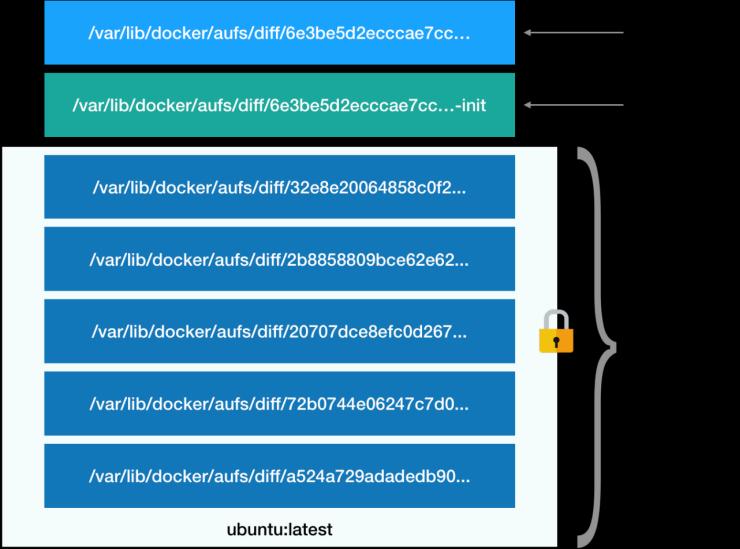
- 只读层:挂载方式:只读(ro+wh,即 readonly+whiteout)。这些层,都以增量的方式分别包含了 Ubuntu 操作系统的一部分。
- 可读写层:挂载方式为:rw,即 read write。在没有写入文件之前,这个目录是空的。而一旦在容器里做了写操作,修改产生的内容就会以增量的方式出现在这个层中。也就是说,只读写层的作用是:专门用来存放你修改 rootfs 后产生的增量,无论是增、删、改,都发生在这里。
- Init层:Init 层是 Docker 项目单独生成的一个内部层,专门用来存放 /etc/hosts、/etc/resolv.conf 等信息。init 层的作用是:存放容器在运行时修改过的配置文件,这些配置仅对当前容器有效,因此 docker commit 时不会随同读写层一起提交。
上面的读写层通常也称为容器层,下面的只读层称为镜像层,所有的增删查改操作都只会作用在容器层,相同的文件上层会覆盖掉下层。比如修改一个文件的时候,首先会从上到下查找有没有这个文件,找到,就复制到容器层中,修改,那么修改的结果就会作用到下层的文件,这种方式也被称为copy-on-write。
小结
- 对 Docker 项目来说,它最核心的原理实际上就是为待创建的用户进程:
启用 Linux Namespace 配置;
设置指定的 Cgroups 参数;
切换进程的根目录(Change Root)。
- Linux 容器文件系统的实现方式——容器镜像(rootfs)。
通过结合使用 Mount Namespace 和 rootfs,容器就能够为进程构建出一个完善的文件系统隔离环境。在 rootfs 的基础上,Docker 公司创新性地提出了使用多个增量 rootfs 联合挂载一个完整 rootfs 的方案,这就是容器镜像中“层”的概念。通过“分层镜像”的设计,以 Docker 镜像为核心,来自不同公司、不同团队的技术人员被紧密地联系在了一起。
四、重新认识Docker容器
常用命令与原理分析
常用命令
// docker build 制作镜像
// docker image 查看镜像
// docker run 启动容器
$ docker run -p 4000:80 helloworld
注:如果DockerFile中未指定CMD,则需要把进程启动命令加在后面:
$ docker run -p 4000:80 helloworld python app.py
// 其中,通过 -p 4000:80 告诉Docker,请把容器内的 80 端口映射在宿主机的 4000 端口上
// docker ps 查看进程
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED
4ddf4638572d helloworld "python app.py" 10 seconds ago
// docker tag 给容器镜像起一个完整的名字 如:
$ docker tag helloworld geektime/helloworld:v1
// docker push 把镜像上传到Docker Hub上
$ docker push geektime/helloworld:v1
// docker exec 进入容器 如:
$ docker exec -it 4ddf4638572d /bin/sh
// 进入容器后可以进行一些操作,如:
# 在容器内部新建了一个文件
root@4ddf4638572d:/app# touch test.txt
root@4ddf4638572d:/app# exit
// dockers commit 容器提交为镜像
$ docker commit 4ddf4638572d geektime/helloworld:v2
// docker run --net 启动一个容器并“加入”到另一个容器的 Network Namespace 里
$ docker run -it --net container:4ddf4638572d busybox ifconfig
(新启动的这个容器,就会直接加入到 ID=4ddf4638572d 的容器)
问题:docker exec 是怎么做到进入容器里的呢?——docker exec的实现原理
Linux Namespace 创建的隔离空间虽然看不见摸不着,但一个进程的 Namespace 信息在宿主机上是确确实实存在的,并且是以一个文件的方式存在。一个进程的每种 Linux Namespace,都在它对应的 /proc/[进程号]/ns 下有一个对应的虚拟文件,并且链接到一个真实的 Namespace 文件上。因此,一个进程,可以选择加入到某个进程已有的 Namespace 当中,从而达到“进入”这个进程所在容器的目的,这正是 docker exec 的实现原理:使用系统调用setns,让新启动的进程与容器共享多种namespace。
如果指定--net=host,就意味着这个容器不会为进程启用 Network Namespace。这就意味着,这个容器拆除了 Network Namespace 的“隔离墙”,所以,它会和宿主机上的其他普通进程一样,直接共享宿主机的网络栈。这就为容器直接操作和使用宿主机网络提供了一个渠道。
docker commit 的原理
docker commit,实际上就是在容器运行起来后,把最上层的“可读写层”,加上原先容器镜像的只读层,打包组成了一个新的镜像。当然,下面这些只读层在宿主机上是共享的,不会占用额外的空间。而由于使用了联合文件系统,你在容器里对镜像 rootfs 所做的任何修改,都会被操作系统先复制到这个可读写层,然后再修改。这就是所谓的:Copy-on-Write。Init 层的存在,就是为了避免你执行 docker commit 时,把 Docker 自己对 /etc/hosts 等文件做的修改,也一起提交掉。
Docker Volume 容器数据卷
容器技术使用了 rootfs 机制和 Mount Namespace,构建出了一个同宿主机完全隔离开的文件系统环境。这时候,我们就需要考虑这样两个问题:
- 容器里进程新建的文件,怎么才能让宿主机获取到?
- 宿主机上的文件和目录,怎么才能让容器里的进程访问到?
这正是 Docker Volume 要解决的问题:Volume 机制,允许你将宿主机上指定的目录或者文件,挂载到容器里面进行读取和修改操作。
Docker 项目中支持的两种 Volume 声明方式,可以把宿主机目录挂载进容器的 /test 目录当中:
$ docker run -v /test ...
$ docker run -v /home:/test ...
在第一种情况下,由于并没有显示声明宿主机目录,那么 Docker 就会默认在宿主机上创建一个临时目录 /var/lib/docker/volumes/[VOLUME_ID]/_data,然后把它挂载到容器的 /test 目录上。而在第二种情况下,Docker 就直接把宿主机的 /home 目录挂载到容器的 /test 目录上。
Docker 如何把一个宿主机上的目录或者文件,挂载到容器里面呢?
当容器进程被创建之后,尽管开启了 Mount Namespace,但是在它执行 chroot(或者 pivot_root)之前,容器进程一直可以看到宿主机上的整个文件系统。而宿主机上的文件系统,也自然包括了我们要使用的容器镜像。这个镜像的各个层,保存在 /var/lib/docker/aufs/diff 目录下,在容器进程启动后,它们会被联合挂载在 /var/lib/docker/aufs/mnt/ 目录中,这样容器所需的 rootfs 就准备好了。所以,我们只需要在 rootfs 准备好之后,在执行 chroot 之前,把 Volume 指定的宿主机目录(比如 /home 目录),挂载到指定的容器目录(比如 /test 目录)在宿主机上对应的目录(即 /var/lib/docker/aufs/mnt/[可读写层 ID]/test)上,这个 Volume 的挂载工作就完成了。更重要的是,由于执行这个挂载操作时,“容器进程”已经创建了,也就意味着此时 Mount Namespace 已经开启了。所以,这个挂载事件只在这个容器里可见。你在宿主机上,是看不见容器内部的这个挂载点的。这就保证了容器的隔离性不会被 Volume 打破。这里要使用到的挂载技术,就是 Linux 的绑定挂载(bind mount)机制。
Linux 的绑定挂载(bind mount)机制
它的主要作用就是,允许你将一个目录或者文件,而不是整个设备,挂载到一个指定的目录上。并且,这时你在该挂载点上进行的任何操作,只是发生在被挂载的目录或者文件上,而原挂载点的内容则会被隐藏起来且不受影响。绑定挂载实际上是一个 inode 替换的过程。在 Linux 操作系统中,inode 可以理解为存放文件内容的“对象”,而 dentry,也叫目录项,就是访问这个 inode 所使用的“指针”。如图所示:

mount --bind /home /test,会将 /home 挂载到 /test 上。其实相当于将 /test 的 dentry,重定向到了 /home 的 inode。这样当我们修改 /test 目录时,实际修改的是 /home 目录的 inode。这也就是为何,一旦执行 umount 命令,/test 目录原先的内容就会恢复:因为修改真正发生在的,是 /home 目录里。
同时,执行docker commit不会把挂载过的目录打包。由于容器的镜像操作,比如 docker commit,都是发生在宿主机空间的。而 Mount Namespace 的隔离作用,使宿主机并不知道这个绑定挂载的存在。所以,在宿主机看来,容器中可读写层的 /test 目录(/var/lib/docker/aufs/mnt/[可读写层 ID]/test),始终是空的。
小结
- Docker 容器全景图:
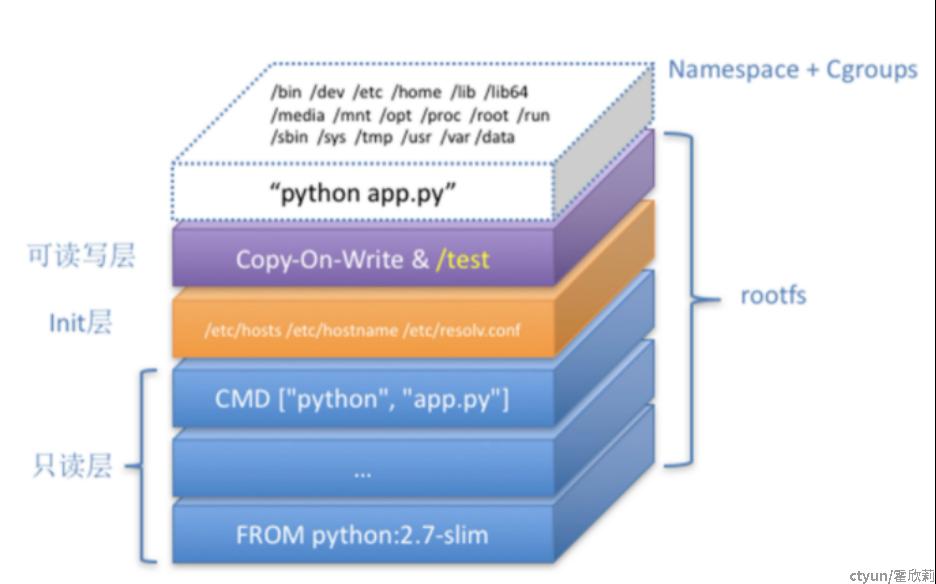
这个容器进程“python app.py”,运行在由 Linux Namespace 和 Cgroups 构成的隔离环境里;而它运行所需要的各种文件,比如 python,app.py,以及整个操作系统文件,则由多个联合挂载在一起的 rootfs 层提供。这些 rootfs 层的最下层,是来自 Docker 镜像的只读层。在只读层之上,是 Docker 自己添加的 Init 层,用来存放被临时修改过的 /etc/hosts 等文件。而 rootfs 的最上层是一个可读写层,它以 Copy-on-Write 的方式存放任何对只读层的修改,容器声明的 Volume 的挂载点,也出现在这一层。
五、谈谈Kubernetes的本质
容器核心知识
一个“容器”,实际上是一个由 Linux Namespace、Linux Cgroups 和 rootfs 三种技术构建出来的进程的隔离环境。一个正在运行的 Linux 容器,其实可以被“一分为二”地看待:
- 一组联合挂载在 /var/lib/docker/aufs/mnt 上的 rootfs,这一部分我们称为“容器镜像”(Container Image),是容器的静态视图;
- 一个由 Namespace+Cgroups 构成的隔离环境,这一部分我们称为“容器运行时”(Container Runtime),是容器的动态视图。
在整个“开发 - 测试 - 发布”的流程中,真正承载着容器信息进行传递的,是容器镜像,而不是容器运行时。Kubernetes 项目没有像同时期的各种“容器云”项目那样,把 Docker 作为整个架构的核心,而仅仅把它作为最底层的一个容器运行时实现(docker 镜像只是相当于新的一种应用打包方式)。
Kubernetes 项目架构
Kubernetes 项目要解决的问题是什么?---- 如何编排、管理、调度用户提交的作业?
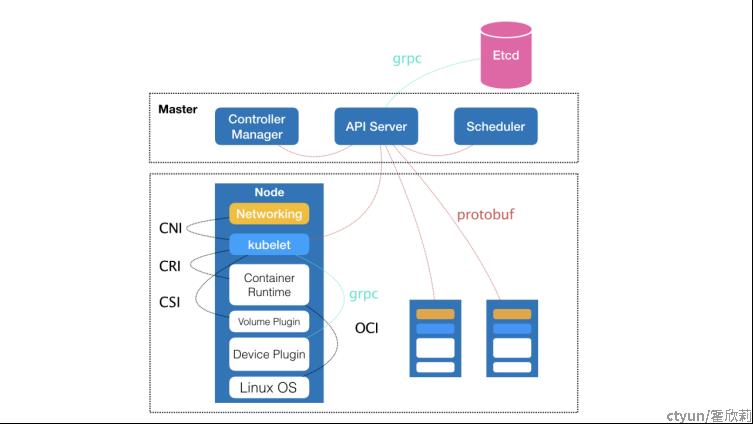
Kubernetes 项目的架构,由 Master 和 Node 两种节点组成,而这两种角色分别对应着控制节点和计算节点。
其中,控制节点,即 Master 节点,由三个紧密协作的独立组件组合而成,它们分别是负责 API 服务的 kube-apiserver、负责调度的 kube-scheduler,以及负责容器编排的 kube-controller-manager。整个集群的持久化数据,则由 kube-apiserver 处理后保存在 Etcd 中。
计算节点上最核心的部分,是一个叫作 kubelet 的组件。在 Kubernetes 项目中,kubelet 主要负责同容器运行时(比如 Docker 项目)打交道。而这个交互所依赖的,是一个称作 CRI(Container Runtime Interface)的远程调用接口,这个接口定义了容器运行时的各项核心操作,比如:启动一个容器需要的所有参数。因此,Kubernetes 项目并不关心你部署的是什么容器运行时、使用的什么技术实现,只要你的这个容器运行时能够运行标准的容器镜像,它就可以通过实现 CRI 接入到 Kubernetes 项目当中。而具体的容器运行时,比如 Docker 项目,则一般通过 OCI 这个容器运行时规范同底层的 Linux 操作系统进行交互,即:把 CRI 请求翻译成对 Linux 操作系统的调用(操作 Linux Namespace 和 Cgroups 等)。
此外,kubelet 还通过 gRPC 协议同一个叫作 Device Plugin 的插件进行交互。这个插件,是 Kubernetes 项目用来管理 GPU 等宿主机物理设备的主要组件,也是基于 Kubernetes 项目进行机器学习训练、高性能作业支持等工作必须关注的功能。而 kubelet 的另一个重要功能,则是调用网络插件和存储插件为容器配置网络和持久化存储。这两个插件与 kubelet 进行交互的接口,分别是 CNI(Container Networking Interface)和 CSI(Container Storage Interface)。
Kubernetes 项目要着重解决的问题:运行在大规模集群中的各种任务之间,实际上存在着各种各样的关系。这些关系的处理,才是作业编排和管理系统最困难的地方。
Kubernetes设计思想
两个关键问题:
- 应用与应用之间的关系
- 应用运行的形态
Kubernetes 项目最主要的设计思想是,从更宏观的角度,以统一的方式来定义任务之间的各种关系,并且为将来支持更多种类的关系留有余地。
比如,Kubernetes 项目对容器间的“访问”进行了分类,首先总结出了一类非常常见的“紧密交互”的关系,即:这些应用之间需要非常频繁的交互和访问;又或者,它们会直接通过本地文件进行信息交换。对于紧密交互的容器,kubernetes会将他们划分到同一个pod里面,Pod 里的容器共享同一个 Network Namespace、同一组数据卷,从而达到高效率交换信息的目的。
Pod 是 Kubernetes 项目中最基础的一个对象。
而对于另外一种更为常见的关系,比如 Web 应用与数据库之间的访问关系,Kubernetes 项目则提供了一种叫作“Service”的服务。对于一个容器来说,它的 IP 地址等信息不是固定的,那么 Web 应用又怎么找到数据库容器的 Pod 呢?Kubernetes 项目的做法是给 Pod 绑定一个 Service 服务,而 Service 服务声明的 IP 地址等信息是“终生不变”的。这个 Service 服务的主要作用,就是作为 Pod 的代理入口(Portal),从而代替 Pod 对外暴露一个固定的网络地址。这样,对于 Web 应用的 Pod 来说,它需要关心的就是数据库 Pod 的 Service 信息。不难想象,Service 后端真正代理的 Pod 的 IP 地址、端口等信息的自动更新、维护,则是 Kubernetes 项目的职责。
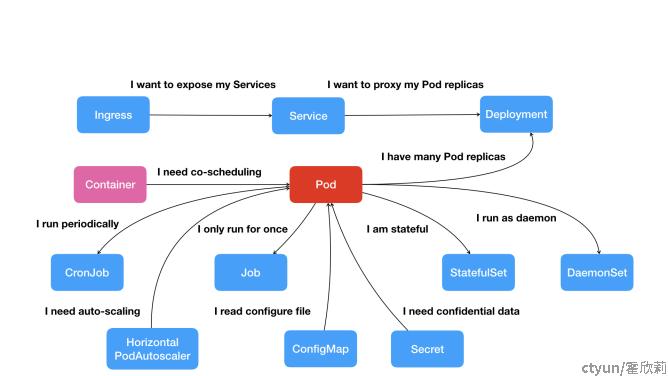
按照上面这幅图的线索,我们从容器这个最基础的概念出发,首先遇到了容器间“紧密协作”关系的难题,于是就扩展到了 Pod;有了 Pod 之后,我们希望能一次启动多个应用的实例,这样就需要 Deployment 这个 Pod 的多实例管理器;而有了这样一组相同的 Pod 后,我们又需要通过一个固定的 IP 地址和端口以负载均衡的方式访问它,于是就有了 Service。
可是,如果现在两个不同 Pod 之间不仅有“访问关系”,还要求在发起时加上授权信息。最典型的例子就是 Web 应用对数据库访问时需要 Credential(数据库的用户名和密码)信息。那么,在 Kubernetes 中这样的关系又如何处理呢?Kubernetes 项目提供了一种叫作 Secret 的对象,它其实是一个保存在 Etcd 里的键值对数据。这样,你把 Credential 信息以 Secret 的方式存在 Etcd 里,Kubernetes 就会在你指定的 Pod(比如,Web 应用的 Pod)启动时,自动把 Secret 里的数据以 Volume 的方式挂载到容器里。这样,这个 Web 应用就可以访问数据库了。
除了应用与应用之间的关系外,应用运行的形态是影响“如何容器化这个应用”的第二个重要因素。为此,Kubernetes 定义了新的、基于 Pod 改进后的对象。比如 Job,用来描述一次性运行的 Pod(比如,大数据任务);再比如 DaemonSet,用来描述每个宿主机上必须且只能运行一个副本的守护进程服务;又比如 CronJob,则用于描述定时任务等等。如此种种,正是 Kubernetes 项目定义容器间关系和形态的主要方法。
可以看到,在 Kubernetes 项目中:
- 首先,通过一个“编排对象”,比如 Pod、Job、CronJob 等,来描述你试图管理的应用;
- 然后,再为它定义一些“服务对象”,比如 Service、Secret、Horizontal Pod Autoscaler(自动水平扩展器)等。这些对象,会负责具体的平台级功能。
这种方法,就是所谓的“声明式 API”。这种 API 对应的“编排对象”和“服务对象”,都是 Kubernetes 项目中的 API 对象(API Object)。这就是 Kubernetes 最核心的设计理念。
小结
- Kubernetes 项目架构的设计思想:使用“声明式 API”来描述容器化业务和容器间关系。
过去很多的集群管理项目(比如 Yarn、Mesos,以及 Swarm)所擅长的,都是把一个容器,按照某种规则,放置在某个最佳节点上运行起来。这种功能,我们称为“调度”。而 Kubernetes 项目所擅长的,是按照用户的意愿和整个系统的规则,完全自动化地处理好容器之间的各种关系。这种功能,就是我们经常听到的一个概念:编排。所以说,Kubernetes 项目的本质,是为用户提供一个具有普遍意义的容器编排工具。
