1. 需求
业务会产生海量的数据时,就需要高效数据管理策略,尤其是如何存储和维护这些海量的数据。对于如何存储和维护这些海量的数量,那么就需要对其做一个界限的划分,通常可以用冷、热的分层数据存储服务描述。
冷和热主要是根据数据对业务的重要性以及访问频率来决定了,经常需要访问查询的数据,表明是热点数据,需要存储在容易“快速查询”的区域,而对于那些不常访问的数据,可能半个月甚至是一两个月都用不到的数据(具体视业务而定),表明是冷数据,可以存储在磁盘。划分的目的是不占用热点数据的区域,加快数据的查询,那么如何实现冷热数据的存储设计是非常重要的。
2. 总体架构
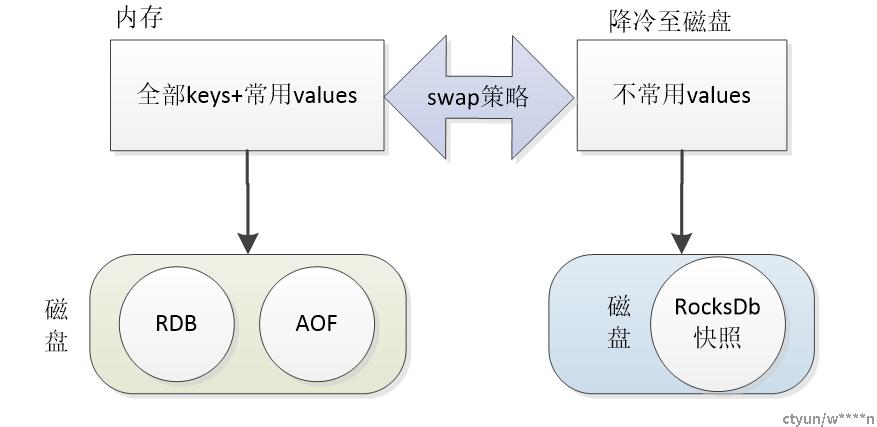
总结架构设计如图1所示,access作为代理层,接受来自客户端的请求,redis集群存储热数据,其中RocksDb为针对KV数据存储的高性能嵌入式数据库,内核数据结构基于LSM树实现的,LSM结构树的特点是: 写入速度快,读取速度慢。(阿里混合存储和腾讯云Tendis也是采用RocksDb作为底层存储引擎)

图1 缓存冷热存储架构设计
3. 存储模型
全量总数据=内存(全量keys+热values)+磁盘(冷values)
4. 线程模型
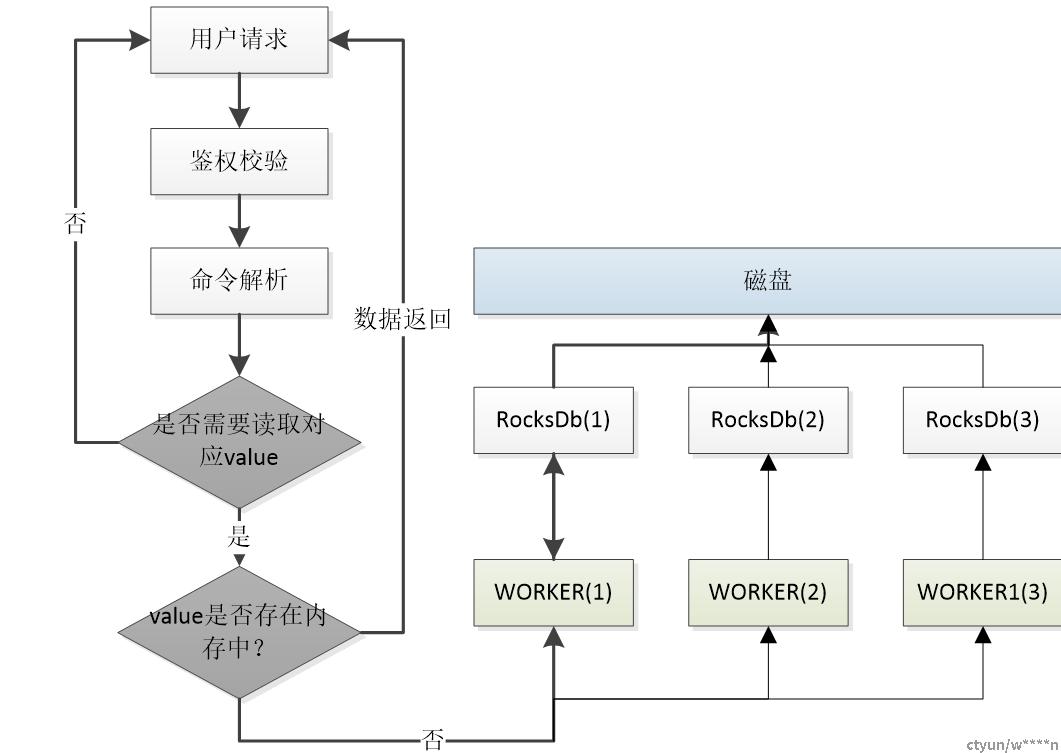
使用单IO+多WORKER模型
单IO: 单线程,负责处理用户请求、socket数据解析等。
多Worker: 多个独立的IO线程负责与磁盘进行交互读写数据,IO线程读写数据时,主线程仍可继续响应其它用户请求。
与redis6.0的模型差别:
redis6.0采用多IO+单worker模型。
多IO:读写socket、命令解析使用多线程。
单worker:执行命令请求使用master单线程。
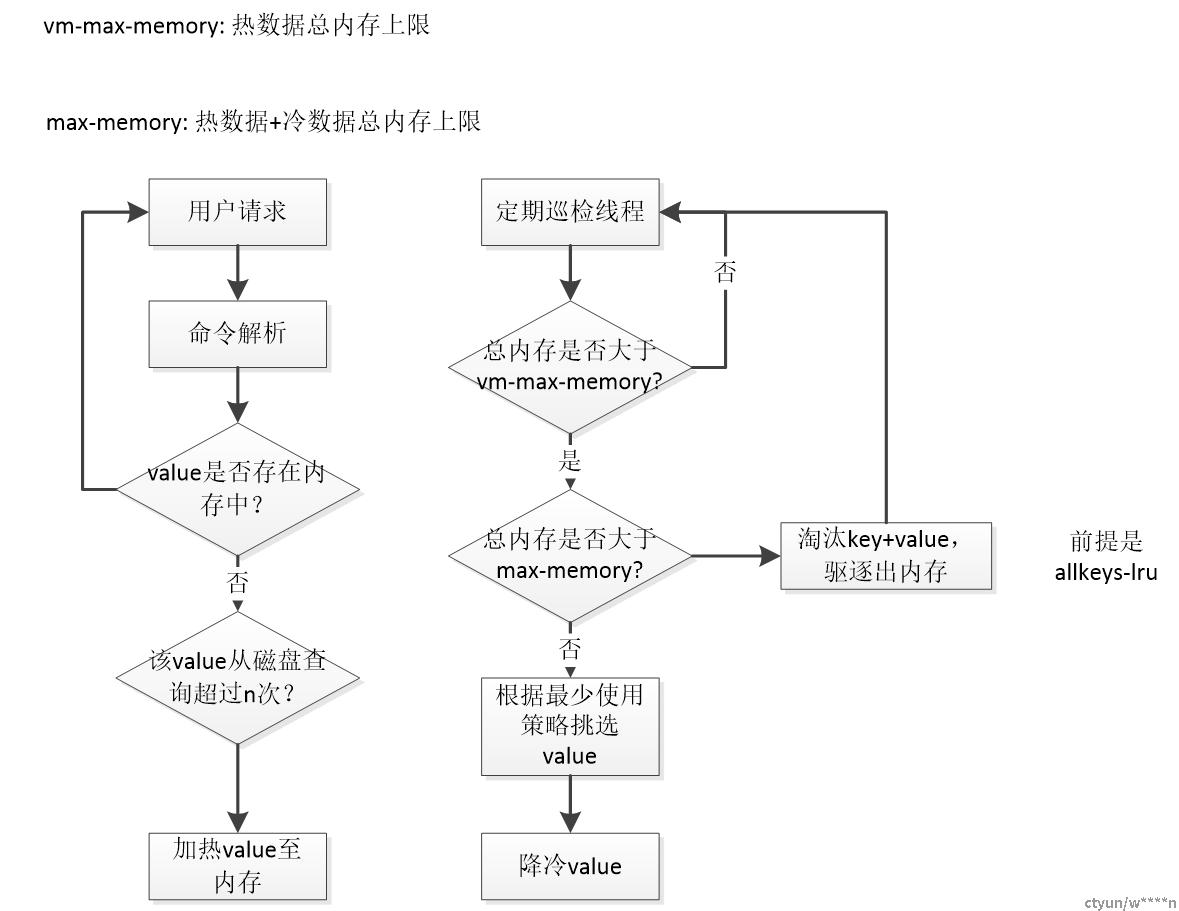
5. 数据降冷、预热策略