诊断服务端报错问题
问题描述
网页抛错,尤其是5xx错误是互联网应用最常见的问题之一。5xx错误通常发生于服务端。服务端是业务逻辑最复杂,也是整条网络请求链路中最容易出错、出了错之后最难诊断原因的地方。运维工程师或研发工程师往往需要登录机器查看日志来定位问题。
对于逻辑不太复杂、上线时间不长的应用来说,登录机器查看日志的方式能够解决大部分网站抛错的问题。但在以下场景中,传统的问题诊断方式往往没有用武之地。
- 在一个分布式应用集群中,需知道某一类错误的发生时间和频率。
- 某系统已运行了很长时间,但是不想关心遗留的异常,只想知道今天和昨天相比、发布后和发布前相比多了哪些异常。
- 查看一个异常对应的Web请求和相关参数。
- 客服人员提供了一个用户下单失败的订单号,分析该用户下单失败的原因。
解决方案
为应用安装APM探针后,即可在不改动应用代码的情况下,利用应用性能监控的异常自动捕捉、收集、统计和溯源等能力,全面掌握应用的各种错误信息。
步骤一:安装APM探针
为应用安装APM探针后,才能对应用进行全方位监控。请根据实际需求选择一种方式来安装探针。
步骤二:查看关于应用异常的统计信息
为应用安装APM探针后,APM会收集和展示选定时间内应用的总请求量、平均响应时间、错误数、实时实例数、FullGC次数、慢SQL次数、异常次数和慢调用次数,以及这些指标和上一天的环比、上周的同比升降幅度。请按以下步骤查看应用异常的统计信息。
-
在应用总览页面的概览页签下方,查看异常的总数、周同比和日同比数据,如下图所示。

-
滑动页面至概览页签底部的统计分析区域的异常类型,查看各类型异常出现的次数,如下图所示。
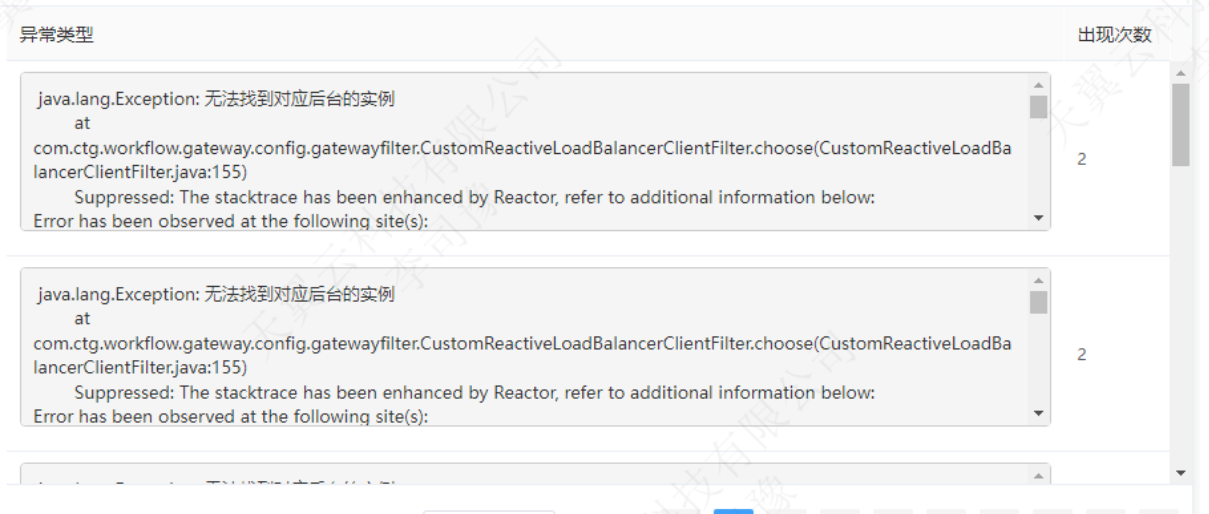
-
在左侧导航栏,点击监控 > 实例监控,然后在页面右侧单击异常分析页签,查看异常统计图、错误数、异常堆栈等,如下图所示。
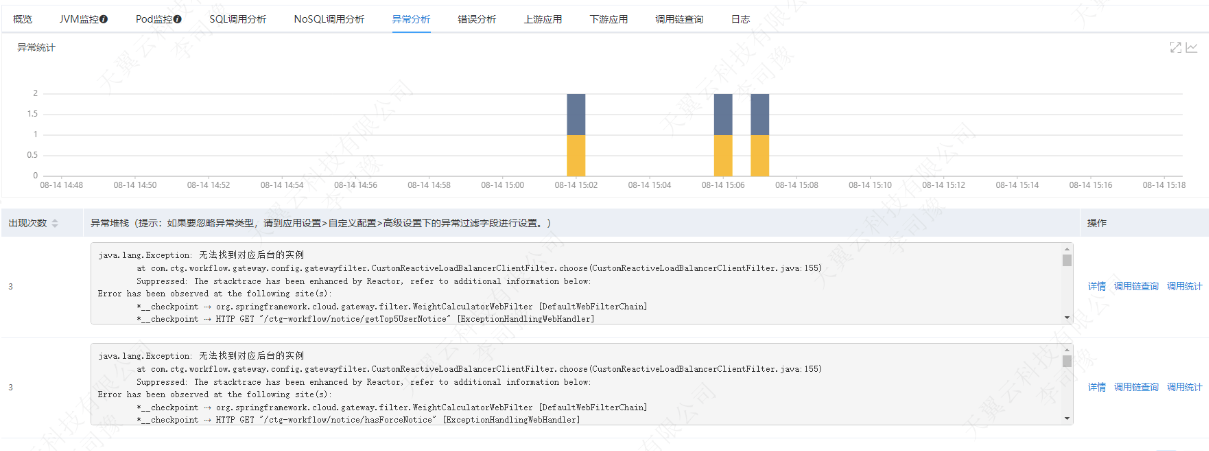
步骤三:诊断异常出现的原因
掌握应用异常的统计信息还不足以诊断异常出现的原因。虽然日志中异常堆栈包含调用的代码片段,但并不包含这次调用的完整上下游信息和请求参数。APM探针采用了字节码增强技术,让您能够以很小的性能消耗捕获异常上下游的完整调用快照,进而找出导致异常出现的具体原因。
-
在异常分析页签下,找到要诊断的异常类型,在其右侧操作列,单击调用链查询。调用链查询页签下显示与该异常类型相关的调用链路信息,如下图所示。

-
在调用链查询页签下,单击某个错误调用的TraceId,如下图所示。

-
在弹出的页面,查看异常的调用链路信息。
操作至此,您已发现了应用异常的原因,这将有效地帮助您进行下一步的代码优化工作。您还可以返回调用链查询页签,查看列表中其他异常,逐一解决。

